VALL-E Integration (and In Response To TorToiSe: a Quick Retrospective) #152
Labels
No Label
bug
duplicate
enhancement
help wanted
insufficient info
invalid
news
not a bug
question
wontfix
No Milestone
No project
No Assignees
27 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: mrq/ai-voice-cloning#152
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
As I may have hinted with my not-so-subtle commits, I'm working towards getting VALL-E integrated as an alternative TTS backend:
--tts-backend="vall-e"I'm backing this implementation as my VALL-E implementation:
The training process is pretty intuitive too:
However, I have some qualms with it so far:
And other concerns with VALL-E:
As for my thoughts on TorToiSe after everything from this being a silly rentry to using it, to now:
Above all, I just hope VALL-E proves to be my magic cure-all and I can just set up a machine to train LJSpeech or a reduced LibriTTS dataset, and come back to it after quite some time passed to get a good model. I honestly don't know how much steam I have left in me.
tl;dr: VALL-E soon, stay tuned.
How bad is it? Is it still something that could run on HEDT graphics cards or should I be pricing out refab P40's on eBay?
Edit: Should rerunning setup-cuda.sh be sufficient to pull in whatever's required for VALL-E?
My batch size is pretty much pinned to 16 for my 2x6800XTs (2x16GiB) if I want stability. Granted, distributed training is different from DLAS, where DLAS will take your batch size and divide by GPU count, but DeepSpeed will use the batch size per GPU. I'm not sure of the bare minimum requirement, though.
Also, you can train half/quarter sized models with reduced parameters by specifing
-halfand-quarterin the model name (soar-half/nar-quarter) for reduced VRAM requirements.Small improvement, but if you've already committed to relying on
phonemizerthen using it to generate the IPA vocab list from the training dataset is near trivial:Edit: In the majority of cases
phonemizeris just acting as a wrapper for libespeak-ng so you could just call espeak_TextToPhonemes() yourself if you wanted.Your doing a amazing job. This mainly beyond my understanding but it's impressive stuff. Do you have a donation page or something?
I've tried training unofficial enhuiz Vall-E implementation but with my resources I wasn't going anywhere unfortunately, so I gave up.
Have you got any success in training it?
I think that it is a shame though to abandon Tortoise, I've been experimenting with lots of TTS in these past months and the quality of Tortoise is the best to me.
It has its problems: it's really slow, it is unreliable/unstable sometimes, with very strange noises and repetitions and outputs of zero seconds sometimes. But it is very remarkable when it works well, the best by a mile among what I've tried.
I think we should 'just' find a way to fine tune in a stable way without losing the zero shot multispeaker capability.
I have an idea, but I'm not that good in programming.
When we fine tune we lose the multi-speaker zero shot capability and we degrade the reliability of the original model, at least it seems to me. I have seen in image generation this model called ControlNet which allows conditioning on additional input modes other than text.
For example, you guide the image generation not only with the text prompt but also with whatever representation you want. For example you guide the input with a heatMap, with edge contours etc..
They don't want to train a new generative high quality text to image model, they want to leverage the high quality established stable diffusion model. They also don't want to fine tune and unfreeze the stable diffusion weight as this might lower the output quality, overfit over the small dataset or increase instability in the output.
So they actuate a smart strategy for which they use a hypernetwork (which is like a mirrored version of a part of the stable diffusion) whose activations are added to the activations of the stable diffusion model.
The stable diffusion model is freezed, and only the hypernetwork is trained.
Controlnet is just for diffusion image generation models, but in reality it proposes a new way of fine tuning which should ease the process and make it stable, while retaining what the orginal model has learned during the original training.
It would be nice to apply this idea to Tortoise fine tuning.
Here's some reference:'https://www.youtube.com/watch?v=fhIGt7QGg4w' this video talks about the more general idea about ControlNet.
I hope I can spark the creative idea of someone more skilled than me.
Having said that, I'm very curious about Vall-E as well.
I'd like to advise against using https://github.com/enhuiz/vall-e and would rather propose to take a second look at https://github.com/lifeiteng/vall-e
The enhuiz implementation seems dead, the author is unresponsive and going by the open issues there seem to be problems with the training process, with multiple people reporting it producing garbage results.
The biggest gripe here is that the author has gone completely silent to any queries or other questions regarding the implementation and has been seemingly absent for over two months.
The perceived quality of the code is irrelevant, if we can't guarantee the correctness of the code in the first place.
In contrast to this, the lifeiteng implementation seems to be actively managed, has the author chime in on issues and discussions and, most important of all, was able to present some promising results so far: https://github.com/lifeiteng/vall-e/issues/53
Considering the lhotse + k2 + icefall dependencies, I agree, they are certainly cancer, but they are only used for the dataset preparation. I am sure it should be possible to reverse engineer the process so far, to just be able to prepare our own datasets for the training process, instead to rely on the supplied recipes.
That being said, I managed to get the LibriTTS training process running on my WSL2 Arch Linux on a 3060 12GB (though it was only out of curiosity, so I never let it train for any amount of time), and the author managed to get promising results on the smaller dataset with only 8 hours of training on similar hardware.
As for Tortoise, it was a mixed bag for me. Finetuning refused to deliver any results and the base model was able to produce promising results for some voices, but overly british accents or voices completely different from the source for others.
Overall I'd consider it a deadend, so I am happy research is going into other backends.
I'm no stranger to that, given how I'm pretty much fostering TorToiSe, whether I like it or not.
I think it's just chalked up to terrible defaults.
I should be fine after correcting these things. I imagine anyone that tried to use it fell into the nodev trap and assumed the defaults were sane (and desu I fell for it too, only because I made bad assumptions).
From my cursory test, I'd rather not try again:
Compared to the first implementation just dumping things similar to what DLAS does: bunch of files and parse the directory. Simple.
I could gut the newer implementation to have a simpler data loader, but I can't be assed.
About that. I got a similar error that I got with the newer implementation when trying to train with the first one (some assert and a CUBLAS enum thrown), but I tried again yesterday after doing some other things (I think using torch2.1.0 nightly worked), and from there I'm smooth sailing on a paperspace instance.
Although, the newer implementation refused to work on my 2x6800XT system somewhere along the pipeline (I already forgot what segfaults), while the first one did, so even if the newer implementation is favorable, if I can't train locally, I can't back it.
And desu, the first implementation using DeepSpeed feels like it'll mature over time by itself with any changes to DeepSpeed, while the newer one is up to the owner. Although, the newer implementation does leave room for me to work my magic and inject BitsAndBytes. DeepSpeed allegedly has int8 quantizing, but I can't seem to find how to use it, if it's even for training.
Ironically, I've only been getting decent voice-finetune results on my 2x6800XTs. I'm not sure if it's some inherent nature about multi-GPUs, or something between ROCm and CUDA, but whatever placebo it is, any of my future finetunes will have to be done on those and not a paperspace instance.
Yeah, the base model is too inconsistent for zero-shot. A specific subset of male voices will work fine, but everything else won't.
I just hope I can get results with VALL-E. I can sort of understand a lack of a generalized model, but I feel I'm once again the only shot at getting something cobbled together,
I crammed BitsAndBytes into the first implementation using a similar "injection" I did with DirectML jerryrigging for CPU-only functions. In hindsight, I could have also used this method with DLAS, but oh well.
desu the gains aren't as large as adding it to DLAS, as I'm only able to slightly bump up my batch size from 16 to 18 before it gets unstable and occasionally OOMs on an A6000 (48GiB VRAM). I'm not sure why it spikes 4GiB of VRAM occasionally, or when it tries to save.
I can make some guesses as why it's not a huge improvement, but oh well. Bit of a bummer it didn't drastically let me cram a larger batch size in.
Got training to work on my 2x6800XTs with the newer implementation, and I'm a bit skeptical.
I think I got my ducks in a row with the first implementation (these were at 10000 steps, dataset size 55, batch size 1, defaults for all the other knobs, trained on my 2x6800XTs for I think an hour? an epoch can be ripped through in about 10 seconds):
I realized a few things:
It just seems odd though, there's definitely something off, especially:
I'll just have to wait and see how things shape up with baking the model. If it turns out decent, great. I'll be comfortable with renting out a GPU to do bigger training on (or cave and buy a 4090, as the prospect of renting for pennies sounds worse than just splurging $1500 on another GPU).
There are cheaper ways to get 24GB of VRAM
VRAM isn't my concern. In fact, I found both VALL-E implementations to be poor when it comes to VRAM. The one I'm backing just scales horribly (between an A6000 and an A100-80G, I could barely bump up the batch size), and the newer one never wanted to use more than 12GiB as it decides what batch size it wants.
I already have a collective 32GiB with my 2x6800XTs, so VRAM is most definitely not an issue. In the context of VRAM, a 4090 is a downgrade in capacity, and most definitely a Pascal card is a downgrade across the board.
It's just an idea to float about getting an actual card for ML for improved throughput if I'm going even more balls deep into it, rather than reusing cards I incidentally have that incidentally do okay. P*p*rsp*ce took a massive dump on me this morning, so I'm skeptical of using it (or any rentals) any more after being burned again.
Anyways, at step 27000 (after switching to bs=16, ga=2), the NAR sounds nearly the same as the reference: https://vocaroo.com/1jaGF5sduPQH. There's a bit of warble still, but I'm impressed. The AR still sounds iffy.
Step 40000 and the AR finally sounds better: https://vocaroo.com/18egrMwF6W4w
Still terrible, but it at least has audible speech.
@mrq what dataset you use currently. I can try on my system to double check too if it helps.
Some ten hours of some LibriTTS labeled LibriSpeech-Finetuning that I nabbed off some P*p*rsp*c* article about VALL-E, except it includes everything in the archive and not the 9h subset. The link to I itself is under my VALL-E fork repo in
./scripts/prepare_librispeech.sh.If you got a few days to kill, go right ahead. I have a small repo on HF with the data already quantized and phonemized to avoid going through the hoops of my rather-fragmented preparation process.
With your current working directory set to your
ai-voice-cloningfolder:source ./venv/bin/activategit clone https://git.ecker.tech/mrq/vall-e ./modules/vall-e/pip3 install -e ./modules/vall-e/git clone https://huggingface.co/datasets/ecker/libritts-small ./training/libritts-small/./training/libritts-small/config.yamlto your likingexport CUDA_HOME=PATH_TO_YOUR_CUDA/usr/local/cuda-11.8/or something. For Docker images with CUDA-11.6, and you installcuda-nvcc-12.0or something, you'll need to point to the newer one.export ROC_HOME=PATH_TO_YOUR_ROCMbin/hipccinstead of/opt/rocm/deepspeed --module vall_e.train yaml='./training/libritts-small/config.yaml'I restarted training two nights ago and fiddled with some more settings yesterday, so progress restarted, as I didn't trust the initial dataset to be "right" in the sense of using the entire dataset, optimally.
I also manually validated if BitsAndBytes was even working (it's not).
torch.nn.Embedding, rather custom ones that inherittorch.nn.Module.torch.nn.Linearforbnb.nn.Linear8bitLtcauses errors (not surprising, since it's not integrated with DLAS, and naturally).So I'm stumped with BitsAndBytes. I can give it more cracks at it later today, but even DeepSpeed's weight quantization doesn't give consistent VRAM savings (sometimes my GPUs will sit at 12GiB and then it'll sit at 15).
I will admit I did cave and get a 4070Ti, as:
The only caveat is:
I'm stupid. To spare the gory details:
Although:
Hello, I don't know if it's of any concern, but someone on the newer repository uploaded a trained model as detailed in this thread: https://github.com/lifeiteng/vall-e/issues/58
I managed to download it and ran some of my own tests, which I wanted to share in case it's of any interest.
Solid Snake:
(Source) https://vocaroo.com/17lhindJicrD
(Result) https://vocaroo.com/1b3Cqih5Lgtb
Exdeath (FF5):
(Source) https://vocaroo.com/1fMlLIejplOt
(Result) https://vocaroo.com/1oKsiTHfuTPH
Jecht (FF10):
(Source) https://vocaroo.com/1jMNgguHCZE8
(Result) https://vocaroo.com/1zqjXWgg7Fzs
Vile (Megaman X):
(Source) https://vocaroo.com/19KuGc5bMtd1
(Result) https://vocaroo.com/19J6GpGavMxy
From the first glance it seems to be running even slower than Tortoise.
Of my samples, only the Snake one seems to match the speaker's voice and even then he seems a bit too.. jolly?
The others don't fit the speaker's voice at all.
Sadly not the silver bullet I was hoping for, but I guess it all depends on what's in the model again.
Neato.
Yeesh. I'll be a pessimist and assume (cope) that a lot of that time seems to be just bruteforcing through unfavorable conditions with (most likely) zero optimizations:
I feel like it has a similar problem the first implementation has: they're made by grad students with lab rigs who only know ML and nothing else. Don't get me wrong, they know it better than me, but they're not pragmatic (for lack of a better term) about how they go about it. I just can't really place my trust in either implementations after seeing the warts.
Thanks, I can't be assed to try and pick apart how to use the newer implementation for a third time for cursory tests.
I'm a little impressed from its results, a very small little. The model itself definitely isn't a tortoise replacement, but it at least shows it can provide something. My only concern with how little actual moving parts are in it, there wouldn't really be any room for bandaids like for TorToiSe.
There's something off about it outside of the audio quality, wrong pitches, and I suppose the general tone. I can't quite put my finger on it. I wonder if it's an issue with how the phonemes are processed, as I think it's only using the base settings for phonemizer (no stress symbols, no spaces). It sort of sounds like what https://ipa-reader.xyz/ spits out.
Most definitely.
For zero-shot inferencing applications, diversity (ick) is a HUGE factor in having a good model. There's only so much data to sample from when trying to mimic voices. I worry that when I finally nail training a small model, that I'm going to be in a world of hurt trying to pick every piece of clean audio I can get and adequately processing it (although the web UI is rather decent at that now). The magic of TorToiSe is in the dataset it was trained against, as its author mentioned not using just audiobooks (a bit ironic, since it still has its biases on how well its zero shot inferencing performs).
I think the other issue is that, depending on how conforming that implementation is, the paper calls for using only three seconds of audio for zero-shot inferencing. I think I saw some commits about different "prefix" modes (I think an analog to how I was changing how I'm computing latents, and the 152334H fork having its different settings for it too), so it might do better with more than three seconds to play with.
However. TorToiSe has definitely shown that finetuning a model that's semi-semi-competent is viable. I could care less about a "10/10 amazeballs" model at zero-shot when you only really need a semi-semi-decent model to finetune from. That's more of what my goal is/should be: just get a good starting point so people can finetune off of it.
I suppose one last thing before I go back into my hole for another few days: training it is shaping up to be a real bitch and a half. I suppose it's only natural it is so, given it's a language model. I'm doing some sussy "warmup then decay with restarts" to quickly train it over painfully bruteforcing it with the LR decay that both the newer implementation used, and DLAS/TorToiSe does (for finetuning at least).
Rereading the paper trying to procrastinate sleeping, and there's some things I guess that would have been nice if it was disambiguated, rather than inferred from both implementations. The original VALL-E:
The training process seems fairly simple. It's just the first implementation does it the rather classical way of training by batches, but I'm not sure how much that'll be a problem. I worry I need to revamp the both the transcription process and the dataloader to replicate the original paper better.
Progress report for whoever cares about my descent:
-quartertests; it's not worth the time testing a gimped model if I want to validate that I can even get decent results with this implementation.My thoughts and concerns:
Some whacky ideas I'll spitball that I won't probably do:
Roadmap / Goals:
I just hope that things are smooth sailing from here on out now and I can use the time waiting to train to finally relax.
The japanese tortoise model is really cool. Would VALL-E X provide better results?
Reading through the VALL-E X examples, it seems to be able to seamlessly switch between English and Mandarin, while preserving accents.
Does this mean that we could do something like train against Joe Rogan in only English, then have him speak in fluent Japanese?
Is the VALL-E implementation you are working on capable of Japanese?
Forgive me for butting in, but howcome you haven't worked on building a more varied dataset then? There's hundreds of hours of video game dialogue & podcasts available for you to build a more diverse dataset from, not to mention other varied audio datasets that could be included.
This issue reminds me of an LLM paper I had seen here https://arxiv.org/abs/2203.15556, that seems to coincide with the dataset claims tortoise makes, and your woes. I think it would be worthwhile to try scaling your dataset size instead of trying to scale your model size in it's place? I would test the theory myself but lack the hardware that would actually be suitable for training to test this theory so feel free to call me out on it.
The Mozilla Common Voice Dataset is over 3000 hours and CC licensed. Podcasts, which one might have to transcribe (or at least proofread) manually, aren't a wise use of limited developer time by comparison.
Hard to say.
I feel whatever base VALL-E puts out for Japanese is an indicator of how well VALL-E X will perform, as the only difference in implementation between the two would be annotating language during training, be it from additional tokens or another input. I'm not too sure how I would go about it, as there's no exisiting implementation for me to
leechdraw inspiration from.Very. I'm more impressed with the VALL-E X demos moreso than base VALL-E's demos.
mmm. Should be. I imagine for testing a VALL-E X implementation, I would source a Japanese speaker that sounds like him and train against both of them. The limitation is getting a soundalike.
The magic of VALL-E X is being able to sample speech against an acoustic prompt (voice latents, in TorToiSe terms) similar to your subject. That's sort of what LM-based voice cloning does. I imagine the secret fixin is just providing tokens for language (like a start/stop token, but start-English/stop-English start-Japanese/stop-Japanese), and the ability to have multi-lingual speech synthesis is just an emergent property of basing it on an LM, or some gobbeldygook.
Mhm, should be. The only hurdle is trying to mend the phonemizer to work on Japanese again, as I remember it breaking at 2AM and I couldn't be assed to bandaid the phonemizer.
I will, don't worry. I just need to babystep through this and not throw in too many variables. My crux with my tests before were not having a clear focus in how I should go about testing and experimenting.
I'll probably get to sourcing a master dataset while I'm training models for the final step. For now though, I need narrower datasets for tests to ensure things can in fact scale up with the implementation before sinking in so much time for a bunk model.
For zero-shot inferencing, of course a large/diverse dataset is necessary, but that won't do any good if you don't have a model big enough to learn all of it. I found the quarter sized one to cap out and lack the capacity to really learn anymore without a painfully astronomical training time to bruteforce it, if time would solve it.
That's definitely a worry I have that would "filter" a lot of people trying to roll out their own models. VRAM is no issue, as with enough optimizations, I can have a full sized AR and NAR and wiggle room on 12GiB, but the crux is a tradeoff between compute time and compute throughput; I can have all the speediest VRAM in the world, but it's no good if I can't use it fast enough. I have relatively the same throughput at bs=4 as I do bs=8 anyways.
And you can only really get good compute with Ada cards (4070Ti and up) or multiple Ampere cards. There's always """r*nting""", but it's not a good value proposition, at all, especially for testing.
How convenient. I want to believe, for zero-shot inferencing, more speakers is better than more hours, so this is probably a great way to get varied voices.
I feel any dataset is going to have the same amount of time to transcribe and validate desu. I can't really re-use existing transcriptions, as:
It pretty much took 5 hours last night to re-transcribe LJSpeech in WhisperX large-v2, and probably an extra two this morning to quantize and babysit the phonemizing process (for a valid but still God forsaken reason, phonemizer will make a temp copy of the espeak lib on every call and only cleans it up when the process closes, so it'll crash after X amount of phonemizings). I suppose I could get a better transcription process, but WhisperX is probably the best I'll get.
