Discussion about Fine Tuning on a different language. #147
Labels
No Label
bug
duplicate
enhancement
help wanted
insufficient info
invalid
news
not a bug
question
wontfix
No Milestone
No project
No Assignees
6 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: mrq/ai-voice-cloning#147
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Hello everyone,
I know that there are other issues on fine-tuning Tortoise for different languages, but I think it would be helpful to have a centralized discussion to gather and share findings and useful information, possibly building a guide for future reference.
Although I haven't yet tried fine-tuning Tortoise for my language, which is Italian, I've read that it's possible with other languages.
Based on what I read, the following steps are needed or recommended when fine-tuning for a new language:
It would be great to expand the discussion to understand why these steps are necessary, which tokenizers have produced good or bad results, what are the characteristics the tokenizer needs to satisfy etc...
In your opinion and experience, what else can be beneficial when fine-tuning for a new language?
Some possible questions to consider include:
Then a more general question: which other models, aside from the AR model, should be fine-tuned to achieve better results?
Yeah, there's a French model floating around, which I'm surprised as it was one of the earlier finetunes I've seen. I can't vouch for how well it is, as I haven't used it myself yet, but ironically, if it was trained with the other DLAS fork, then it should be good.
I've had my Japanese finetunes that proved to vary from unfavorable to decent, but those stem from other issues I've since resolved.
As things currently stand, you have to really be careful of how you go about it, as it's been a major pain in my ass to wrangle.
I imagine you'll get more benefit replacing the lesser-used tokens at the end with what you want: more than likely, extra symbols and combination of tokens (merges).
There's also the issue of both DLAS and TorToiSe pre-processing your text to normalize it by cleaning it up up and ASCII-izing anything, so be wary of that, and if you need it disabled, you can set the
pre-tokenizertonull.Apparently it's doable, and I imagine those people did the above and not what I did and completely replaced the tokenizer.
This definitely, as, even without the tokenizer, you're effectively rewriting the sequences of tokens (virtual phonemes), and with a new tokenizer, you're rewriting what those tokens (virtual phonemes) mean.
For languages, you could reduce the mel LR ratio if you wish to try and retain the variety of the base model, but I haven't seemed to got it to happen, as my mel LR ratio still seemed too high with setting it to 0.01 (which makes sense, it's just making the LR go from 1e-5 to 1e-7).
I've got decent Japanese without slotting out the tokenizer, and the French one most definitely uses the default one. It's decent for Japanese, and it'll most definitely be fine for Italian, but my issues come from:
言わんこっちゃない=>['y', 'an', '[SPACE]', 'w', 'an', 'k', 'o', 't', 'su', 'ch', 'i', 'y', 'an', 'a', 'i'], where:'k', 'o'should be'ko')'w', 'an'should be'wa', 'n')But technically you can just bruteforce the merge problem (as the GPT model will "know" a sequence of tokens will map to a sequence of phonemes). The harmful problem stems from the ASCII-izing (romanizing), which a tokenizer vocab could replace wholesale, but would be quite the pain to define.
As I said though, it shouldn't be an issue for common languages. Training can easily bruteforce inaccurate merges fine. For non-latin languages, just don't expect it to be pretty, and validate with the
Utilities>Tokenizertab (for Italian, should be fine).You can also just do away with the
mergesarray entirely and let the GPT model figure out merges. I think my latest training did that, but I'll have to scrap it due to it ASCII-izing/romanizing kanji wrong.Hard to say a minimum, as you'll always benefit from more data. I've got something that works with repeating anything from the training dataset (and naturally had issues from any Japanese outside of the dataset) from one voice in 10 lines, and I've got a handful of tests from a dataset of 7.5k, and another with 15.5k lines, both with about ~60 different speakers? But I felt the range wasn't decent, but that could just be because it's from a gacha and lines are not necessarily delivered normally, or that I didn't reduce the mel LR ratio (which I don't care, I was needing it to finetune for specific voices anyways).
Fuck if I remember specifically, I think my latest shot was:
[2, 4, 9, 18, ...]Just the AR needs finetuning.
Did you convert all the Kanji in your training set to Hiragana beforehand or leave as is?
How much did that cost?
My naivety left it in as-is, and had whatever DLAS/tortoise uses handle it (which seem to be unidecode). I probably should have validated more, but naturally, hindsight is 20/20.
I'm experimenting with a preprocessor that will parse
Japanese string=>kana(hirgana/katakana are practically interchangeable), and let the tokenizer vocab handle kana. Some issues:X ゃmerges.The preprocessing will tie to a
model.languageentry (justlanguagein the JSON wil make the tokenizer throw a hissy), so in theory you can further expand with additional per-language preprocessing.Paperspace has some "free" ones with the $40/month growth tier, but availability is pretty much up to chance (I refuse to pay by the hour). As much as I hate Paperspace, I gotta do what I gotta do for experiments. There just isn't an actual equivalent to Paperspace that I'm aware of.
Do the "Prompt Engineering" options still work with the Japanese model or do you have to substitute something like[僕はとても幸せです、]?
I don't know, and desu I don't care too much to find out if it does.
From a cursory auditing, and my limited knowledge on how text redaction works ("""prompt engineering""" is a silly name that I don't know why I even called it that), it doesn't care about the tokenizer at all, as that lives within the realm of the AR, while text redaction relies on the wav2vec2 model, which is in it's own bubble of working with non-English.