I've had outstanding results with WhisperX once I started running it with
--align_model WAV2VEC2_ASR_LARGE_LV60K_960H. The downside is that it doesn't support many languages out of the box (but Japanese is one of them, IIRC).However, I don't think you need to bother with that though because in the sample I downloaded it's already segmented. I grabbed the latest delta of the Indonesian corpus (only 110 MB) and the longest clip is only 10 seconds.
I mean if that's the case I'll have a second 3090 with NVLINK sometime next month, so maybe that'll make the difference.
In regards to that paper, it basically showed that most LLMs where underfitted , the cure was more data and training st the same model size. It's probably going to be a necessity given the results, so maybe it's going to be more beneficial optimising the training itself before devoting to the training.
Yeah, I have that model load for English only just so I can try and get something together when reintegrating back to the web UI. I should make it another option, but I can't be assed to at the moment.
It's enough of an improvement getting everything together + VAD filtering that I can finally rely on it for transcription after being scarred.
A single 3090 allegedly has similar throughput to a 4070Ti, but I haven't validated it myself after all the optimizations I cobbled together. It just feels like I'm having nicer throughput with my 4070Ti over using a P*p*rsp*c*e A100-80G before they fucked me in the ass again.
Ah, I guess that would explain some things. Pretty much most of my tests just seemed like in the worst spots where it's too big to overtrain and get results like the Joe Rogan tests, but nowhere near large enough to get it to not be so grossly underfitting. The LJSpeech one seems to be going a little better than the LibriWhatever subset I had over the weekend, but doesn't seem to be improving any more.
If the valley between the "too little and you overtrain" and the "not enough and you underfit" is just that large, I suppose I'll start working towards getting a ginormous dataset together.
I'm pretty much all out of my magic tricks to make training better.
Well, there's reusing/sharing the text / acoustic prompts embeddings between the AR and NAR, but that doesn't seem like it's much of an issue for training.
What would such a dataset entail?
If you are not to shy away from using materials with legally uncertain licensing issues, then
I'd happily contribute my growing collection of video game character samples (extracted straight from game files) + transcriptions.
Not too sure. It'd probably be a mix between:
My only qualm with using sources from the collections on the wiki is that almost all the voices there are one single file, so transcription/segmenting will be a bit of a pain.
Of course not, I'm fine using whatever. It's just slightly more convenient to use "open" speech corpora as they're usually cleaned up well enough.
Sure.
I'm so mad. I had a decently lengthed followup, but because I used a stupid emoji that the text entry field suggested, it ate it all up.
Pah, oh well. It was mostly outlining a path I should take by using actual audio from vidya rather than audiobooks as audiobooks have the inherent problem of not being varied enough.
Vidya also has the added benefit of coming already segmented in small 2-5 second chunks, as well as being clean studio recordings.
Plus, a lot of them can be easily extracted from game files as well.
Progress report:
Inferencing with VALL-E is integrated into the web UI, with some warts.
Training wise, I found it's "relatively" """easy""" to """""add""""" additional voices with an existing dataset on an existing model, and I imagine finetuning a single voice might work nicer. I'm doing some funny shenanigans by quickly warming up the LR to 2.0e-4 for an epoch's worth, then decaying down to 1.0e-6 for 1000 iterations (which in my last set it seemed to be for 9 epochs).
I might need to continue the above procedure by adding in more and more voices to the dataset to find a point where it'll stop overfitting. I'm just worried how many voices I'll need, and I worry about risking frying everything by doing these pseudo-restarts too much.
Aside from that, there's not really much else for me to do besides re-read the VALL-E paper / both implementations while I keep baking models and shoving in more voices, since there's some things I just don't quite "get".
Oh well. I shouldn't sweat over the issues so much; as long as the evaluation/validation output sounds fine during training, then I can just keep training a model and eventually resolve any issues with inferencing. It'd be nice if I had someone to come swoop in and call me a dumbass and other quasi-derogatory-slurs for neglecting details, but I imagine there's no one else that really has an idea about VALL-E outside of the people behind the M$-backed paper, and the two implementation writers, all of which seems to be behind a prohibitive language barrier (or in the case of the one I forked, unresponsive). I'm in no rush to nail out a working model, after all.
I imagine my issues, once again, stem from an extremely small dataset size. As mentioned:
And the paper mentions it several times:
I suppose the strength of VALL-E is that given an extremely large dataset (60k hours, 7000 speakers), the LM properties it boasts over other TTS systems emerge. So I guess I'll just keep shoving in more and more and more and more and more data.
I'll need to come up with a way to try and crowdsource a bunch of data then. Even trying to come up with what vidya to source my voices from is leaving me feeling overwhelmed already (both from even trying to think of where to pool from, and storing it all).
Bear in mind, I am merely a weeb with no knowledge whatsoever...
With that being said...
tldr You should enforce high example standards, and pool the efforts of the community/other people, and use anime transcriptions instead of/in addition to vidya
To preface, based on reading your commit descriptions, and paying attention to your mannerisms, I assume you don't give a fuck about morality. So i have taken that into consideration when writing...
One of the biggest things, is that you have to leverage yourself correctly
People like Roukanken can immensely help you, if you let them
There are many people who would love to contribute to this project, but who are unable to from the coding side of things...
And lets be honest, its definitely not worth your time to collect/process data, as opposed to developing the code...
But there is a way to utilize this manpower effectively...
You need a way to publicly delegate tasks, and collect the data in an efficient matter...
We could create a google form for something like this...
It would be a public form, that anyone can sign up for, and you can delegate certain materials to different people, with varying metrics(ie I need someone to get these files, I need someone to transcribe this files, I need someone to split these files, I need someone to clean these files, or you can simply assign the whole request to one person)
The biggest thing that would be needed for this to work effectively is...
There are more complexities as well, such as managing voices per character, background music/noise, but as far as scale, anime may have you covered.
I am unsure of the best way to store the files but once something is completed, it is proabably best for you to simply download the files, then be done with it(after all, there really is no need for anyone to have the final,perfect cut files aside from you, especially if they meet quality standards)...
Advantages to using this method
Disadvantages...
To mitigate some of the disadvantages, you could "assign" someone to help with this, ie it would be easier to train one to three people to understand what you need in an audio dataset, then have them actually verify the incoming data/audio for you,then simply trust their judgement, as opposed
to you manually verifying each dataset. That can significantly free up your time investment...
I am unsure of your current process of getting data ( I know that you use certain game rips and libraries),
but for fueling a massive, unethical dataset, desu I think this is the way...
The only thing, is that there is no pre-existing "anime library", so in a lot of ways, this would be the first of its kind...
If there is an existing library, ie where people have ripped audio VA from characters and transcribed them, it would be far easier, but to my knowledge this does not exist.
Where do we get the material?
Fortunately, anime is very easy to download out in the wild
Various websites offer download utilities, and there are some that allow for downloading anime in bulk...
However there is still problem... how to prep the data?
Transcriptions and community service
There are various "transcriptions"/anime fan transcriptions, as well as subtitles for various animes...
These files provide the ENTIRE dialouge for a given episode of an anime, with both English and Japanese transcriptions. This means the accuracy is pretty good (provided the authors were accurate initially. For Japanese I believe your software uses Hirigana/Katakana? That would be one issue, but I am assuming we could just throw the transcription into one of those online websites that would simplify the kanji into hiragana/katakana)
But...
How to split?
This process would be a lot of work for one person. Unless there is a superior method.
This is where a little investment would be needed to create a proper tutorial...
Essentially, we could teach community members, and incoming members how to contribute to this project by...
Generally, most of this can be done through audacity
(If I am being honest, there is probably a way to automate the "cleaning" aspect of audacity, ex. autorun a script that will take a batch of files, and apply a (NoiseRemoval>compressor>Equalizer))
You will need to invest a little bit of time into making the process as straight forward as possible, and being CLEAR as to what you need, and do not need, but it would get you brand new, high quality audio files
You will proabably have to "inspect" the audio somewhat, but that's what you can train someone for....
Part of me honestly wonders if there would be some way to match the transcriptions to the audio, then split it automatically. In theory, if you could do this, this would actually reduce the need for community involvement,
because it would be as simple as getting the transcript, audio, splitting, cleaning, then using. You could basically create a one click system, that gives you the data you need (albeit, with some light inspection)
However, my concern is that some transcripts do not include timestamps, making this somewhat difficult... maybe someone has a creative solution?
Where to store?
Harddrives? cloud services? Exactly how much space you need? Im sure people would be willing to pool some shit together for you...
So to recap
I would say in terms of collecting data in this fashion, you would have to shift to being a little more of a manager and a coder, as opposed to straight doing everything yourself, but fuck it...
There are also other ways to get audio that is HIGH QUALITY, PROPERLY TRANSCRIBED, but that is less "morally acceptable", but if you would like to talk on these, you can hit me back...
Lmk what you think...
I'm willing to help out a bit more if you are interested...
Almost all of what you've proposed above can be done automatically.
whisperxproduces millisecond-granular timestamps per word (in ASS format, like Anime subbers use), those timestamps can then be fed intoffmpegto produce segments of the appropriate length. Cross-check against fansubs (or the official ones, if available) and throw out any that don't match.I wasn't all that familiar with Whisper, but it does seem quite awesome.
I guess at that point, if what you say can produce the segments, then all we would need to do is feed him the data/anime?
Can WhisperX detect differences in speakers/be able to "sort" multiple speakers? i.e. for a full anime episode, multiple characters.
There are proabably more efficient ways to clean the data, as well, I presume.
I'm not even sure if I need high standards. WhisperX does a damn decent job now at transcription and timestamping, and the VALL-E paper says just having a ginormous dataset is robust enough to noisy audio and some inaccuracies. Sure, it'd be preferable to have the data as accurate as possible, but it doesn't need to be 99.99999% accurate.
desu I just need ideas on what to source from (and a bit of where, as sounds-resource.com seems to be missing a decent amount of stuff that crossed my mind). Sure, it'd be nice if it was all handed to me transcribed and neatly prepared, but asking for it to be transcribed is a bit of a big ask, as I'd pretty much require only transcriptions from WhisperX + large-v2 + VAD filtering enabled, which requires a HF token. It's not a huge deal for me to do the transcription process itself, as a few hundred lines can be crunched through relatively fast on my 4070Ti.
My qualm with anime (dubs) is that there's a considerable amount of extra effort needed to get decent audio. I imagine the best case scenario are BD releases with the vocals on a separate audio track, and you can just segment the audio by subtitles and it's all good, but the worst case is aired anime won't have that. I also don't think any of the few anime I have watched were dubbed anyways, so I won't have much of anything to source from myself.
In terms of """ethically sourcing""" a dataset, I don't really have an qualms about that.
The only thing left really code-wise is just to make my own VALL-E implementation rather than rely on an existing one and continue working around its design desicions, but even then that's pretty low priority.
Pretty much what I had in mind. I'd settle just with something to submit character name + source and a link to the audio (or at the very least, where to get it).
Actually, the final, quantized audio that gets trained against doesn't take all that much space, so something ginormous won't actually be all that much of a detriment. It's just the source audio that becomes a bit of a pickle if I keep it on disk. Worst case, I do have several, several drives (and could always buy another 10TiB one), but I'd just have to do bookkeeping as I'm quite a datawhore.
desu my concern over VALL-E X is quite a ways off (or at the least, even having a Japanese model). Incorporating Japanese would have to be when I do get something cobbled together, as I'm really not sure how much of a problem it would pose with training with a multi-lingual dataset, as much as it would definitely help increase my voice variety with including my sixty-or-so voices I already have transcribed.
From here I'll just generally address the rest of it.
I appreciate the thought-out planning on it all, but at the end of the day, as long as the samples are somewhat-put-together, I'll accept it: anime, TV shows, movies, what-have-you. Just anything that isn't an audiobook reading, as that's where I feel is the less likely to provide much of any variety. I'm not strictly restricting it to just muh vidya for the dataset; it's just both the best and easiest to source from, and what I'm 99% likely to source from myself.
On the flipside though:
For now though, anyone's free to drop a link to what they would like for me to train the model against. Between my usual weekend rituals and RE4make, I'll probably try and cobble together more voices to feed the training model, as I fed it the rest of what I had on my training server and it seems to already have peaked, given the little improvement from doing another LR restart.
Yeah. I pretty much just need the audio, and WhisperX / the transcription part of the web UI will handle the rest.
With diarization, yeah. It's not something I've tested, but the web UI's integration with WhisperX can use it, although I'll need to uncomment one line.
Hey @mrq have you seen this one? Thoughts?
https://github.com/svc-develop-team/so-vits-svc
Unless I'm misunderstanding it:
I suppose it can fill a specific niche, but those two things for VITS (whatever they're classified as) are kinda not in my scope. Even if not for those things, I wouldn't really dip my toes into it since it seems it has its own hands working on it. I only really dipped my toes into TorToiSe (and by extension this VALL-E implementation) it was pretty much abandoned (at least, at the time, I don't remember the timeframe between me slapping a web UI and finding out about the 152334H
fork) but with lots of room for improvement.
Also I don't think I can have another ecosystem under my belt.
On the other side of things, the gravity of how much data I'm going to need to feed this beast is starting to weigh down on me more. I greatly increased both the speaker count and lines being fed (I think I'm up to 51 speakers, 18484 lines, not sure about total duration) and, while I'm not so concerned about the throughput rate in terms of the entire epoch, it only seems to amount a minor amount of an increase in output quality.
The AR's evaluation output is sounding better, but the validation output is only really sounding somewhat passable for English with the old-ish (as of a couple of days ago) voices, before I threw in the rest of Persona 3's voice lines into it. The NAR sounds better as usual, but there's no point in the NAR being good if the AR it gets fed isn't up to par.
I guess I'll just keep feeding the beast more data to train against. I'll let the Persona 4 lines (non Golden, unfortunately) bake for a day or two before throwing in more voices.
I could give up and feed it a LibreWhatever dataset, but I really don't want to feed it audiobook readings; I'm already getting better results it feels by feeding it muh vidya audio.
If you don't mind sharing your collection @Roukanken (or anyone I suppose), I'll be happy to nab it and dump it into the hungering beast. The audio itself is fine, as I'll only really be comfortable with the transcription if it was ran through WhisperX large-v2 + the VAD filter (as I haven't tested the segmentation quality on anything else).
So, I was letting the FUD get to me about whether or not I should have backed the newer implementation instead. I was getting the model code transplanted into my fork, and as I was stitching up the dataloader to the forward pass, I realized something.
The first implementation (enhuiz) will:
In hindsight, it makes sense, as it'll train in a way that reflects the way it's inferencing. This should have great zero-shot capabilities, but at the "cost" of it being stubborn to train, and terrible to try and have as non-zero-shot TTS systems (like traditional TTS).
The newer implementation (lifeiteng), doesn't seem to do that. It'll pull "pre-computed features" (I imagine it's just the quantized audio but abstracted through Lhotse's API), and will use the "input prompt" as the target. Contrary to the above, it's quicker to train, but harms zero-shot-ability, as it's not reflective of how it's inferenced against. It's not truly leveraging the capabilities of an LM.
However, I can't really knock it for that, as it at least has a "working" (albeit, not up to par) model, while the first implementation doesn't seem to have one yet.
However, one flaw is that I'm required to keep similar voices together, and not mix speakers within a folder. It's being a pain since a lot of more voices I'm sourcing from are all one incestuous mess of uncategorized filenames (pretty much everything I either have to rip myself or I've found ripped already; I only got lucky with being able to categorize the Persona 3 and 4 voice files).
So what are the guidelines?
How many segments minimum?
Ideal clip length?
Just English?
Any particular way you want it labeled?
Also, does this mean you are including another implementation, or are you sticking with the one you are currently using?
@mrq
Not sure; I still have about 20 voices that have sub-50 lines that I'm not too sure how much would help shape things, but I imagine at least 10 lines would be fine.
Ideal would be between 3 and 12 seconds, but whatever the transcription tab the web UI will spit out seems decent enough. The paper mentions 10 to 20 seconds, but it's better to not have audio lengths too long.
Mhm. I'm worried adding Japanese voices might be too much right now. Phonetically it should be fine, but I need to wait for this next batch of voices to cook before trying it.
Nothing in particular. One big folder of all of a character's dialogue is good enough, and I'll just feed it through WhisperX to transcribe and timestamp it adequately.
It would be a big help when I further scale up the dataset again. As of now I've fed it:
I also have Demon's Souls, Elden Ring, Tales of Symphonia (and I need to extract Vesperia skits), and FFX, but they're all uncategorized so I can't really do anything with them outside of some clever tricks with modifying the dataloader process.
Here are three links that I think would be a good fit.
https://www.youtube.com/watch?v=XkMoingR1p0 - JFK
https://www.youtube.com/watch?v=hzW-h_Rm8Jo - Dempsey, really good emotion
https://www.youtube.com/watch?v=1S48jHXh44U - Misty, female variant
In general, Call of Duty has really good voice acting for the zombies portion, and all their characters have 10-20 minutes blocks of audio, all of which is clean.
Between all the games, there is proabably a large amount of characters we could use.
Would you like me to download and link these for you? Or can you do it on your end? (These are larger chunks of just one character each, so I figure it be easier enough to just run through whisper?)
Also...
I can rip it with yt-dlp and transcribe from there. I'll add them into a next batch after this one gets chewed through (at this rate, I think another few days).
No preferences.
If it were on rather monotonous audiobooks, I would probably try and have "uniformity", but because it's on real-er data, I don't think I should have uniformity like specific accents.
Have you checked out the Pony Preservation Project Datasets You can found them here:
https://mega.nz/folder/jkwimSTa#_xk0VnR30C8Ljsy4RCGSig/folder/OloAmDqZ
and here (These are non-MLP datasets):
https://docs.google.com/document/d/1y1pfS0LCrwbbvxdn3ZksH25BKaf0LaO13uYppxIQnac/edit#heading=h.6jgcpmrwa3fq
all of them are already filtered, organized, cut, and transcribed for you, so that could hopefully make it easier for you.
Oh right, I forgot I can leverage /mlp/'s autism. I'll nab them too for the next feeding time as well. I'm sure they'd also appreciate if I did train it on their technicolor horses.
I was going to say it's a bit of a shame that most of it is already Persona 4, but if it's Golden, then that's golden. It does have S. Links too, which my rips from sounds-resource doesn't have, so I might as well grab those regardless and replace what I have.
Sugoi. My only worry is if a cut might be too long and either get culled anyways or will cause OOMs when the stars align. However, I might be able to remedy this with having my fork conform to the paper better (have the input audio prompt trimmed to 3 seconds; it might also have a training throughput at a cost of not being able to having as-strong variable length input prompts)
I swear every time I grow a wild hair and dive back into the implementation I forked, there's another twist with how it behaves.
To be brief, I was trying to both have a way to calculate duration from the encoded/quantized audio and then see about trimming the quantized audio down to 3 seconds to feed for training (to see how much used VRAM I can reduce and how much of a throughput increase I can get).
Turns out, that not only does the implementation randomly selects a different utterance to use as the input prompt, by default, it can use up to three random utterances and combine them. I say up to, because it does a probability check to see if it should continue. This most definitely will explain the wild variation in VRAM use between steps, so I should be able to make this a more sensible amount.