In other words, try it and find out, because it's an issue left up to how well the default wav2vec2 model handles things.
Trained a new model with the Japanese tokenizer, and after ~55 epochs (~825000 samples processed), I have a better Japanese model:
However, it needs to be finetuned for a specific voice, it's multi-voice capabilities are terrible, and it'll have a dreadful issue where you need punctuation so it "knows" when a sentence stops, or it'll keep generating extraneous words (example 1).
But I'm happy with it. There doesn't seem to be any actual lingual quirks, so a replaced tokenizer can work, but it seems it needs twice the training time over normally training with the default tokenizer (naturally). I'll add it to my HF repo in a moment.
Was it with VALL-E or DLAS?
What effect does
"language": "ja",in the japanese.json have?DLAS.
Hints to both DLAS's tokenizer and tortoise's tokenizer to properly process the text for the tokenizer, instead of relying on the default pathway that ASCII-fies it by poorly romanizing the text.
Well, that explains why all my attempts at IPA tokenization failed.
Thank you very much for the extended response, I've tried training with an italian dataset, with Text LR Ratio to 1 and with no change to the tokenizer.
The results are decent but there is a very strange accent to it unfortunately.
I have finetuned a model for Cantonese, a tonal language, like Mandarin. I also tried to mix it with english.
Cantonese
https://soundcloud.com/keith-hon/0a-2?si=1ac3624677c041de964ae85ced07d783&utm_source=clipboard&utm_medium=text&utm_campaign=social_sharing
Cantonese + English
https://soundcloud.com/keith-hon/cantonese-english-mixed-tts-with-voice-clone
which sounds decent in my opinon. However, I will need to train a custom CLVP model to pick the best outputs from the diffusion model.
I plan to mix with other asian languages as well.
I'd love a spanish model ... I wouldn't find anything about this yet. Only a little in Bark.
@mrq hello, may I ask you, are you sure that those 825000 samples weren't actually just 82500 samples? Because I'm training mine 500k samples on 3090RTX and one epoch takes about 15 hours, so those 800k samples would take more than 24 hours/per epoch and 55 epochs would take more than 2 months on any average consumer GPU...
Otherwise I agree it's impossible to get multi-voice capabilities and one needs to finetune to specific voice...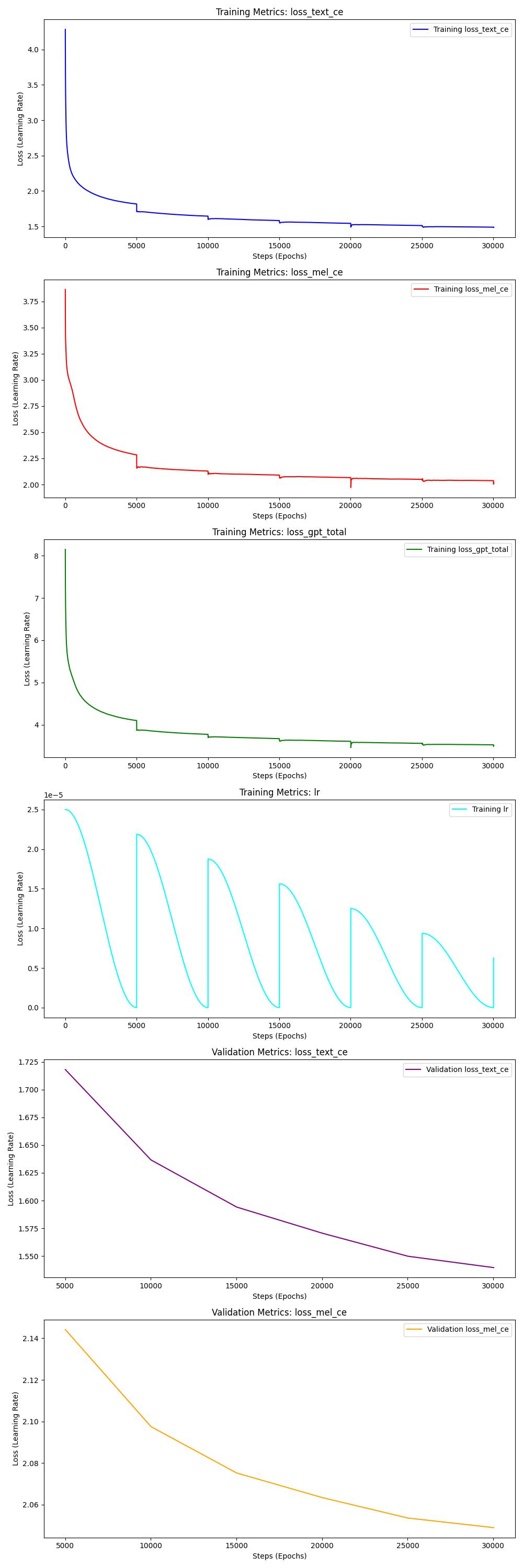 I am also including my training metrics, maybe it helps someone trying to finetune the model on new language. The results are surprisingly good.
I am also including my training metrics, maybe it helps someone trying to finetune the model on new language. The results are surprisingly good.