I'm pretty sure this is overkill, but in theory it should help with try and dissociate input length from inference quality, but at the same time, I think it'd be much, much better to just have it poll one utterance.
Enforcing a maximum of 3 seconds for training has let me set a batch size of 4 to a batch size of 16, for the same overall iteration rate (so I effectively 4x'd my training now, I guess I've been bottlenecking my 4070Ti). I think I'll just keep it that way.
Yeah the one on the doc are the golden version! At least according to the anon who ripped them (I didn't check it myself)...
Can whisper run through a batch of single files with the same level of convenience? There are some clips I have where it is like 40 .mp3 files, all unlabeled, but for the same character. I figure I would just stitch them together into 1 file anyways, but I am just curious.
Kind of. You can specify multiple files when you run it, ex:
whisperx --model large ---task transcribe --language en file1.wav file2.wav file3.wav ...Yeah, they're from Golden. I tried adding in the Chie lines the other day (since I will admit the Golden VA grew on me despite initially preferring the original Chie for some time) and I couldn't for the life of me get it processed through WhisperX; it would kill the entire process when it got passed the first three or so lines. I tried remuxing it in ffmpeg but no luck. Oh well. I was only doing that since I had to revert from a checkpoint the other day, as I completely botched something when I was moving my data around (more on that specifically later).
Yeah. My naive way about it is to just throw it all into one audio file (I can't recall if I mentioned the steps to do it with
AudacityTenacity on the wiki somewhere, but that's what I would do to stitch them into one audio file), as I have some voices that are unfortunately one audio file. That approach seems to work almost just as fine as having audio separated for a single voice.I imagine it might get me out of a pickle with completely unlabeled multi-speaker rips with diarization, but I haven't bothered trying it yet.
It seems to be effectively the same as programmatically doing it through the web UI (in the sense the models are still loaded during each iteration).
I think technically you might be able to get better throughput if you process one mono-file instead of separated files if you have VAD filtering enabled, as the VAD filter "pipeline" allows for batching to increase throughput, and larger audios can be batched "better" (I don't think there's much of a throughput uplift if I have larger batch sizes set for sub-30 second segments).
Anywho, I'm blasting ropes from how training is shaping up now. It was a really rocky start, but it seems to be smooth sailing now, as I'm getting actual clean real output now from utilizing both the AR and NAR to produce output, rather than playing by ear output from each model separately.
After my serendipitous sniffing the other day though the implementation I forked, I:
./training/{voice}/valle/=>./training/valle/data/{voice}/), and because the speaker name getter lambda was fetching the 2nd-to-last folder name instead of the last folder name, all lines were treated as the same speaker (data), effectively making the input prompt random data. After fixing my issue, reverting, and the above throughput increasesI was able to squeeze out some more "optimizations" to increase my batch size from 4 to 16 while having an even faster iteration rate (bs=4 yielded an average of 1.4s/it rate, while bs=16 and disabling GC per iteration yields an average of 1.04s/it). I was wrong to assume my 4070Ti was not bottlenecked and that batch size wouldn't starve it of throughput. Unfortunately, I should have gotten a 4080 instead for more VRAM, despite it being the worst Ada card at the time (at the time, because everything 4070 and below is just as bad).
Additionally, I realized I can also test actual inferencing during evaluation (RVQ layer 1 of the AR, RVQ layers 2 through 8 through the NAR), and hoo boy, it's actually decent output, unlike the monstrosity of my initial inference test (for some reason my evaluation/validation datasets are either Westwood Blade Runner or Kingdom Hearts):
I picked the ones with noticeable flaws in them so they're more apparent they're not just the reference clip. There's still a sizeable amount of the evaluation output that doesn't sound quite right, and the AR+NAR validation output is pretty rough.
It's extremely relieving to hear that it actually can work, and it's probably just the provided inference method being a bit sussy. It's also relieving that I don't need to keep shoveling more, and more, and more data, but I might as well keep doing it, as it still has issues fitting just right for outside data, at least, given the validation output.
And my current graph (epoch count is related to the current dataset, I usually will do a soft-reset by loading the weights and not the optimizer state when I change the dataset):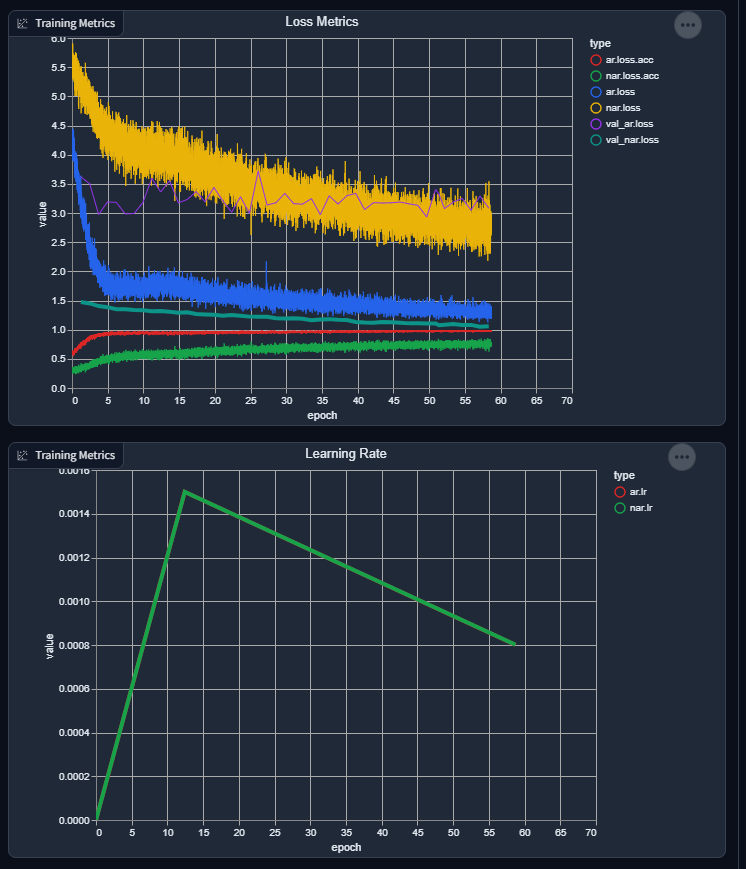
I haven't added reporting the loss for the AR+NAR yet to the graph (it should be simple), as it's a recent addition so it wouldn't thoroughly be reflected in the graph yet.
I still have a lot more baking to do for it to be "just right", but for it to give quasi-decent output now gives me hope instead of FUD with it being a fools errand.
Thats awesome to hear.
So do you still want data? I've got some awesome clips lined up. Both Japanese and English.
Are we still at this stage?
How much more improvement do you think you can get out of the VALL-E implementation? Do you think it surpasses/will surpass your tortoise model? Also, VALL-Ex?
So whats the process looking like now? Is it just to keep training it and adding more voices until its perfect?
mmm
It's hard to say still. I think my new-er understanding of how the implementation works, and how VALL-E itself works, wants to say it should be pretty resistant to any cross-lingual tainting, but I'm having a really hard time trying to express how it might be. I guess it's just better to try it and see how it behaves.
I'm not sure if I should aim for it now, since I know the implementation is perfectly fine and works (albeit the dedicated inference routine seemed a bit flawed, but that can be easily remedied). Outside of cross-lingual/VALL-E X, the last thing on the metaphysical list is getting a decent pre-trained model together.
But, if I'm doing that, I might as well get it baking on Japanese too. If I'm lucky, there could be some crossover with either languages bolstering the other up in training.
Performance wise, I'm very sure this time I'm all tapped out on how much I can squeeze, outside of playing with fire and trying 4-bit training (I worry about accuracy issues at that much quantizing). I genuinely can't think of any other avenues for improvement.
Output quality wise, definitely can get more improvement, but it's a matter of how long it will take for it to get there. My training method is still pretty naive and flawed, so I can always refine that aspect.
Quality of life wise, definitely more room for improvement. I'd like to slot in explicitily providing a validation dataset (easy, but it's low priority), and there's probably some other things to muck around with but I can't quite recall.
I think in terms of:
it definitely can outperform TorToiSe. It just is pretty much now up to how the model itself is trained.
In terms of subjugating TorToiSe to try and have a cross-lingual model, definitely. Non-English TorToiSe will always be restricted by both its tokenizer and the CLVP/CVVP.
Mhm.
The beast must be fed until it starts exhibiting decent zero-shot capabilities (through decent validation output).
Are there's still any advantages to tortoise after playing around with VALL-E?
@mrq Feeding the beast. Here is batch 1 of some stuff I've been trying collect. This batch has 10-20 hrs.
The only problems...
But overall, these seem pretty clean. Let me know if they would work for you, and if there is anything I can do to prepare future lists better.
I'll probe through them whenever I get the chance next. I incidentally worked on the dataset preparation process to be more cleaner and not a pain (stuff like fixing the phonemizer memory leak, batch processing all voices, allowing subdir voices, etc.).
Sadly, I may have had some flawed reference audio, as it seems I've trimmed them a little too tight at the end. I've been noticing whatever evaluation output makes it out that it ends a bit too abrupt at the end, so I had to reslice and reencode all my audio again with a trim end offset of 0.2s instead of 0.05, for safety.
I'm doing another "restart" with resetting the LR and iteration count so it goes through another LR cycle just to jostle up the weights again. I noticed a lot of the older data doesn't sound too great (P3 mostly is what I've been catching), while the newer audio (some Westwood Blade Runner, Kingdom Hearts, a few P4) will sound pretty decent. I'm not too sure why there's the disparity.
Not much of a progress report, since it still boils down to how much time I'm putting into baking the model. I've been wanting to at least release the model currently, but there's no point when it's doodoo asscheeks for zero-shot AND still a good majority of the voices it's training on; the validation output is still penis, and I'm very, very sure whatever validation output that does sound great was secretly trained against previously, as the dataset sets aside 5% of a speaker aside for validation (which depends on shuffling the list with a 0-seed for each voice, so it could very well change every time I'm recreating datasets).
I lied, I added more data, namely the CoD lines and the English lines from those BNHA/MHOJ2 YouTube voice clip compilations linked earlier, and a few other personal add-ins from YouTube voice line compilations to further put my trust in how it works. It seems decent, so I suppose if you can't be assed to source the raw audio files, but it exists as one conglomerate, feel free to share that.
I'm glad those worked. There are a bunch of similar games that would have really good sources as well...
Fighter Z
dragon ball tenkaichi
Attack on Titan (1 and 2)
Naruto
DB kakarot
Scarlet Nexus
One piece
Demon Slayer
Just to name a few. (I picked these, because they have a japanese component, for if and when you start adding those.)
? Are you doing a reset?
How big is the model?
Also, I noticed that GIT was down for a moment this morning. Made me realize, there is no apparent way to contact you if shit went south? Do you happen to have some type of link, fan email, or alternative in case of?
@mrq
Most importantly, where are you at with data? I realized that of the links I provided you, it only in total amounted to about 5 hrs, which, if we need massive amounts, is pratically nothing. Do you have any goals for how much data you want ie a tracker of sorts? Maybe make an issue?
Also, in relation to this problem, have you heard of Spleeter, or relevant software? Basically, it seperates vocals from an audio track. Based on Hgt1778's suggestion, I was wondering if we could take anime, and run it through something like Spleeter, to then have clean audio. I figure that this might help fill the data void? I am playing around with software at the moment, and will let you know how well it works. The only flaws I see are that the voices for a particular anime would have to be "sorted" out, but I believe whisper can do?
Anyways, good shit. I've got more voicelines on the way.
https://vocaroo.com/19wD5o3Lvsz4 - Original
https://vocaroo.com/14xGpSo2ivbr - Vocals separated
For very little finetuning, it is actually VERY impressive. Do you think this would work? (It would allow you to utilize not only any anime, but even beyond that, any show...
This was run using Spleeter
An LR/optimizer reset just discards the metadata used for training while retaining the actual model. This way, the iteration count is reset to zero, and the LR schedule restarts from the beginning, hence the LR restart.
LR restarts help jostle any stuck weights that may not get resolved from just bruteforce training with really low LR rates, especially when adding in more data to a model that cannot yet generalize.
Can't really check, since the model + optimizer states from DeepSpeed are bfloat16 as well, and not the default fp32 weights typical with a torch model. They're 2.2GiB each for the NAR and the AR, but I think exporting them will get it down to 500MiB each? I can't remember.
There's a weird issue that seems to come here and there where either Gitea itself, or the VM that Gitea is running in, will shit the bed. It's such a niche thing that I can't really diagnose, but restarting the VM fixes it.
64138 samples, 250 speakers, 139865 seconds of audio.
I think in a very, very, very narrow pinch, it's fine, but training is very sensitive to any and all audio quirks in a speaker's voice. I imagine if the quirks itself are isolated to a specific voice it wouldn't be too big of a deal, but if those quirks are present in a significant portion of the dataset, then it more than likely will taint the model in some shape or form.
Maybe when the dataset itself is larger I can consider it, as there'd be less fear of it muddying things up, but it should be used sparingly for now.
Right now though, I'm just letting the model bake again with the new data, and seeing if the older portions of the dataset catches up finally.
I'm biting the bullet and dumping in LibriTTS
clean-100(247 speakers, 30k unsegmented lines, don't have an idea about duration yet or final line count).I'm getting really worried that I'm going to have to dump the weights and start from scratch due to it overtraining solely from the text phonemes itself. From evaluation output, I had something sourced from SA2 Knuckles outputted with SA2 Rouge's voice, and the only explanation I have for it is that it's overtraining on the text phonemes itself.
iunno, I'm probably just overreacting over a flaw, but I either need to take the loss and dump three weeks of training or risk it getting worse and having to dump it later in the line. I honestly don't remember how long it did take for it to even get to something with a semblance of speech with a tiny dataset, so that's probably the only reason I'm against dumping it, since even bad weights are better than no weights.
@mrq
Is the size the general concern atm?
Would you rather have more clean game data?
If so, try https://www.sounds-resource.com/ . It has extracted audio assets from proabably 70% of games you could think of,which means all clean. And it is sorted by language, character. If it meets your standards, it probably has more than you could use.
For a more specific example, look at one like https://www.sounds-resource.com/xbox/cars/
Check out lightning mcqueens voice pack. Most of the packs will be organized as such (and as you can see, each game should have a decent abundance.)
If you are going to use LibriTTS then you should also check out HiFi-TTS which is a smaller but higher quality (sampled at 44.1 kHz) dataset as that's what tortoise also uses in addition to LibriTTS since that might be better for higher quality output.
also if you were going to train a multi-lingural model like Valle-X than this has a lot of dataset for various different languages.
Twice I had what I was going to say eaten away. I already spent maybe 45 minutes to an hour, so I'm keeping it as brief as I can. Apologies if it comes off rather curt.
Yes, in an odd way.
My concern for the "old" data not being up to par with the new one seems to be moreso from those speakers' line counts being much bigger than the line counts the "new" data. I'm not sure where the fix for it lies, so I'm just going to ignore it for now.
Already have.
Yeesh.
I'll keep it in mind. At that point though, I might as well dump in more LibreTTS.
Training with the
clean-100portion seems to be doing fine; it didn't outright decimate my loss/accuracy metrics, so I guess the model itself is in good standings with not overfitting. The evaluation output even at an epoch doesn't seem completely terrible; definite room for improvement, but it at least is trying.Sort of off-topic but Microsoft just published Natural Speech 2 which seems to be a significant improvement over VALLE architecture. A short skim through of the paper it seems to be a latent diffusion model which might make it slower than VALLE(?). It also seems that zero-shot prompting would be much easier and better since it only require audio and tortoise like 11Labs.
The biggest innovation in this paper is that they use a continuous vector audio codec compared to discrete tokens.
It seems to be simpler since the diffusion model replaces the two stage approach of VALLE. It also can do singing (though not as natural as regular speech) which is pretty neat (though it needs to be trained with singing in its dataset obviously).
It probably be awhile before any good open-source reproduction will come out like VALLE is right now but it seems useful to an eye on it for now :)
https://speechresearch.github.io/naturalspeech2/
though lucidrain already started with his pytorch implementation because he's insane lol
mmm, yeah I definitely won't try and tackle that. I'll let the real experts deal with maturing it, and hopefully someone with the actual compute to play around with it and homebrewing a model.
From a cursory glance at the paper, it does seem to address my "concerns" I had with VALL-E with it's "haha lets throw some quantized waveforms at it and see how it learns from it" approach that makes VALL-E, in a hyper-reductionist manner, a sophisticated MIDI synthesizer.
However, the more I look at the paper, the more turned off I feel about it.
It's reintroducing the problems I did have with TorToiSe with more moving parts, still relying on conditioning latents (or at least, an analog to it). Now there has to be a model for encoding phonemes AND the pitch/duration predictor AND the speech prompt encoder. Yeesh. Not to mention the paper says the sourced audio is sampled at 16KHz. I understand the intent, as it effectively serves as an inherent way to squash out any unwanted sound from the waveform by narrowing the bandwidth, but it's still a quality drop somewhere, which I feel is a bit of what TorToiSe suffers from too. Relying on latent vectors instead of the input waveform also pretty much erases any hope for voices with intentional quirks like SHODAN or GLaDOS from being reproduced with it. VALL-E at least has that saving grace from working on the actual waveform itself, and can reproduce all acoustic conditions.
The training dataset seems to leave a lot to be desired too. The paper mentions the dataset is 44K hours, which at first seemed like it just means the new method is just that more efficient, but later the paper mentions
"our model is still underfitting and longer training will result in better performance". Like, they mention that a large, large dataset is practically necessary for good TTS, but they just don't quite do that.The demo also leaves a lot to be desired. At first, it sounds better than VALL-E, as VALL-E has that slight quantize crust that I'm all too familiar with. But, I checked back with the original demo page, and that crust is missing. It's funny, since the paper mentions they
"directly collect some audio samples from its demo page for comparison". Ignoring that, the speech seems rather stilted for it being "natural".I'll give it to the singing, though. While I'm sure VALL-E could reproduce singing of some kind (with what I imagine is better annotating the input text), but currently it doesn't, and for all I know it might very well not be able to. But, I think if anyone wants something that sings, they'd just use a VITS solution, at least from all the prattling I've heard about it in passing.
iunno, I'm trying not to be a hater, and it definitely is neat seeing that in the span of what, a few months from VALL-E, and much shorter from VALL-E X, there's already a contender to replace it. I'm sure the lucidrains implementation will accomplish something, especially seeing it's sponsored, and I'll definitely play around with it if something realizes from it.
But, my impressions of it so far are just... flaccid, and at that point I'd just use TorToiSe over it.
In other news, I don't have much of a progress update. Training seems to need at least another week at this rate. It's dawning more and more on me that it might take a really long time to train the model until it gets something adequate, and the temptation to just rent something like an 8x4090 machine is creeping up on me, I think for like $6/hr. I think my only setback (besides the obvious inevitable money pit) is that I already kind of forgot the exact procedure to get training under a docker container working, and I can't be assed to play around with docker files first.
Since I don't really got anywhere else to mention it, I think I squashed the error 500 bugs. I'm not sure why it happened recently, but fuck SystemD. I had to use
coreadmin my global zone to disable core dumping, which coredumps never ever matter for me anyways.In quasi-related news, I'm leveraging LibriTTS's
test-cleandataset to serve as an actual validation dataset, to gauge how well the model is at generalizing speech (the crux of zero-shot). I should have done it much, much earlier, to better gauge how things are going over time, but oh well. Training this monster of a batch is currently at iteration 19915, epoch 53ish, so I got probably a half-week left before deciding when to add more data in. I might just cave and dump theclean-360dataset into it then, iunno.Just moreso wanted to mention the error 500 issue being resolved, hopefully.
I do have this, I suppose as a very rough zero-shot test: output / reference
It's kind of cute in a weird way seeing it try and speak. It's definitely getting there, but a lot of the other validation output leaves a lot to be desired.
Bit the bullet yesterday; transcribed the
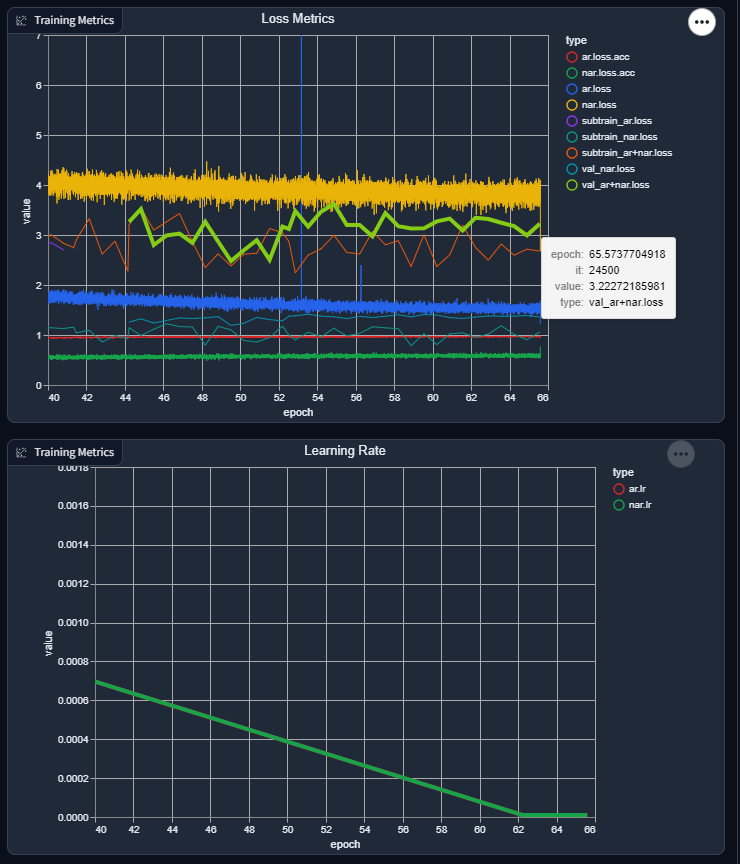
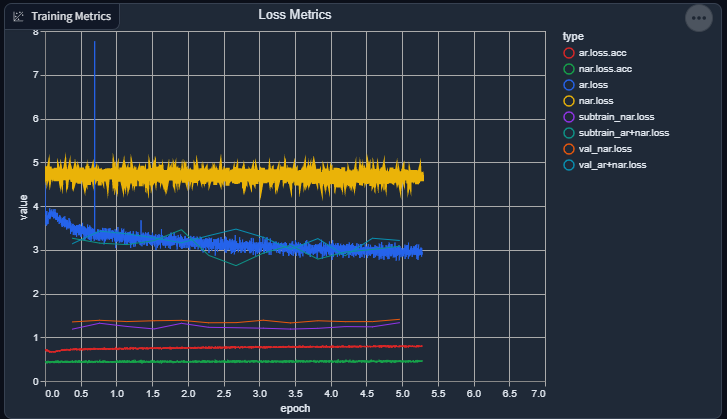
train-360LibriTTS (sub)dataset, putting me at a total of 116 hours, 167520 lines (total, actual dataset could be more, but I dropped Westwood's Blade Runner and FFXII lines since I felt they weren't really worth training against for the quality they were at).I'm starting to be at wit's end, though. The metrics towards the end of the last batch stagnated, and the current batch seems pretty stagnated too, even with a new LR restart, so I don't know. I'll have to keep an eye on it for a few days, but I'm worried that no amount of more training and data will help.
End of the last batch:
Current progress with the new batch:
Have you seen https://github.com/Fictiverse/bark? The singing is pretty neat, and the inference time is quite fast.
Seen it. I mentioned some thoughts here, but I'll mention my current thoughts:
The last one is my biggest problem. desu I shouldn't really bother with it right now if it can't do unrestricted voice cloning (or at least, bothering trying to cobble together a way to provide your own voice
.npzs)As a slight progress update, I might have fucked up by setting my de-facto batch size (bs=16, ga=16). I have a hunch that I started getting worse results from training after I optimized the VRAM usage and increasing my settings from bs=4, ga=4. Can't really make much conclusions right now, as I just need to wait and see before making more judgments on if it works or not.
Although, I'm tempted to try the quarter sized models again. Technically I think they can be fine, since I think I fixed it outputting the combined AR+NAR audio after I gave up on it, and it'd be much, much faster to train.
In case I keel over and die or go AWOL, I'm putting my current progress and dataset onto a HuggingFace dataset repo. It'll also help me whenever I finally cave and rent out an actual machine to train this bitch on.
Also, the site should be actually fixed now. I migrated the gitea setup from an LX-brand Ubuntu zone into a normal SmartOS VM (because SystemD fucking sucks and won't tell me what's wrong), and I was able to narrow down it was
1040: Too Many Connectionsissue from using a neglected SQL VM.Apologies for it being down however many times, I guess the increase in traffic caused issues. I'm not sure why though, as I have a MediaWiki on the same machine but in a different VM that gets 5x the traffic here and it hasn't given me these issues.
Oh, actually, there is a repo for it: https://github.com/serp-ai/bark-with-voice-clone
I'll play around with it. If it proves favorable then I guess I won't need VALL-E.
I tried that fork and I the voice replication is comparable to using the non-finetuned custom voice of Tortoise in that it kind of replicate the voice of characters but it doesn't do well with anything outside of audiobook type voices... still pretty neat at least.
I whipped up a small script to play around with it and, while I had zero hitches actually getting it to run (which in post I guess I got lucky, apparently people have had it not work given the issues).
Terrible results. I tried a segment of SA2 Knuckles I already cracked out and the result is unusable. I also used a default provided speaker voice and it's mostly unusable. I'm not sure if it's related to using the small models (as this was running on my 2060, the 4070TI is still training) or not, but I might take a crack at it later with the non-small model.
If it's something inherently wrong with the repo, then at least I got an idea on generating the .npz speaker files, and the code for that can live in this repo.
I suppose I'll still add it in. I have an idea on how I would extend backbends, so if anything it'll be for that.
mrq it's really sad that you are the entire hope for the open source TTS community right now and you are using a 4070. If you open a patreon, I'll donate $50 towards your compute costs and I think some others would too.
AIVC has Bark integration. I don't really need to use any of the forks, as:
Relying on the main repo just seems better, as I don't have to wait for a fork maintainer to merge upstream commits.
It's extremely kludgy, as it requires your voices to already be transcribed with Whisper in order to use them (because generating speaker files requires a text transcription anyways). Output sounds puke at best and dogshit at worse, so I don't actually think it should be used.
But if you do want to toy with it:
git clone https://github.com/suno-ai/bark ./modules/barkpip3 install -e ./modules/barkstart.sh --tts-backend='bark'This way is required because I don't have a way to inject speaker prompt paths anywhere outside of the default one, and this way will keep some uniformity between OS's (implying that I have tested this on Windows, much less, expect it to work under Windows, much less, care if it does at the moment). This also implies DirectML won't get any love, it seems bark loves to use flags like
use_gpu=Truerather thandevice='cuda'.A ton of settings aren't use, the temperature slider works for both
text_tempandwaveform_temp, because I can't be assed to modify the existinggeneration_proxyfunction on the web UI side. You are required to have already transcribed your target voice in the web UI. When generating, it'll pick a random transcription to use as the source. I do not have a convenient way to "select" a prompt.'I figured I might as well get it added in and wait for things to mature. This will not replace TorToiSe, like, at all.
Nah, I'm just being both stingy and stubborn. Money isn't an issue, as it hasn't been for several of my endeavors. I also refuse to spend any more money on Ngreedia cards, much less, another GPU (I'm still stuck with a 2060, two 6800XTs, and now this 4070Ti I'm feeling some remorse for).
I'll be fine.
I had a pretty lengthy progress report (despite framing it as brief), but I felt it was much ado about nothing, and might have painted too high of an expectation that I keep forgetting that I make and forget that I break. Anyways:
The above changes has me not stressing so much about training now. I just need to remember to stop making the same mistakes again and again.
And when this run is over (I am not making any promises):
iunno, Bark sounding so terrible seems to put more pressure on getting this model trained. I don't know how it can sound so bad. Even the output for the past month of training at least maintained some semblance of the source. But Bark didn't sound anything like the demos.
Again, I'd like to consider contributing some money towards the cloud compute costs if possible. Opening a patreon would be good.
Slight progress report again: things are going swimmingly again. Losses are going down (not as fast as apparent as I wish, but still going down), and accuracies are going up (again, not as fast as I wish).
I suppose, given how the evaluation / validation output consistently sounds, it's doing a great job at replicating the acoustic "environment" of a speaker (good), but still has a lot more to go in order to consistently synthesize speech.
I suppose that's my #\1 worry now: trying to nudge it in the right direction to start prioritizing speech synthesis itself rather than just deriving acoustics. Sure, it's far, far, far, far, far better that it's that way (solving acoustics, then trying to solve speech, rather than solving speech, then trying to have it clone). But for only figuring out how to better goad it into solving speech synthesis more rather than solving for acoustics replicating is what I should focus more on.
I guess when this batch is done (probably next week, at this rate), I'll:
Outputs (evaluation output):
Progress report: since my metrics seemed to have flatlined after running through the LR schedule, I went ahead and:
To spare the boring details, my losses jumped back up a bit, but not as bad as every other step-restart. I'm not sure what to make of it.
It'd be nice if I do have a way to dynamically swap between the two datasets (larger batch size but smaller data, and smaller batchsize but bigger data) to try and avoid the model from fixating against lengths, but I need a bigger brain (or the attention) to do that.
It just kinda blows (not in a good way) that I still haven't got something decent to show for it outside of some validation clips I manage to pick out amongst the clips that sounds okay but not that great. I suppose as long as TorToiSe is still serviceable, then it's not that big of a boon to stress over.
iunno, I feel like I'm going back to the FUD phase of training cycle, where I'm fretting over probably everything that could be wrong. It's not as bad as the other dozens of times, at least.
Also I failed to realize I still have the
train-other-500dataset for LibriTTS, so I'll let my 2060 crunch at it over the next three days (since I thinktrain-clean-360took a day and a half). By that time:I think I've fudged up with underestimating how crucial it is to just have a large dataset, rather than just a narrower but more real-world one.
I made the mistake of slapping my 2x6800XTs back into my training system to see how it would fare: it did not. For some reason training was completely impossible under ROCm; it kept throwing errors during the forward pass about tensors being wrong or whatever, so I guess I can't really check without devoting a day to it. Oh well.
If you still need more data, I'd recommend checking out the VoxCeleb dataset.
It advertises over 7000 celebrity voices and over 2000 hours of audio, so it's a fairly large one. The dataset references YouTube URLs, and provides frame ranges for relevant utterances (it also has face tracking data, but you can ignore that). The main inconveniences are that there aren't any .wav files to download, so you need to download the relevant audio and then extract the utterances based on the frame numbers, some links may be dead, and utterance transcriptions aren't distributed in the public dataset.
There are two versions of the dataset, VoxCeleb1, which has 150,000+ utterance references from 1251 celebrities, and VoxCeleb2, which has 1,000,000+ utterance references from 6112 celebrities.
Here's where you can get the dataset:
http://mm.kaist.ac.kr/datasets/voxceleb/index.html
Here's some random example videos from the dataset:
https://www.youtube.com/watch?v=0rpfN7wThsg
https://www.youtube.com/watch?v=jUSC4i_eGHs
https://www.youtube.com/watch?v=Tzs_CTbHT9Y
https://www.youtube.com/watch?v=PfcJLmkhGbk
Here's a download script for the dataset if you end up using it:
I was just playing around with vast.ai, a GPU peer sharing service and my first impression is that it works really well. Used it with the paperspace notebook and it seems pretty robust.
You can get a 4090 for 43 cents per hour when I checked, although it varies. Each user has a limit on how many days you can use it consecutive so in that regard it seems a lot more dependable than paperspace.
This could be a way to really get a nice model going. Fuck I'd even chip in a couple of bucks.
Also, are you currently using audiobooks for training? I composed a 900 hour Belgian Dutch dataset just from ripping audiobooks from Storytel using this, using a free trial as well, so it didn't even cost me anything This seems like a no-brainer seeing the original creator of tortoise also used a lot of audiobooks and this way we can get a chonky dataset in no-time. Just have to download a variety of speakers but that should be much easier in English.
If you want I could make a balanced dataset of male female speakers and send it to you for transcribing. Or run it on my 3060 TI which can run the large-v2 model using whisperx's v3 branch.
Finally, to transcribe my dataset I wrote a script which takes the word-level timestamps that whisperx spits out and merges these together to form natural sentences between a given minimum and maximum length. All you have to do is then slice your dataset using ffmpeg. If it's any help to you, I could clean it up (because it was written at 3 AM) and post it here.
I meant to send this earlier, but I kept getting sidetracked. Oops.
Mmm, my only qualm with that is:
I could be smart and diarize during transcription, and discard any output that reports multiple speakers, but I honestly don't know how much I can trust it, as I tried using it for something completely unrelated to the project, and it failed me.
I'll keep it in mind when I need to feed more data, but I think I hit the point of diminishing returns for adding more data:
LibriTTS's
train-other-500has been transcribed, quantized, and phonemized, and some changes to the data loading procedure, I am now at:543478 samples536512 samples192100 (there's only like, 7k samples above this mark, I can't be assed to test it with it higher right now as I worry it'll break the balance.)batch size 8 (YUCK. I can't get anything stable at even bs=10 without it OOMing during the backwards pass, which sucks because my card can definitely have a bigger batch size without harming the throughput all that much).batch size 16 (I pulled every remaining optimization out of my ass to get it stable)Despite the dataset size 3xing (some of that does have to do with increasing the maximum phoneme length), my existing losses and accuracies haven't taken that much of a hit. I suppose this is a good sign, as the model hasn't been overfitting for the existing dataset, and can perform fine against new data (although that was evident when the validation output is at-parity with the training dataset).
So I'm a bit loss:
And coincidentally, my next set of notes:
I've used runpod before to get a rough idea on whether to go balls deep into a 4090 or if a 4070TI is "good enough", before:
My only issues with it are:
nvcc-cuda-12-1or something). This used to be a bit of a bigger pain with more outdated CUDA libraries and Python libs, but the supplied Docker image has been updated to be less of a pain.and most importantly:
Training doesn't seem to actually use multiple GPUs
I noticed this with my 2x6800XTs, but didn't think much of it, but I tried this morning with 2x4090s and:
total dataset size / (batch size * GPUs)don't change between single and distributed.So I'm at a loss for that too. I don't really have an idea how to diagnose it, and my only good lead is to dig through DL Art School to see how it does it, as I don't think DeepSpeed has any actual examples of it being used like the first implementation does it.
Even then, just a single 4090 didn't seem to offer that much of an uplift to warrant just throwing everything onto a rented server and stressing even more about getting the most out of it. Sure, I can semi-comfortably set the batch size to 24 over 8 with the current settings, but the iteration rate is about 2x the iteration rate I'm getting now, so it's more like 1.3x the throughput (I don't know if there is also from some penalty of it being in Docker vs bare metal). So I suppose I did make the sensible move of not paying twice as much for a 4090 over my 4070Ti (but I'm still aching from being VRAM starved).
In short, I'm a bit at a loss.
So what's the limiting factor in just using that 60k hour dataset (I'm guessing compute)? As for the balancing problem. Can we not just restart the dataset from scratch and just alternate between male and female spoken audiobooks (like I said in my previous post)? Maybe trim each one so it has a max length of 5 hours? That would balance all the speakers. I believe tortoise's creator used 2 hour long audiobooks to create most of his 50k hour dataset. You could start with 5k hours, that's still a 10X increase. Also just to check, you're using the V3 branch of whisperX right? That thing is a lot faster than the main branch and lowers VRAM usage.
As for the batching problem, what exactly are you trying to solve? Is it just slicing segments to different lengths that you're after? My bad if these are braindead questions.
In order:
No real point in it, as even not-so-good weights are better than a clean slate. I've already done LR/optimizer restarts a lot anyways as I kept adding more and more (except the last one), so it's sort of already been "restarted", save for the new weights.
Isn't so much of a concern. The speaker balancing from the original implementation should be good enough for "balancing".
The data loader that assembles the batches to train against is fairly naïve in terms of trying to balance the actual size in memory it takes.
My initial solution was to have a better data loader that could aim for a target "token" length, which I believe is what the newer implementation does (and the VALL-E paper might do, as it says it's batch size is by acoustic token length).
Now, I'm pretty sure this is actually a bit of a red herring, as I've sussed out some causes:
So in reality I don't think I need to touch the data loader.
I tried it before, but it didn't give much of an uplift on smaller segments, which was the case for using whisperX's batching (it didn't get any faster on small segments). Also, I would need to fiddle around with re-parsing the output, as v3 breaks compat.
I think training should be fine if I just let it bake at s low, low LR now and let it do its thing for... however much longer.
However, I'm having doubts again. I forgot TorToiSe was trained on 50k hours and, for what it's worth, is still a damn decent model, while the newer implementation 's homebrewed model was on ~550h or so. My concern of "visiting things more often" is probably just an issue I should only really solve it by longer training times. Mmm...
I tried training the other fancy Valle implementation with a large data I crawled (~10k). After around 5m steps, the audio quality is nowhere near Tortoise. It is also pretty unstable. It might be just me being stupid but I have my qualm that this model will never be like good old
Also, I say, sitting your ass and waiting for a couple of weeks is the best engineering effort you'd do to shine in better results. ::
That's pretty much how I felt when I messed with it after the weights got posted for the homebrewed model; it left a lot to be desired and it was just better to use TorToiSe + finetunes than wrestle with it.
My main cope is that it's just flawed from oversights with the implementation that aren't issues with the one I forked (namely shuffling for random utterances as the input prompt rather than use the target audio as the input prompt).
I'm quite happy with what evaluation / validation output it does produce, at least, before the accuracy dropped from increasing the dataset.
That's what I keep telling myself, and keep having a hard time actually doing it. I'm just dreadfully impatient.
I keep looking at the metrics stagnating and worry that I need to change something: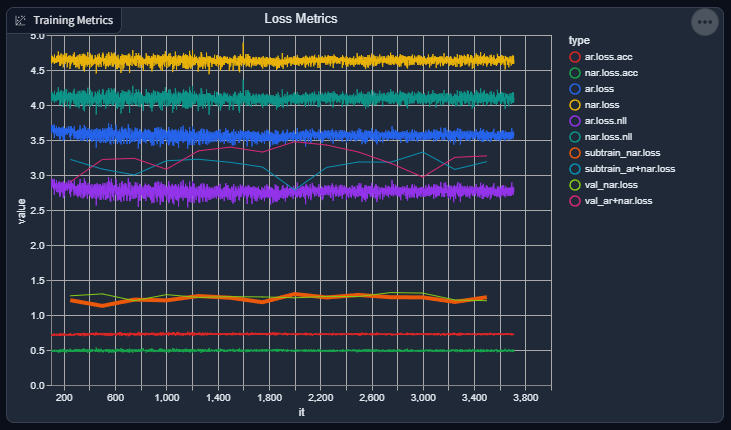
When in reality it's probably just from my LR being too high, and I just need to wait for the LR to decay low enough and have it sit there to see any movement.
Mmm... I think I fucked up the training script.
There's been no movement for the past few days, and I removed the
train-other-500dataset and, while the loss / accuracies moved, it still isn't changing over time. I even tested with quarter sized models and there's no movement either, so I definitely botched something.I'm so mad since I effectively wasted another 3-4 days.
Seemed to have been an odd mix between the DeepSpeed version I had, and moving the engine/models between CPU and GPU, which I guess actually fucks shit up. Ugh.
Well that's good news I guess, those metrics did look pretty bad
Thank you for your work. I've been on the lifeiteng version, and also been failing to get any good results. I was hoping to try your version next, but I'm unable to find a script that you used to preprocess the libritts dataset. Like I see the scripts to download and quantize librilight-tts but not LibriTTS.
They still look pretty bad 1.5 epochs in, but it at least seems to be showing it's "learning" from the gradient norms getting smaller, and a random spike in the losses.
Things should be stable enough to train with my fork. I just haven't been actively advising anyone to train with it given it's quite the pill to homebrew (and I still actually need to figure out why multi-GPU training doesn't seem to be working).
Right. I forgot to re-adapt the script I used for re-labelling LibriTTS with the one I cobbled to test on runpod instances.
I can't quite remember how much it really does help to properly transcribe / slice using AIVC's web UI over just shortcutting it with already provided transcriptions + without slicing the utterances down. I think at the end of the day it shouldn't matter all that much now from all the VRAM-savings I pulled out of my ass, but if you're after the entire training+validation LibriTTS, I can just provide the dataset for it itself when I get a chance.
Dreaded progress report: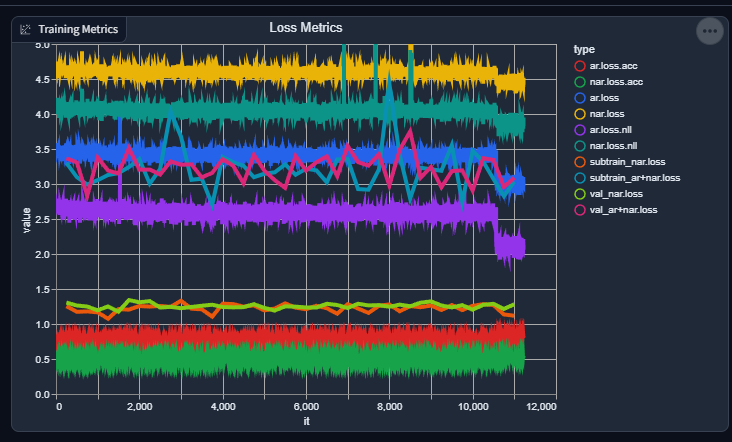
train-other-500subset, and the average loss per iteration going down from seeing the old data moretrain-other-500in maybe shows some good signs that it did at least do something to the model? (COPIUM).It also doesn't help I'm split between a few other things I want to work on, dividing my attention even further.
Oh well. I'll judge things again in another week.
I'll just do my weekly evaluation a little bit ahead of time.
I think the AR fried.
Despite the loss slowly going down, the range between the metrics are even more chaotic, and the evaluation / validation output sounds awful, it managed to be worse before I meddled and added in
train-other-500.I do have backups from every time before I modified the dataset, but I don't know if I should bother taking the risk of it frying again if it could also be from all the other previous re-use of the weights over and over and over again.
But I think at this point, after constantly reusing weights over and over again every time the dataset grew, I should just take a page from LLaMa-variant trainings and start from scratch with a small model, then after getting something actually usable, do the big model. I had one of my typical lists for cope points on why, but they just boil down to it being much, much, much faster to train it (eyeballing it, it's like 6x throughput).
Sucks it's about two (three? I can't remember desu) months just to realize the weights are doomed, but you got to break some eggs. A lot of trial and errors and errors and errors are needed to nail out all the issues to get it to be easy for off-the-shelf cards to train off of.
I just worry that this is going to be another timesink where quarter-sized models just aren't viable at all. However, the metrics are looking pretty good for being at about epoch 3.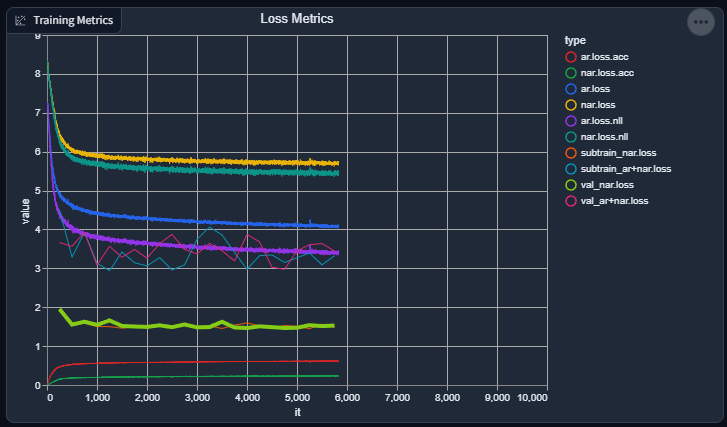
Actual weekly progress report:
I feel very, very stupid for burning so much time being stubborn. Restarting the weights was actually the correct call, as the results are looking pretty good. This is with training a quarter sized model over three days, a little over 40 epoch and 40000 iterations with the dataset before adding in the
train-other-500portion:For a quarter sized model and a few days, it's pretty good. However, I'm not sure if it's because of the model size, but I cannot go any lower than AR loss=~3.6, no matter what LR I leave it running at (I tried high, I tried tiny, I tried average, it was left running decaying between the two in hopes it'll find a sweet spot, and no go).
So, I think it was last night, I grew a wild hair and restarted the training, but with the
train-other-500dataset included to, feeding the beast my most complete dataset, and:In just 7000 iterations and a little under three epochs, it's already at the same progress as it was with the previous test run, and seems it can breach the AR loss=~3.6 floor. My only worry is that my LR is still too high, as I started from a much, much, much higher peak of 1.5e-3.
I haven't gotten a chance to start an Xorg session again and check the evaluation / validation output of either models, but given the metrics, I can assume they're decent, but not quite there yet, as the accuracies are still not where I know they shine at.
Also, I guess this confirms my doubts over a large dataset over "muh epochs", as the importance of epochs wanes the larger the dataset is itself. Which sucks, because now I'm going to have to go back and find more and more and more and more data to feed the beast with, since just adding back in
train-other-500really boosted things given the small model size.I think right now my only fear is that there is a floor of how low the loss can go for a given model size, since it's already looking like it hit that floor again, as the curves are approaching that asymptote.
That actually looks encouraging. I'd give it some more time. Do you have a loss target in mind?
I do however wonder how it would fare if you gave it like 2000 hours worth of speech to train on though. Want me to rip you some copyrighted audiobooks just in case? The alternative would be that librivox dataset. Seems easier than just picking up small bits of audio here and there.
On a sidenote, I really want to know how 11labs does their TTS. Theirs still sound a little better than tortoise's finetuned models. Did they just use tortoise and throw computing power at it you think?
Not necessarily a target loss, but moreso a mix of playing it by ear from the output, and the reported AR accuracy being >90%. I can't remember what loss correlated to it when I was doing longer runs on the smaller datasets, though.
It's a bit of a pickle too, since good output quality is mostly predicated on the AR being up to par; no point in a good NAR if the output from the AR fed into it isn't good.
Seeing how well it performed relative to the epoch count unironically whitepilled me on the whole ordeal of a big dataset. I think it could overcome the lower model parameters, but right now the ~550+ hours is slowly improving now.
If it's not going to be too much of a hassle for you. Huge batches through AIVC (`./start.sh --tts-backend="vall-e") tends to have hiccups while transcribing/timestamping under CUDA I found; ROCm somehow had more stability. Then there's the phonemizing/quantizing step that will hang after a bit of time regardless.
There's the full 60K hours LibriLight dataset, which VALL-E originally was trained on. My only concern is if there's any overlap between it and LibriTTS. I wouldn't want to fuck up my dataset with a sizeable amount of duplicates. I could prune transcriptions with similar strings, but the issue is that LibriTTS is trimmed down, and LibriLight I-believe is one whole piece, so even just relying on the full transcription of a sound file won't do any good. I suppose I could just check for similarities and prune manually, but even then I imagine would be an astronomic task (unless I do embedding vector similarities shit).
Some idle thoughts I have had over the months is that it's definitely it's own thing. From what I remember:
Although again, it's speculation.
https://github.com/facebookresearch/fairseq/blob/main/examples/mms
facebook released some models, not sure how to use it tho
It's right there in the TTS and ASR sections and the finetuning instructions are here.
The ASR might be promising at the very least, but I'm not too sure if it'd be comparable to Whisper in terms of timestamped transcriptions.
The TTS being plain jane TTS and not cloning is expected, and it being VITS is a little bit of a letdown.
Isn't that just for finetuning a wav2vec2 model?
Quick progress update: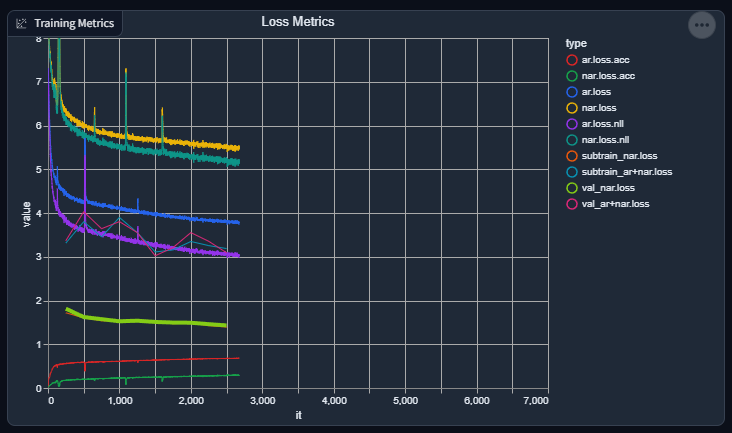
On the full-size model, it's already at the same spot the quarter sized model was at for the same dataset at 7k iterations (of the same effective batch size). I am pleased, but still upset at my stubbornness to do a clean train before.
Thoughts:
Oh well. I'll let it run until Friday before doing more evaluations with it.
I also got around to actually zipping the dataset for anyone interested in training it but don't have a dataset. You just need to extract it into
./training/valle/(or edit thedata_dirpaths) and run:That's what they are, as far as I can tell (the ASR models, I mean).
Hey man, not sure where to throw this in or whether this is viable. One thing I recently "discovered" is that if you produce a TTS clip let say on Tortoise and then feed that into RVC (https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI) the quality is drastically improved and dare I say 11labs esque quality.
See these samples :
Tortoise : https://vocaroo.com/1lQcWB4R0Vaw
RVC : https://vocaroo.com/1eHQe0LruRbz
Tortoise : https://vocaroo.com/1kO4tXnTmqYE
RVC : https://vocaroo.com/1b0FmJI905bw
Obvious caveats : You have to train two different models and the average gpu enjoyer will not like that. But can this be done on the "fly"?
It has crossed my mind to just have TorToiSe (or the other VALL-E homebrewed model) to generate a base clip and throw it into a VITS (or any speech-to-speech) and see how it fares, but it'd require juggling around more models. I'll keep it in mind.
So I found another training issue that I feel stupid for not really catching: I have let my LRs decay too low, or at least decay it too fast: the full-sized model was stagnating at the same AR loss=~3.6 wall, so I played around with the LR and kept it as high as it can go without it frying, and it seemed to have helped get past the barrier. I resumed training the quarter sized model with a similar tactic (with a slightly higher LR, as the quarter sized model can take it for some reason) plus increasing the input prompt duration from 3 seconds to 6 (but having to drop my batch size down), and it's already averaging at an AR loss=~3.45. I'm not sure why I kept forgetting about my decaying LR. 1.0e-4 seems to be the sweet spot for it, which kind of irritates me since it goes against my usual go-to LRs.
OK so I have a 2000 hour audiobook dataset compiled. Didn't take that long to gather but uploading it took forever. It's untranscribed still as well.
Use it if you feel like you're not making progress anymore I guess.
Can I DM you the link in some way? Had to use onedrive since it's 120GB, and onedrive puts personal information in your link apparently.
Sweet. Training seemed to have slow down quite a bit even on a quarter sized model at a pretty high LR of 1.25e-4, enough to where I think it isn't all that viable to continue trying
Shoot it over email to mrq@ecker.tech.
Alright, sent you the link.
Greetings! Thank you for your great work and all these comments resonate with my work on Mockingbird(https://github.com/babysor/MockingBird), an open-source Chinese cloning project, which was modified from RTVC. I appreciate you taking the time to write down all your progress and meaningful thoughts.
Although I haven't been involved in TTS for over a year, your work has reignited my interest in the field. It's amazing how open-source projects can foster continuous progress by bringing together passionate individuals like us. Thank you again and I look forward to potential collaborations in the future!
BTW, I have a large collection of Chinese voice data on my computer, and I also have over 1000 followers who can contribute more datasets. I would love to collaborate or share resources whatever can help on this.
Could have sworn I sent a post here, but I suppose I didn't.
Training is slowly improving over the weekend with a maintained LR of 1.0e-4 on the full-size model; but I don't know if I should keep bothering with it until I get the new additions to the dataset added in.
I did finally get around to listening to the evaluation / validation output yesterday, and it's somewhat solid even at a "low" accuracy of ~70%. Ironically, the quarter-sized model actually sounds better than the full-size model did at the time, but the quarter-sized model has had a ton more iterations into it (and I imagine the larger batch size, and it being able to use a slightly higher LR, are favoring it moreso).
I'll get around to cherry picking the examples, since some were decent and some weren't as decent, between the two models, but it seemed consistently "decent" for the given progress. This week has me quite busy with a bunch of other endeavors overlapping at once.
Received. I have it all on my training system, just need to spend some time to get the transcription going.
Looks pretty nice and robust; unless I'm mistaken, it's just an encoder + mel synthesizer + vocoder? The example output seems pretty decent for what it's worth.
Glad my ramblings managed to make its way out of my own sphere here. What started as a simple batch of QoL improvements for TorToiSe turned into quite the endeavor. I felt a lot of the layman knowledge of it all is either outright nonexistent or woven in papers or implementations. I still don't feel that qualified, but I suppose my understanding is better than nothing.
Right. I keep forgetting to toy around with my passing thoughts for getting a "VALL-E X" implementation (which is just annotating with a language token to better hint at which language is inferenced).
I'll keep it in mind whenever I do get around to needing to source more voice data, although who knows when that'll be; I don't expect the experiments in a stapled on "VALL-E X" implementation is going to be all that fruitful for a while when I get around to it.
https://google.github.io/df-conformer/librittsr/
Consider replacing LibriTTS with this if you haven't
Will do.
I'm not sure if I should bother trying to use the faster-whisper-backed WhisperX, since shorter clips don't really benefit from faster transcription times.
There's a relatively new TTS called Balacoon, aimed at low end devices. I tried it out on my desktop and it was faster than RT. I'm not sure to what degree everything is open source, but the dev is claiming 50x inference speed improvement on CPUs and talks about some of the optimizations they made to do so. Maybe there's some insights to glean.
https://balacoon.com/blog/on-device/
https://github.com/balacoon/balacoon.github.io
How was the quality?
Neat.
Seems predicated on very, very small parameter counts, which with my test of the quarter-sized one seemingly outperforming the fullsize one I mentioned the other day (week?), I guess it's believable.
Ugh.
Ugh. Ruined.
There seems to be no samples, but the HuggingFace space (https://huggingface.co/spaces/balacoon/tts) works to generate some of my own (catbox because I can't be assed to upload them to vocaroo, I am very uncreative with test prompts, and this is the one that I tested against ad nauseum for TorToiSe finetunes):
For what it's worth, it's decent I suppose. The documentation seems to suggest it uses an IPA-based approach (good) and you can pretty much coerce the input text to do what you want.
For what it's worth, as a plain Jane TTS system, it works. It's not a voice cloner (on the surface, unless it's like Bark), so I don't have any interest in it. I suppose it has its own niche as a lightweight-yet-competent TTS system.
I also forgot to do my weekly assessment. Uhhh...
The loss on the fullsized model is down to AR loss=~3.1 (I saw it dip to 2.9 earlier) and an accuracy wavering between 76% and 80% on average. I suppose my issue before was having too low of an LR, and I suppose DeepSpeed will do loss scaling according to the gradient norm, so it compounded to effectively useless training over time.
I forgot to comb through my samples, last week kept me preoccupied in other endeavors. I would have grabbed more samples the other day (week?), but Xorg seems to not want to work again, as SDDM/Plasma will return a 640x480 screen and no GUI elements, and I keep forgetting to yank out my 6800XT since I remember it would give me grief for not booting it up in a specific configuration, so I just have the normal model being baked until I remember to devote some time to get Xorg cooperating. (I need Xorg because I can't be assed to mount my SMBv1 share and Dolphin has it Just Working when I open the shares).
I was catching up on the thread and wondering if there was a reason for not using the LibriLight dataset until I saw you mention
This shouldn't be an issue, since both datasets provide speakers' Librivox unique speaker ID. LibriTTS_R has a comprehensive list of the speaker IDs in a file called SPEAKERS.txt, and LibriLight is structured like LibriSpeech, so uses the speaker ID as a directory name:
It should be a simple matter to prune any duplicate speaker IDs in the LibriLight dataset- and that would at worst add 5500 additional speakers and tens of thousands of hours of audio.
Oh duh, why didn't I think of that. I can probably make do with merging speakers but not book IDs then.
In other news, I finally got off my ass to unplug my 6800XT to get Xorg working again, so now I can:
Hearing the outputs again, it's a bit tough to put my finger on where the issues lies. Yes, the AR itself is definitely flawed, but it's a given since the AR is only responsible for the first residuals. The NAR still sounds pretty accurate, but that's also a given, since it's responsible for the 7/8ths of the sound itself.
Fullsize Samples:
Quartersize Samples (sounds like poop desu compared to the fullsize now):
The validation also seems to change a little dramatically given the input prompt fed to it, so that's a little concerning:
I don't know, I kind of feel these are a bit of a regression from before I botched the model with
train-other-500(naturally, since that model's loss was pretty low / the accuracy was pretty high), but it's validation output does sound better in that it's forming actual words at the very least.The one thing I can't recall if I ever mentioned that I prefer with VALL-E over anything else that uses the magic cope of "representing" traits of a voice, is that VALL-E will learn every acoustic trait of a voice its trained against. This is evident when I'm training against old crusty voices like from Half-Life or SHODAN from System Shock (which I actually need to find output for), while stuff like TorToiSe or Bark will utterly fail because it's not able to capture the raw acoustics of the voice. It's probably why I'm trying to make it work, since there's no other TTS that actually does this.
Transcribing the 2000 hours has began, since whisperX's v3 (with faster-whisper) just works now. I've updated the repo with the "fixes" (dropping code) so you can use the batch size without needing an HF token now.
Training has resumed after a few days I spent to transcribe the audiobooks + re-quantize the LibriTTS_R dataset. I think I would have been a day ahead of schedule, but I had to reslice-requantize the audiobooks since my +0.02s end offset wasn't actually proper with new-whiserpX. Updating to the new whisperX with the faster-whisper backend seemed really nice for the audiobooks since they're one giant file, so I was able to reap the gains of the bigger batch size. What wasn't so nice was figuring out was hotfixing the web UI to play nice with them being MP3s first and then scrounge to free up as much space on the training machine's SSD. My COPIUM is that the full LibriLight dataset will be a bitch to prepare and will eat up a month just to go through it all, if I grew a wild hair and picked at it.
I think unironically, quantizing the audio through Encodec on my 4070Ti is much slower than quantizing off my 6800XT. It was chugging a little more than usual.
WhisperX emitting word level transcriptions now might give me a wild hair and change how I want to have datasets prepared, to instead just have the main audio quantized, and pick out slices procedurally, since all the timestamps would be there, but iunno, I haven't had any issues with the current method.
New dataset metrics:
At it=195 already (195 * 64 * 16 = 199680 samples, LR=0.001 even though I had it set to something lower) for the quarter sized model: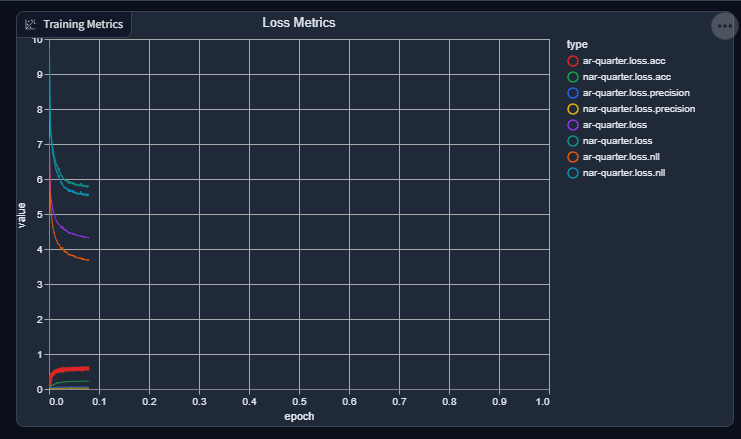
I'm pretty pleased with it already. However, it takes forever to initialize, so I'll probably need to rewrite / fix up the initial data loader, and I came back to it an hour later and the iteration rate dropped to 400s/it, but I should probably restart the machine since it was giving me hell over time as I was doing the dataset preparation process over time.
One thing I did (finally) make note of is the loss scaling to the gradient norm. Usually every other attempt would have the high LR fry it quickly, but I guess the huge crux of the inconsistent training has been the loss scaling either saving me or biting me. I'll need to keep an eye on how it fares with not using an LR scheduler.
I think I should also spend some time playing with the weights I cooked up for both the quarter and full size models. I know they aren't that close to being perfect, but they're at a great spot to fiddle around with them and their zero-shotting (the validation doesn't seem all that degraded compared to the training set), and also finetune them to see how it fares.
The quality is fine, It comes with Mozilla TTS voices, but it's not like tortoise-tts level intonation (think like Google assistant). However, I feel the biggest selling point is that it can produce 4 minutes of audio in <30 secs ON A CPU (my exp).
I think some interesting applications would be using it to quickly prepare large amounts of audio for voice-to-voice changing, or (because it imports voice models from TTS) using HQ voice models from tortoise to create a corpus for training a model that could be inserted into an imported library and leveraging the faster inferences for longer tasks.
Sob. I JUST quantized everything.
If I grow a wild hair and get a hankering to, I guess I'll have to overhaul the entire data loader process, something like:
This is all, also, hoping that it would solve my newly-emergent instability problem in training. Training is a pain in my ass now with the now-4x'd dataset, since it'll either, pretty often, randomly hang and go to a crawl per iteration (I undid my "move the batch off the GPU after a forward but before the backwards pass, that one cope optimization), and training outright killing itself and giving no error (I check htop and my system RAM usage is "fine", but I wouldn't be surprised if it ends up triggering OOM killers).
Training the quarter sized model with the new dataset has stabilized. I don't know whether it's:
I suppose since it's fixed, I don't immediately have to work on cleaning up how the dataset is handled.
In any case, at 1000 iterations, 1024000 samples processed, epoch ~0.32, bs=32 ga=32, the model's loss is averaging at an AR loss of 3.9 and an AR accuracy of 67% (not bothering with reporting the NAR metrics since it's always backwards). At this given point in time for before I added in the donated audiobooks, this is quite impressive. Playing by ear from the validation output, it's semi-decent at replicating the raw acoustics, but language is still subpar, but that's a given since it's nowhere near enough time invested into it. I can at least sleep knowing it's not gonna crash and burn and get into a loop of "uh oh :))) the port for NCCL is already taken :))))) the OOM killer didn't actually gracefully close python :))))))))" and it'll never resolve itself.
I'm still a bit scared that I'm forgetting something. The reported LR is still at 0.001 despite that number not showing up anywhere, since I thought I explicitly set my LR to 1.25e-4 or something. DeepSpeed >=0.92 has the reported gradient norm broken and reports 0.0, which I remember when it reported 0.0, the model wasn't learning (despite it being my fuckup), so it's a bit triggering. And lastly, I feel like my understanding of the loss scaling is a bit off, since that only actually seems to apply to fp16 training and not bfloat16, but it seems to be doing some kind of loss scaling regardless. Oh well.
In slightly other news, I played around with descript-audio-codec just to compare the raw output to Encodec and... I'm disappointed. While I can actually set the target sample rate with just
model.sample_rate = 24_000to reduce the length of the output (I'm guessing the model really is multi-modal and can support arbitrary sample rates, unlike I think Encodec which has specific models for specific sample rates), it still outputs a much larger sequence over Encodec. Given this sample, Encodec yields a sequence of 8x831 codes, while DAC will yield a sequence of 9x885 codes. The extra RVQ layer is a bit of a pain in the ass, since I would have to add a small bit of logic in the NAR model (not that hard, just a bit of a pill), and the extra layer just makes it drastically larger compared to Encodec. Bummer. I was kind of thinking it'd be neat to slot out Encodec for[shiny new toy], but oh well. Maybe in the future when I do actually scale this up to use full-blown 44.1KHz audio as the source, it might eek out a win in comparison to Encodec, but for now I'll shelve it in my mind.I am curious as to how HiFi-Codec fares, as it boasts only 4 RVQ layers over 8, but I'm sure there's some monkey paw of "uh oh, ackshually, this makes our code sequence much much larger :)))))))`. Also, the fact it seems there's only one repo that has weights for it is a little goncering, and the inferencing script is quite kludgy to look at.
I suppose it's a relief that I don't have to bend over backwards to convert over to implement
[epic new meme repo]and burn a week re-quantizing everything and cobbling together code.Regardless, I'll just leave the quarter sized model to cook until it reaches a decent point. Maybe by Sunday I'll evaluate where it's at and do a progress report, and then move onto cooking a full size model and seeing how it fares with the new dataset. I just hope 2272 hours is "good enough" and the model will be very usable, especially from training on stubborn gonsumer hardware.
Babe wake up, another TTS system just dropped for mrq to look at:
https://ai.facebook.com/blog/voicebox-generative-ai-model-speech/
It's not auto-regressive and uses something called 'flow matching'!
There seems to be no weights or even source code yet but the paper seems to go in-depth enough for some guy to replicate it in [Time Frame].
To my ears it sounds very flat... but that might be because it's just audiobook'd.
It being very, very general purpose for being able to do a variety of inputs + infilling seems very, very promising solely in the new model architecture (getting a bit tired of the typical transformer approach). It pretty much combines everything you could possibly need: pure text-based synthesis, reference-based synthesis, speech-to-speech style transfers of VITS/RVC/what-have-you, infilling even. But...
Yeah, it's expected for the one thing Zucc won't share being their voice synthesis because of "muh ethics", especially with this being the holy grail of voice synthesis strictly from its capabilities. Unless there's another leak of the same caliber as the LLaMa one, this isn't ever getting into the layman's hands.
True, true. VALL-E had two implementations spawn from it solely from the paper. Although...
[brand new shiny thing].mmm.
I'll cope with saying it's most likely just from terrible quality audio / stilted reference clips used.
The demo seems nicer than the blogpost since it actually provides the clips unimpeded. I did have a bit of a laugh when I heard the reference clip for the main zero-shot demo (the reference clip has that annoying shit VoiceFixer will have at the end of the clip with the loud sharp noise). Just from a listening to a few of the zero-shot examples, I'm very pleased strictly because it's close to matching the input acoustics of the audio, the big thing I'm autistic about with VALL-E. This also means that it doesn't necessarily fall for the annoying meme TorToiSe / Bark where it'll rely on some intermediary to represent traits of a voice (voice latents / semantic tokens, etc).
I'll have to snoop through the paper for Voicebox itself (the paper for Flow Matching is waaaaaaaaaay over my head to be desu). I'm not too sure how much I can borrow, as I am not an expert, but it could give me some more insight in case I missed something with fixing up the fork.
The 50k multilingual hours it mentions it being trained on makes me think I probably don't even really need to bother much with annotating for specific languages when I add in more to my dataset, but I'll have to comb over the paper to actually see if it does. It should be able to leverage the existing English audio and only really provide enough multilingual data to offer better references for accents and non-language-but-lingual traits, I suppose.
Overall, I'm very pleased with the cherrypicked demo. I wouldn't say I'm hyped for it, since I know we plebs aren't ever getting our hands on it, even with their cope that they can classify audio generated with it, but it's the step in the right direction (in my opinion) with voice synthesis.
Reading the paper:
Ahhhh, there's the rub. It's entirely a model for infilling, and every other feature is after-the-fact ("emergent"). So it's about as raw as VALL-E in the sense there's only the input text as a label, but utilizing only the NAR and new model arch to accomplish infilling. Interesting.
Alright, neat-o. I wonder what shit VALL-E X was needing in the first place to accomplish multilingual-ness outside of a ton more data. I suppose it wouldn't hurt for me to get the Japanese phonemizer back up and dump my Japanese dataset at it then with zero changes to the code (so I won't even need to bother with a language marker token after all).
I'm sobbing. It was too good to be true... stuck using mel spectorgrams...
Jokes aside, I don't think it's an issue at all though. The paper mentions it can very well slot it out for Encodec when it was dick comparing against VALL-E, I think.
And it's shit. At least, the demos are. I didn't think much to check the actual frequency of the demos, but it checks out: they're 16KHz. Another funny note, if you poke in with Inspect Element, you can see some of the provided outputs are tagged like
https://dl.fbaipublicfiles.com/voicebox/webpage/public/assets/orig/audios/zstts_shortlisted/valle/hyp_voc_chunk/5639-40744-0020_0.wav. Now I don't know if they're just calling it VALL-E, but it activates my almonds a bit. There's some other tagged likehttps://dl.fbaipublicfiles.com/voicebox/webpage/public/assets/orig/audios/zstts_shortlisted/extra/hyp_voc_chunk/21_0_0.wavinstead, so who knows.I'm sure you can easily slot out the vocoder, like you can with TorToiSe for BigVGAN, so I don't know why they elected to use their own flavor of HiFi-GAN instead. I hope any unofficial implementation that does rise up catches this. Although, I wonder if that means the training input is restricted to 16KHz. I'll have to cross-reference with what TorToiSe has its mel representations capped at, but it's a bit grim if that's the case. Although, that only sort of matters for existing weights. I'm sure it'll be easy to slot in higher bandwidth audio for homebrewed weights.
Progress report:
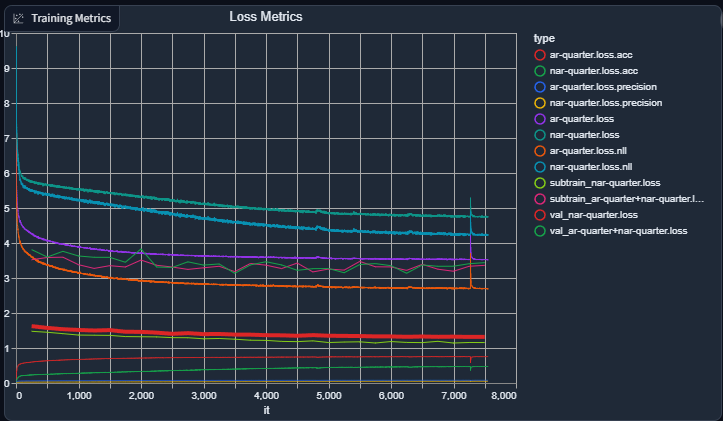
2200+3400+ hours is definitely having the loss go down faster than with the 550+ hour dataset, obviously.I'm a bit scatterbrained though, since I feel a little at unease from how much shuffling around things I have to do. I think I shouldn't keep at the quarter sized model again and I would get better results fondling with baking a full sized model again. If training is stabilized with moar RAM then I suppose I'll pivot back to it.
There's a new neural vocoder that might be worth checking out called 'Vocos'. It was made for bark TTS, and sounds like an improvement to bare EnCodec. The demo doesn't compare it to any other neural vocoders, but it performed very well even at 1.5 kbps. It says it reconstructs audio from EnCodec tokens, so it might be worth checking it out.
https://github.com/charactr-platform/vocos
Neato, this pretty much addresses a concern I had with being Encodec-pilled: TorToiSe was easy to add in audio quality uplifts by slotting out the vocoder, while I imagined there wasn't going to be that easy of a gain, since the quantized audio pretty much is frozen with the model used to encode it. If it really is that seamless to slot out an Encodec-compatible decoder, then that slight issue is solved.
Interdasting. I wonder if this means it either:
Christ, that's actually great. The difference at 1.5kbps between it and Encodec are night and day and makes it rather viable, but even at 3kbps I can't really hear a difference between it and the higher bandwidths. 12kbps still isn't exactly 100% as crisp as the source, but it's practically imperceptible.
I might actually consider using quantizing at 1.5kbps as a theoretical 4~16x throughput increase (this would increases my batch sizes AND reduces the time it needs to even process them). Vocos 1.5kbps is already better than Encodec 6kbps, so regardless it's an improvement. However, that would mean I would have to requantize everything, and that's a bit of a pain.
desu I don't really need that; it lists the mel-based ones (which I guess would be nice to backport it into TorToiSe) but doesn't have any weight here, and the RVQ-based Encodec-alternatives have caveats that pretty much make it hard to go with (like the one I mentioned that ended up having bigger sequences, and the fabled 4-RVQ binned one not being easy to use).
I'm very pleased with the demo, but...
It'll need to wait until probably Sunday when it crunched through one epoch.
The ~3400+ hour-dataset full-sized-model training run seems to be fruitful after throwing in moar RAM into the system, so much so I feel really silly for not doing it. htop always reported there being enough wiggle room, so it never crossed my mind that it was a RAM issue until earlier. I still can't start an Xorg session since it might cause it to OOM in CUDA land, but if it hits 80% accuracy by epoch 1, then that's a great sign.
When it hits one epoch, then I'll do my actual evaluation with Vocos, and if it works out, I'll requantize my audio to 1.5kbps and see how much more of an uplift I can squeeze out for training.
The first epoch has concluded for the fullsize model, I'm not too pleased since training definitely petered off, but at least it's still going down.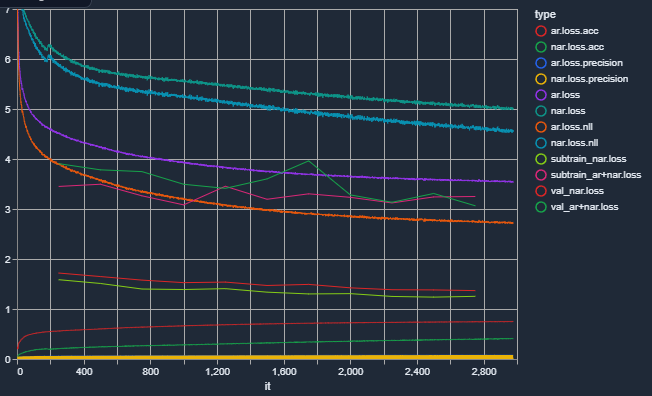
I've crammed Vocos into my fork to be used for decoding. It was a bit tricky since it wasn't so keen on how it wanted the tensor shaped out. It works, but I haven't done much apples-to-apples testing outside of making sure it did decode.
I also was sniffing around seeing how easy it would be to "switch" to 1.5kbps bandwidth for the quantized tokens (for reasons mentioned before), and it turns out (obvious in hindsight):
n_resp_levelsto whatever bandwidth target I want in the Config YAML class, and in theory, going down levels should work for the same model. I hope.I'll see about mucking around with reducing the
n_resp_levelsto suit 1.5kbps / 2 RVQ bins for my hopeful performance gains in training (and in turn inferencing, although in reality inference speeds aren't too terrible, training against HUGE data is the issue). Training for 120 hours is a bitch and I really need to try and find gains, and crossing my finger that Vocos's decoding is true and offers decoding at 1.5kbps to be at parity with 6kbps base Encodec.I'm really not too sure what to make of these results. There's some things that make sense in hindsight, but there's a lot of weird shit with this new run for the quarter-sized model at 1.5kbps / 2 RVQ-bins:
I once again need to check the actual raw output though. I don't want to start an Xorg session mid-epoch and breaking things, and also I don't think the AR's accuracy is high enough for decent audio at the moment. However, the NAR being better than it has been recently has some hopes.
I'm not too sure what would be the best course of action, as this test pretty much invalidated the full-sized 1 epoch training I just did that burnt 120+ hours of training or so. I'm very sure this is the part where I usually say a bunch of shit that either I forget or are just wrong, or talk about things no one really cares about, so I don't think I'll make more comments about it until the training continues with the quarter sized and if Vocos will help bolster things. I'm kinda having difficulties piecing my findings here into something that makes sense, even for me, since I don't even really remember my expectations of it.
Next time you start an Xorg session, can you post some example audio?The last audio from June 6th didn't have the ~3400+ hour-dataset, nor did it have vocos, and I'm curious as to how much of an effect they've had on audio quality.
Oh yeah, I'll see what I can grab. For sure I'll grab the latest examples to test, and I'll load back the old models and do an eval to spit out audio with Vocos.
I've had the quarter-sized model at RVQ-level 2 baking for the week. I kept wanting to go back to the full-sized model but there's something with the initial few hours of training the full-size again with RVQ-level 2 that has me rather just let the quarter size bake for a while.
Also, I might go back to fiddling with Bark again in the UI. When I was trying to figure out the tensor shape Vocos accepted with its provided Bark example, it actually outputted decent, usable audio for me, unlike when I tried it ages ago, it giving me unuseable garbage even with the base repo. Just something to note.
Alrighty, I've eval'd with Vocos. I've labeled them to make them clear so I don't have to keep referring to them by their dataset size + model size + RVQ levels:
model A: the old weights on the ~550+ hour dataset at 8 RVQ bins (reported AR accuracy ~85% / NAR accuracy ~58%)model B: the ~3400+ hour dataset's full-sized weights at 8 RVQ bins (reported AR accuracy ~76% / NAR accuracy ~42%)model B/4: the ~3400+ hour dataset's quarter-sized at 8 RVQ bins (reported AR accuracy ~75% / NAR accuracy ~47%)model C: the ~3400+ hour dataset's quarter-sized weights at 2 RVQ bins (reported AR accuracy ~75% / NAR accuracy ~65%)and... my god are the B models ass.
and the NAR is suspiciously good, despite its training metrics saying otherwise (the evaluation/validation aural-loss reports the NAR's loss to be <1.0). I'm not really sure why the AR is used at this point, but I'll see if it ever improves or not, despite feeling like it's deadweight.Haha...I can't be assed to cherry pick and manually label and upload, so have the entire evaluation / validation output for each models here (MP3 to make it fit under 200MiB, but the effective audio quality shouldn't be perceptible).
Haha, I remember why the NAR isn't solely used. I'm so fucking stupid for forgetting it because I've specifically noted this before in the past:
I suppose the best way to train it would be something like:
I do wonder, though, when it'll be a good time to finetune it. It should probably fix the issue of "bad" clonability, since my goal anyways was just to use a decent base to finetune.
Thanks for throwing me a bone, it's very interesting comparing the validation output of the different models! Despite the accuracy being lower than model A, the audio quality of the validation output for the AR for model C seems remarkably clear (but inconsistently so). I wonder if this is because of vocos? On the other hand, model C's AR+NAR sounded to be worse than A's.
Sounds like it may be the AR then, since the NAR validation output quality on model C is sounds comparable in quality to model A to my ear- with less garbling than either of the B models, but I haven't even read the VALL-E paper so take my opinion for what it's worth.
I also want to remind you that me and many others would help fund cloud compute if a full general model is ever ready to train. IIRC, the other duplication trained for 4 days on an 8xA100 cluster on LibriTTS for 100 epochs- and at some point compute is going to be the bottleneck to getting a model properly trained. But, it sounds like you're still in the experimentation phase and have some kinks to work out.
-Cheers!
I have a theory, but it's pretty much conjecture: since model C is using only 2 RVQ bins (Encodec 1.5kbps) instead of 8 (Encodec 6kbps), there's less for the AR to have to attend to with the input prompt, so it can have "better" output from the AR. This would also explain how it seemed to have been training much, much better in a shorter amount of iterations even compared to the fullsized model (which I still need to get around to trying).
This could also have to do with there being less residuals to muck around with that could be wrong enough to add in some noise. Vocos will make up for the lack of additional residuals, rather than being given worse residuals. I suppose I could re-eval
model Aand snip off RVQ bins 3-8 to "force" it to be at parity withmodel C, but I think it's a little too much work for some extremely niche comparison.A good part is that last line; it's just easier to keep it local because doing this on a rental was always CBT.
God I really need a better place to keep track of "news" outside of this issues thread, but people are reading this somehow, so I suppose it's fine.
Bark
I fixed Bark support with the web UI.
randomvoice to use its included voices.barkunder./modules/to save the.npzfile associated with a voice.VALL-E
I grew a wild hair and pivoted to training a fullsize model again, but with the 2 RVQ bins instead of the 8. I've done some tweaking with DeepSpeed ZeRO's configuration and upped the LR some more to hopefully get it to train "faster", so the throughput should reduce that ~140+ hour ETA for an epoch to... ~120 hours. TQDM's ETA/iteration rate meter varies pretty wildly, despite it being "stable" and using the past X iterations, so I'm not sure how much to believe it.
I hate that I keep pivoting between the two, since, in theory, the quarter sized model is much better for how much more data I can push through + it being smaller means faster inference speeds when it does "realize", but I'm still curious as to how a fullsize will fare, even with how slow it is with inference.
I feel a little bit at unease, I'm not sure if it's because I feel like I wasted most of my weekend sleeping, or that I'm forgetting another crucial detail that'll taint the training (like, how the paper mentioned the AR is fed long input prompts, while I'm being lazy and using a max of 4.5 seconds for the AR and NAR), but I think at this point I need to stop stressing over "wasting time" since this is already a multi-month long endeavor with trial and error.
Hello,
Just wanted to chime in any say this discussion has been a gold mine. I've spent the last hour pouring through all the the updates and discussions.
I've been working on my own implementation of Vall-E for sometime now. I initially started off implementing something like the partial-delayed-pattern defined in MusicGen paper . I wanted to take a stab at implementing a single AR model that can predict all the RVQ channels. This didn't really bear any fruit, so I decided to work on getting Vall-E working.
I started on my own full implementation there since I wasn't too happy with any of the existing implementations (the codebases in itself were messy and lacked things like KV-caching). I still haven't managed to get results as I'm quashing one bug at a time on my own since its from scratch.
But after reading your progress report here, I'm motivated to see my progress through.
In any case I have access to a good chunk of compute (upto 2xA100) on the off chance you're being bottlenecked by compute feel free to let me know. Since this repository is being very active let me know if I can help out in any way.
Edit: I just noticed your comment about not accepting outside compute. Will leave my comment just as a +1 on compute in the future.
Glad it was of some use.
Funny; sometimes in my idle thoughts I think about how I could apply the general structure of VALL-E to repurpose it for music gen, but I imagine if I ever grow a very wild hair and go about it, that paper would be of use. I just imagine it being quite complex in terms of "mapping" a song to an input, and even just getting the data for it.
Yeah; the more I try and think about "how can I get away from this AR+NAR spaghetti", I remember a detail that reminds me there really isn't an alternative to it and being stuck with the synergy of the two, since other VALL-E inspired neural voice synthesis seems to have some caveat when doing away with it (I can't quite recall Bark's stack, but Voicebox seems to be purely NAR, but it still needs a model for the duration of an audio clip).
Now, that paper mentions interleaving the residuals into one dimension, but without it being the clever way they're doing it, I'm not too sure what improvements that would offer. I suppose if I grow a wild hair I can see what it does with just the AR, since the model (and its modules) itself shouldn't require any tweaking, just a interleave-er/deinterleave-er routine. Although, I'm quite curious now if it would offer any improvements.
Yeah; I'm still not too happy with the VALL-E implementation I forked, since all my modifications are a bit spaghetti'd into the trainer, and I can't bring myself to spend a weekend to remake everything to train the model from square one with DeepSpeed (despite my qualms with DeepSpeed, I'm kinda married to it for ZeRO and the quantizers). I still have a gut feeling that there's some bug lurking around that I'll probably only stumble upon when I do rewrite the training script.
mmm, I'll keep it in mind. I have an idea to work around that pesky distributed training bug in dual-GPU systems by having one GPU be responsible for the AR, and another for the NAR, but I need to actually jerryrig the training script to allow that, and to cram back in my 6800XTs into my training system (which, the last time I put one back in, it was a huge ordeal).
In other news, the fullsize model at 2 RVQ bins seems to be very promising*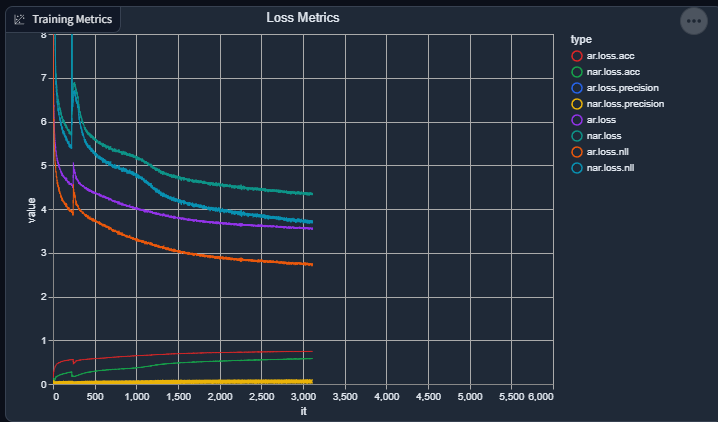
It's only at half an epoch after I think two days(?), but it seems to be going down beyond that pesky floor of around AR loss=3.6 or so, and the accuracy is hovering around 77% so far right now (with a peak of 80%), while the NAR's accuracy is around 62%. (with a peak of like 68%) I checked some samples at it=2500 earlier this morning, and it's decent speech with somewhat decent cloning, better than the quarter sized run. It's just a bit of a pain, since the training process restarted twice, so it's not going to be a clean epoch (I really need to get around to storing the dataloader seed and index it was at to the checkpoint).
...however, the actual quality of the audio seems pretty shit.
If it really is that my ears suddenly hate 2 RVQ bins, then at the absolute worst, I can compromise by using a NAR fit for higher RVQ bins, and thus increasing quality, and this could even be a quarter sized model too. I suppose this is another victory for the AR+NAR stack, since using one model wouldn't have this advantage.
Aside from that, I have my hopes for once.
And I almost had a scare. I was looking at an old copy of my fork, trying to figure out where in the AR does it actually care about more RVQ bin levels, and it actually does in the case of the input prompt here. The scare came because it was showing it was still hard set to
8, but the canonical version has it right, so all is good.If I wanted to, I suppose I could decouple this from the outputted residual levels, so I could either:
Although, I'm not too sure how much of an improvement.
mmm, this isn't necessarily related to the model, but moreso EnCodec in general, but I probably should have done more tests on EnCodec (and Vocos), as I found a teensy little oversight: voices that are "low quality" (robotic ones) tend to have noticeable issues with EnCodec, I'm pretty sure from there being insufficient data to resolve any nuances in the audio. Obviously, increasing the amount of residual layers "solves" most issues, but it's something I think is a little overkill for a niche that only I probably would care for.
Below are all encoded with EnCodec, and then decoded with Vocos:
This multi-hour endeavor caught my attention when I was trying to dig for a specific speaker amongst all of my outputted audio, and noticed the reference audio it exported in the evaluation output sounding very terrible. I also had some notes, but it actually was because I had remuxed the outputs to MP3s, and those issues actually were because of the rotational velocidensity emergent in MP3s, so I remuxed them to OGGs (because I needed a format that Chromium wouldn't automatically download, and instead have an HTML5 audio element play it without downloading).
In hindsight, though, it seems it's just a lot of nitpicking for a very niche application, since EnCodec works fine for normal human speech and not voices that are processed in unnatural ways. 2 RVQ bins should inherently be fine with Vocos, and if I really need every aspect of SHODAN's acoustic nuances preserved, then fuck me I guess, I'll just need to bake a NAR that outputs more residual levels.
Weekly evaluation time: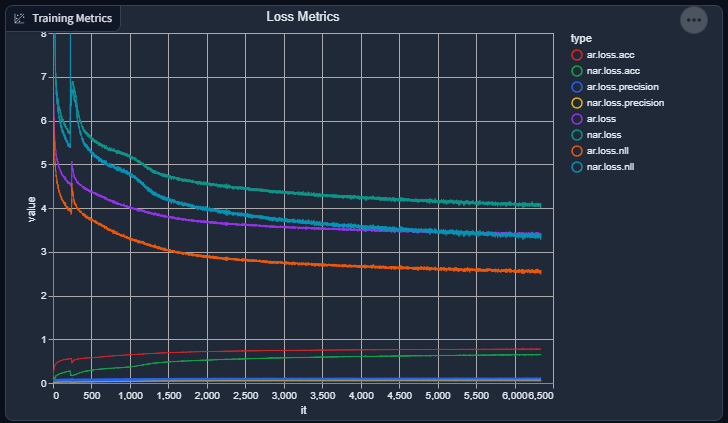
Naturally, reducing the amount of RVQ bins to attend to makes it much better for the model. In my head I've been trying to figure out if it's because:
I'll probably need to figure out if the lifeiteng/vall-e implementation does have any fancy witchcraft that does de-emphasize the higher residual levels, or if the VALL-E paper does mention any mechanism for doing so, but I doubt it. I imagine, like every nut in the ML space, the paradigm of throwing moar compute at the problem bandaided a problem no one really noticed. But again, I am in no way an expert at anything related to machine learning or whatever you call it. I'm just a programmer.
The outputs are... mmm.
Regardless, here's them in their non-cherrypicked form from the last 1250 iterations: here
I think when the model is actually trained one a guaranteed full epoch (rather than an epochs-worth of data), then:
I think the crux of the matter that's been nagging me for the past two days is the (possibly) unbiased attending to levels that don't really matter all that much, and losses being computed for levels that don't really matter all that much dragging down the rest of the model.
Out of interest, do you eventually plan to release a stable model once you got it something work to a good level?
Yeah.
My primary fear is that it'll just end up not performing as nicely as TorToiSe, either as a zero-shot model or as a model for finetuning. There's some decent output from the eval / val output, but not consistent enough for me to be confident in it at the moment.
I'm waiting until tomorrow to do my weekly evaluation on how the model is shaping up to be. I have it training for a few days on a dataset with the donated audiobooks pruned to try and bolster the other 2439 speakers (the 572 hours one). If the model isn't fucked, then I suppose I can move onto trying to finetune it and seeing how it fares. I honestly have zero idea on how it'll go.
But for sure, if I need a zero-shot model, I need both more speakers, and to modify my training strategy.
mmm. I did the daily evaluation listening-to, and this was quite a gem to hear (ironic, given what's said):
Given an seemingly utterly useless prompt it selected and trimmed randomly, it assumed it was actually the HEV suit and cloned that voice. I think I should be a bit concerned, but I can't really discern what the implications of this is right now. Well, at the very least:
I am throwing some money and compute at this to try to reproduce the vall-e paper with the full 50k hour dataset. Any sense on whether this repo will achieve parity with that? (or do worse, or even outperform?)
The full model outputs from the original paper seem a little sus in places but great in other places. Do you think it will outperform open source repos like tortoise and piper?
I swear the moment I started typing this, my noggin decided to really not want to express my thoughts, so bear in mind if it sounds rough.
I'm pretty confident that my fork should, at the very least, perform at parity with the original VALL-E's samples. The only hinderance with it now are:
I don't think my fork / the base-I-forked-from's model code deviates all that much from the paper. I'd say the only intentional deviation would be from me training my model at EnCodec's 1.5kbps rather than the 6kbps the paper uses, but Vocos helps supplement the loss in inherent quality.
Definitely. I've been very pleased with my results, when they do crop up. Out of all the outputs I've had listened to during training, I don't think I ever really had any of the issues that cropped up from TorToiSe.
Although, I could just be dickriding VALL-E. I just really like how elegant and robust the stack is, and doesn't have to use any intermediary to represent a voice (like TorToiSe's conditioning latents and Bark's whatever it's called). It Just Works.
Thank fucking god, finetuning is quite a success for how little time I did run the training on, although:
But here's the quick test output from it: evaluation / validation output. The impressive portion is the validation output, where it pretty much just uses the transcript from the validation dataset, and I suppose it's the same with TorToiSe to where you can pretty much """mix""" a voice of a given input prompt with a voice you finetune on, since there's some variance in the output.
I'll try and finetune on some other voices, and if that works, I'll have to try and fix the web UI to get inference working again, since I think I broke it when I added Vocos. And then most likely I can release my weights to finetune from.
I also had some notes from my evaluation I was going to say yesterday (or the other day) but elected to have it put off for my weekly evaluation, but I'm a bit fried on 4 or 5 hours of sleep, and seeing that finetuning is pretty possible made me forget what I was going to report on anyways.
Another test with a partial finetune of GLaDOS (iteration 250, batch size 8). Some validation outputs I found quite interesting:
With a little bit of finetuning, a lot of voices it would receive as an input prompt will carry over additional traits of the finetuned voice. My ear isn't quite tuned to take note if the acoustics themselves changed too, but the general speech of each voice changes to the target (GLaDOS). And this isn't even a full finetune yet.
I used a much lower LR rate of 1.0e-5 and a gradient accumulation of I think 24, just so it would finetune a little nicer,
Figured to share it before I go fuck off again with more finetuned tests, but I'm very, very pleased even with an barely adequate base.
I tried a finetune with SHODAN but I didn't get favorable results. I'll have to try her again with less aggressive hyperparameters.
Have you messed with Mangio's RVC fork? https://github.com/Mangio621/Mangio-RVC-Fork
I notice if I run output from here through a model trained on a similar dataset, it improves even more the overall quality and makes the voice more consistent throughout the speech, using the Harvest model. It also allows for dynamic pitch modification on audio input.
I've actually thought about running it through an RVC to see how things are cleaned up. The output (finetuned or not) is fine, but both the actual audio quality is a bit lacking, and there's occasional issues in the actual speech here and there, so I imagine running it through RVC would help clean up things a lot. If it works out, I suppose it'll end up getting added to the web UI anyhow, and it can be used for TorToiSe in lieu of VoiceFixer (which I would like to replace, since for however long I've had it in the stack, it would consistently have some crackle at the end).
It would be a nice way to try and bridge the gap between "fine" enough output from my VALL-E model and "good enough to use", as I worry manually training the model some more would take an astronomical amount of more time (or data).
What I've found more specifically is that I can skate with faster output from here (lower samples and lower iterations) because rvc seems to "boil" down the input audio and then reapply its own latents to it. If the input audio is already in the ballpark, then it will come out nicer.
How do I know this? I have tortoise audio trained on one dataset and rvc trained on different dataset from 20 years in the future (same speaker). Despite the sound difference due to age, it can still blend very very well on a different dataset output because the speaker is the same. I've tried likewise using the same dataset for both and of course sounds good as well, but I just prefer the voice from the two datasets blended in my case.
I definitely can understand the challenge for trying to train two models... RVC takes a couple hours in my experience for 200ish epochs. That said, it's mandatory for me now because the quality is just night and day better as a final polish. Oh, and I also normalize the audio volume inbetween.
Oh right, I forgot to do my weekend assessment. I swear the moment I started playing around with finetunes, I had other endeavors I needed to attend to, and my brain just stopped wanting to keep up with lengthy posts and went mush, but I did get enough out of the tests to use for my weekly assessment.
max_phoneme_lengthvalue or whatever.Train > Prepare Datasettab, like I have to do with Bark, but it's just to grab input prompts. TorToiSe at least has the beauty of "averaging" out all utterances in the latents. However, I do have ideas to make it work "better" by using the transcription to pick the closest utterance to what you're trying to output using embedding comparisons.I'm a bit bummed, since I'm definitely going to have to retrain again, but it only took a few days at least for one epoch (the fullsized model didn't seem to benefit in the overall time it took to train one epoch). But hey, it's still a learning process.
What I'm not looking forward to, is processing LibriLight. Processing the 2000+ hour audiobooks I was donated barely was able to fit on my SSD when processing the full thing, and the process took quite a while if I remember right. What I'm also not looking forward to is trying to nail in my tweaks to the dataset creation process. I think I can get away with re-phonemizing text, since I still have my transcriptions, but I don't know. It's kind of daunting.
I'm also hindered a bit with doing anything outside of a terminal on my training system, as I made the grave mistake of
pacman -Syuand now I can't get Chrome Remote Desktop working again, and the fixes of the past won't work now. I refuse to settle for VNC.However, RetNet seems like a new shiny toy that'll come around soon, and it seems there's an implementation for it too. I am not looking forward to try and cram it in place, as the actual architecture of a model is my weakest point (again, I am not an expert, I'm just a programmer). However, I'm kinda certain that it can be sort of drop in place for TorToiSe, so that sounds like a distraction I can indulge in.
Don't know how I missed this, I guess it was submitted in the middle of my writeup.
Ah right, that reminds me, I need to confidently check that the
max_stepspassed into the AR actually is for the length of its output or if it's just a quality thing, although I'm very sure it's the former, since there's no sampling done.The thing with TorToiSe, and I don't think I ever caught on until much, much later, is that the "sample count" for its AR are technically samples insofar as you're picking the best out of the bunch, but inherently aren't what boosts quality. What the TorToiSe stack does is generate a bunch of potential candidates (which is where it takes the most time and VRAM), and then the "best" of the bunch gets compared through the CLVP/CVVP. I still think it's an interesting approach, but it's still a cope approach.
That doesn't sound too bad. I didn't take exact notes on how long I was running finetunes on the weights at the time, but it felt like a mix between "wow, my iteration rate is definitely faster than TorToiSe" and the reality of "my god this is actually going to take a bit, since the losses don't seem to go down as far as they do when finetuning TorToiSe".
But yeah, having to tote an additional model to finetune and support is a bit daunting to try and implement into the web UI. I'm still feeling guilty of having training VALL-E """supported""" through it, but I have never actually used it, since it's just better to train from the command line instead.
But I'll keep it in my mind at the end of my next training run, hoping that there aren't any more tweaks needed.
Fuck, that's right. The one thing I forgot to do with my training dataset is normalize for audio. Another thing on my to-do list I suppose.
And a sort of addendum note to my last report. I was mulling over it, and I don't quite understand why my inference output sounded that gimped on the base model (after training it a bit with the non-audiobook dataset), yet all the finetunes didn't seem to have that glaring issue (or rather, what I remember of it). All of the validation output sounded fine (semi-especially for the finetune tests), but I think the last I checked of it was before I pivoted to a reduced dataset. So I might actually need to do my tests again from the base model before that, and if it's better, then I really did fuck it up with training on the reduced dataset. At least that checkpoint is still around.
Thanks, mrq, as always! Reading your writeups are always an interesting bit of my day. I don't have as many hobbyist experts around and it's nice to read something with that level of passion... even though you're much farther along than me!
I'm also very excited as I just noticed that RVC has a new pitch extraction model called rmvpe.... I can't find much info on its technical specifics but it is MUCH faster!!! for the voice conversion. As in, 10 minutes of audio converted to target speaker in under 1 minute processing time. Faster than real time !
Can vouch for the Tortoise TTS to RVC rmvpe pipeline. Gives results on par and sometimes even better than 11labs, sounds absolutely amazing.
Alright, I'll see about adding it into the web UI if I get a moment over the weekend. I think it should be easy to slot in something, at least, if I don't spaghetti over the web UI code again. I really need to rewrite it, but that's another day.
I got around to trying to listen to the evaluation / validation output (for real this time) from the model while I was training on the reduced dataset, and after when I pivoted back to the full dataset and... my god was that a mistake. It's pretty sad hearing the general quality degrade over time, despite the loss / accuracy being about the same. I guess that strat won't work very well, although I don't know if it just means additional epochs will eventually degrade it (unless I train at a smaller LR).
But here's the "final" graph for the past two-ish weeks. You can see the points where I pivoted between the two when the loss would shift a small amount. But I suppose I'll have to shelve this model, as it's still inherently flawed: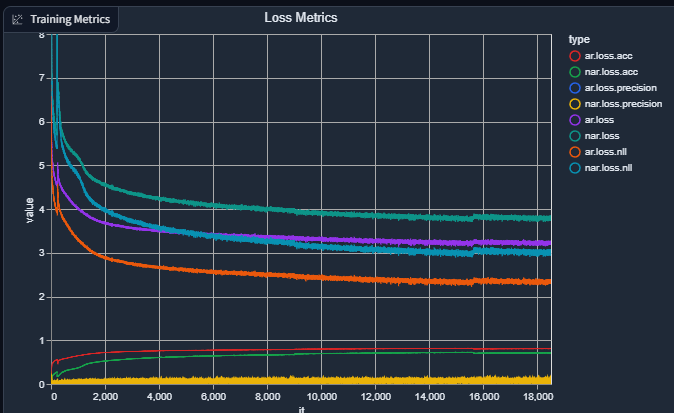
I did fix a few issues on the inferencing side within half an hour of fucking with it again:
generate_vallefunction, I don't have it reuse the same input prompt, so any voices it's already not so familiar with will vary greatly if the reference voice clips it pulls from vary enough. I also lied, and you don't actually need to process your voice and transcribe, it handles./voices/{voice}/fine.while True:instead in the appropriate model files.I did a "lingual test" some Harvard sentences on the Mitsuru P3 finetune, since an adequate finetune seems to help a lot, and it's it's not that bad (the audio quality leaves a lot to be desired, however, but that's just from being 2 RVQ bins I'm sure):
Anywho, I think I need to:
I don't know if I can get away with resume training with the above changes, and see how well the model adapts (maybe, it seemed to be fine with finetuning), or if I should listen to my gut and stop trying to concat onto the weights.
Although, I just realized I might not get much free time the next week, but I'll see what I can do while waiting for LibriLight to transcribe, since I should get to doing that in the background.
Off to a good start I feel with the new dataset.
normalize = Falsesomewhere, I don't have a line number because my copy hasn't been committed to the repo in a while). I don't even remember why I do have the text normalized, since everything is inherently normalized through Whisper anyhow.medium(as I already hadsmall).${speaker_id}_${book_id}, and that way I can have another script to eventually prune the duplicates in LibriLight (since the LibriTTS copies are higher quality).And then I realized two core issues.
./voices/{voice}/into./training/{voice}/audio/as PCM_S 16-bit WAV at 24K, and then the slices (because TorToiSe/DLAS requires it this way). I was barely able to make the donated audiobooks work with some nasty kludge with my code, but I don't think I can do that.I think my solution is just to simply load the FLAC (torchaudio underImplemented having it load from directly fromsoundfilebackend loads it fine, it just can't save it), and do the slicing and quantizing in memory, rather than slice to disk and load those slices to quantize../voices/{voice}/, do the resampling and slices if necessary, and then quantize the audio to disk for VALL-E backends.I have the transcription process running for LibriLight-6K while I end up doing nothing from choice paralysis. I might fuck around with RVC on my actual desktop, since I can't really touch the web UI on my GPU slave right now, since the "new" way I'm transcribing/processing is just call
cli.pyon every voice to do the processing, since doing a bulk transcribe/processing will eventually make the process hang up and die (although maybe more system RAM will fix it, but better safe than sorry now).Fug, I didn't get a chance to play around with RVC. Whatever time I did have was spent between other things and getting LibriLight-6K hours transcribed and processed and everything re-phonemized, and increased the bounds for a slice to be processed (instead of using TorToiSe/DLAS's text and duration lengths, I'll just have it determined in the YAML at train initialization time).
Transcribing LibriLight-6K went fine, a little too fine. I only realized, after the fact when trying to do cleanup for disk space, that I fucked up with my pre-processing the LibriLight-6K dataset and neglected that a lot of book folders had more than one piece of audio, so when I went to run the script to rename them to
${speaker_id}_${book_id}, it would overwrite things. So this should explain how transcribing it all took only a day and a half compared to the donated audiobooks taking a few days to process through it all.Regardless, this partial LibriLight-6K (without pruning for text and duration lengths) brings the dataset to:
I'm not too sure if I should bother going back and re-process LibriLight-6K (from scratch, or at least, intelligently pick the folders that did have multiple files in them), or just suck it up, as this next training "test" is mostly looking out for the better phonemizing method (not phonemizing normalized text without punctuation), and having some more speakers to play with for zero-shotting. But oh well, I'll see how it goes.
mmm... maybe I was a little too hasty to get training back up again. Not only did I have the partial LibriLight-6K, I also forgot I wanted to:
As for the latter, I'm (finally) dipping my toes into the intricacies of the model and, unless I'm neglecting something, it seems all I really need to do is just slot slot out this "Block" (which just looks like the transformer-y bits) and supplant it with a RetNet (this implementation looks rather clean and not boilerplated to high hell with faux-DeepSpeed isms as with the official M$ implementation). The beauty of the Jamie-Stirling/RetNet implementation is, just like how the original enhuiz/vall-e implemented his own transformer-block stuff, I can easily just custom tailor it to use the shit like AdaLN and whatnot.
Unfortunately, I'm kinda gonna be stuck with training the model for the next few days, I might as well see it through and see if my adjustments mattered. On the plus side, 5% of the way through the epoch (and 10 hours), it's already at AR accuracy=~66% and NAR accuracy=~44% already. I don't know if this is because I accidentally upped the LR from 2.5e-4 to 3.25e-4 so it's training faster or that actually adding in punctuations help, but I'll take what I can get.
For real should be my last update for a while unless something catastrophic happens (I doubt it), but I figured this should be it's own block as this is more about integrating RetNet.
I bit the bullet and spent some time cramming the previously mentioned RetNet implementation into my fork. It... works. Everything seems to be in order, but it's missing some of the base tech like:
I could preserve the PreNormResiduals and SinusoidalEmbedding by replacing the Attention portion with a MultiScaleRetention instead, but there's some argument chicanery when I first tried it (desu though, I didn't have a good grasp on it yet).
For any weirdo interested in cramming RetNet into some other project similar to this VALL-E implementation, I did have to make some slight modifications to the RetNet implementation:
retention._get_D's outputted tensor to the right dtype and device.The other benefit seems to be that it has significantly recovered some VRAM for training (down from a tight ~11.5GiB to a nice ~8GiB with the fullsized model, so I can now up my batch size again).
For any poor soul training a model at home, you can enable using RetNet with setting
use_retnet: Truein the training YAML, although I hope not, since I did modify the tokenizer map with my new dataset with punctuation.Thanks for your great work! Is it possible to train a vall-e model with single RTX3060(12GB)? I don't care how long it will take for training.
You're not just a programmer, you're a genius. And we're very fortunate to have someone so open and engaging as you. You have so much enthusiasm and put so much of your energy into this project - it's amazing. Hopefully once you have mastered cloning voices, you can chill a bit.
I genuinely had to do a double take when I woke back up and saw the AR already this far: 6 hours to get to what I imagine would be an astronomical time:
Although... the NAR seems a little lacking. I wonder if the included AdaLN is actually bunk, and that's why this entire time it's been the one to suffer a little bit in terms of training. There was a comment in the AdaLN function mentioning something like that from the original dev of the implementation, but I didn't expect it to mean currently it's wrong.
I might pivot to the quarter sized model with how fast it trained, since I think training the rest of this epoch would be rather silly.
And catastrophe struck. Despite testing it with the little mini trainers for each model, the evaluation / validation process and inferencing broke. I'll have to see what I can do about it, but I have pivoted to the quarter sized model to train without AdaLN for the NAR and seeing how that goes.I think I fixed inferencing? Not sure what happened. I also had a few little gremlins but I doubt it caused it. Still going to try a quarter sized model without using AdaLN for the NAR instead. The output from the test run, though, was quite dreadful, I imagine from the NAR being bad.
Also, I don't know if it's just me being forgetful, but the inferencing times seem... quite dreadful. It seems fine during evaluation / validation in a batch, but just generating one line with the RetNet feels worse than I remember it being with the normal Transformer.
Mhm. My misfortuned 4070Ti has 12GiB, and it's been able to handle it fine, not as much as I'd like, but it definitely works. I'm not sure about the speed between Ampere and Turing, but I can't imagine it being that much of an issue.
Nah, I still need to clean up (rewrite) AIVC's code from how much of a mess it ended up, and probably also re-write my VALL-E fork, as there's a lot of bits I ended up just not really needing.
Just wanted to say, I love what you're doing and your detailed updates. I wish I could do something similar, but I have my day job which gets in the way.
How are you able to juggle this with work and other responsibilities?
Had to do some needed cleanup with the config class and YAML, so I did that, and I can now easily pivot between models of different RVQ bin targets and if it uses RetNet or not. I also found that my gut feeling of just slotting out the Attention for Retention would have been the easiest idea, since it looks like the original "Transformer" bits did relatively the same thing as the RetNet (push through the *tention, and then feedforwards, each with their own layer norms). And this solved my issues with inferencing / evaluation / validation output inconsistently failing.
The quarter sized model is also blasting away really fast, so I have my hopes for it turning out good.
Very carefully. I feel I barely am able to pivot between them all, but yesterday and today I've just spend my time in the night to poke at it, since I don't think there's really a better time to do so at the moment.
I feel some slight uneasiness.
I feel like there's something I'm missing with the implementation.
The upside is that training through the entire epoch on the quarter sized model should take 22 hours, so working with the model should be much much faster to make tweaks with the retnet implementation. Although, that's the issue, since I don't know what would be considered "wrong" or "just give it more time".
I guess I'll give it more time. The evaluation / validation output is sounding a little more clearer over time, so I suppose everything is in order, just needing more time.
I am very positive my issue actually is the fact I need to actually use the specific recurrent (causal) forward pass rather than just naively reusing the existing AR forward pass to handle things, which would explain the discrepancy between a well reported AR and the output being too short and shit.
My only qualm is that I really need to try and wrap my head around how to cram it in, since it requires keeping track of a separate list and values, and that isn't necessarily something easy to do unless I explicitly pivot back to using the RetNet class itself rather than the wrapped
PreNormResidualclass that handles it's own tention+feed-forward shenanigans. Which sucks, because I just torched the previous model that was in the middle of being trained using the "full RetNet".At least I can keep training the model, since the normal forward pass is fine.
Ugh. I suppose my current training needs to be scrapped, since it turns out my "just replace the Attention with Retention, it'll be fine, it did fix inferencing" approach to integrate the RetNet is inherently bunk.
I wrangled with trying to """properly""" do the forward pass for the AR using the provided
forward_recurrentroutines, but no matter what, the output with the partial RetNet (non-full_retnet) always produced repetitive garbage.However, I pivoted back to using
full_retnet(it replaces the layers of PreNormResiduals wrapping around the Attention/Retention + feed forwards, which, in theory are effectively what's done anyways in the RetNet class), and with the tiny trainer, it sounds right now AND inferences without issues.It seems to work fine both with the providedHowever, outside of the tiny trainer, it'll consistently return zero-lengthed output.forward_recurrentand naively without, so I really don't know the issue.Peeved, since I have to scrap the current model again. Oh well.
Turns out a mix of masking the output from the classifier at the end with the RetNet integration, is bad, and using the provided
forward_recurrent(the non-naive pathway) is also bad, as both will output wrong output.Scrapping the test model again.I might be able to at least re-use my current training I had over the night, since it's just the last step being "wrong".The evaluation / validation output sounds fine given how little it's trained: it seems that with RetNet, it can copy the acoustics pretty fast, hence the loss being pretty high pretty fast, but it still needs to learn how to actually speak.
Fingers crossed.
Alright, I think I got things figured out.
prev_output_tokensis... oddly named for a very nice way to put it.token_embeddingsis provided (your token=>embedding), it'll create it for you (nice I guess for non-merged sequences).(b, t), because it derives the output sequence length from it. Heaven forbid it being a named argument liketoken_embeddingsto avoid having to craft another tensor, but I think I can cheat by having it sized but empty, or on the CPU, since all it does it check for its size.I think, right now, RetNets aren't meme snakeoil, but golly was it pain with a lot of red herrings. At the very least, this endeavor has taught me a lot more about how the VALL-E implementation works, and I think I am now confident in writing my own implementation from scratch* (naturally, reusing the transformer/retnet bits). It's rather quite robust.
I'm also not sure if RetNets just inherently are better at "learning" a style but needing some time for learning language, but I think it's just me forgetting that the previous transformer-based models did start with learning a style first and then the language emerged after quite a while, in addition to the fact I'm training a quarter sized model just to validate how it fares after an epoch, so I'm sure things will get much better with the full sized model.
I think finally I can just let the damn thing train and not freak out or panic. I suppose this will give me a couple of days between training the quarter sized a full epoch through, and then pivoting to the full sized one and seeing what happens from that after an epoch. There doesn't seem to be any more inherent flaws from the RetNet, and whenever I get a chance I can see about fiddling with chunkwise recurrent forwards, as I think that would be a very neat way to speed up inferencing with the AR.
Pain.
I kept going "maybe I should use the Jamie-Stirling/RetNet implementation, it just seems to run a little faster and nicer, and the loss seemed to be really low, the only issue is inferencing with the AR, and I can work around that", and trained a model using that as the backbone.
I was wrong.
I might have to poke at it more when I'm not borderline fried, but I think what's happened is that the AR wasn't actually wanting to be an AR. This would explain why it would generate very short sequences, and the loss being extremely low, I suppose. I feel like every time I poked at it to get something right, my understanding is wrong, and it actually didn't end up being fixed somehow, despite extensive debug prints and tiny test trainings.
The microsoft/torchscale, ironically, just works without any more headaches. It's still much lighter and faster than the previous transformer stack, but...
Now, I'm not knocking the previous RetNet implementation. I think it's very lightweight and very neat. I want to use it, but without an example on how to actually utilize it, I'm not confident enough to continue trying and wasting even more days I could be using to train. It could very well be not mature enough and it's not even a me issue.
But oh well. I burnt another week, but I did learn more about how the VALL-E implementation I forked works. I feel stupid, since, there's a lot more control on how I can go about my own implementation when I write it from "scratch", like using the text/mel loss split that's in DLAS/TorToiSe since, and it feels silly in hindsight, the model actually can learn the input text sequence too, so it'd be kinda imperative if wanting to try and finetune another language on top of it.
As an aside, I bit the bullet to give P*p*rsp*ce a try, and it's slightly faster than my 4070Ti, so I suppose I'll have it train something alongside my local training.
Now, I am getting an itch to try my 6800XTs with the RetNet implementation since the paper boasted that it was using Instinct cards, although CDNA is quite different than RDNA, it doesn't hurt to see if RetNet favors ROCm over CUDA.
Oh well. I'll just shut up for real this time and let the damn model train properly and not try and take shortcuts.
Midweek progress report, since things are going somewhat swimmingly, somewhat.
Retnet:
incremental_state. I wouldn't be surprised if it just, didn't actually work. Using the tiny trainer for the AR on the CPU showed no significant uplifts, and I can't be assed to restart the quarter sized model training locally, and I keep forgetting to check on the full sized model training on P*p*rsp*c*e.Speaking of P*p*rsp*c*, I almost fell for the allure of actually paying per hour for a card with zero hassle, since, the only problem with trying to train the fullsize model is that there's only about 4% of the epoch trained per 6-hour session, but I don't think I should be throwing $300 for an epoch to a service that has cucked me at least three times now, so when I feel the full sized model needs some love over the quarter sized model, I'll pivot to that locally and suffer for the ~5-or-6 day ETA for it now.
Model wise:
Evaluation:
I'll just have to let the models bake and see where it takes me.
In the meantime, since I'm very confident now at knowing how exactly the implementation works now (after doing a deep nasty painful dive with the internals of the model arch), I might finally go about "rewriting" my fork from "scratch" and make it my own (in reality, I'm probably just going to copy paste and restructure things, since most of the code has already been combed and modified heavily anyhow).
AIVC is also going to be rewritten... eventually. Every time I look at it, I'm reminded at how much of a mess I've left it in, and let it grow into. I'll have to throw it into a new repo, unfortunately, since such a huge change is just going to cause more problems.
I'll post samples whenever the either model starts to output consistent speech. I foresee that happening by... Sunday? I hope.
Neato. I'm surprised they released weights for i-
I suppose for general audio it's fine, but again: general audio. 16KHz speech is going to sound awful, but at least it's 4 RVQ bins.
On the other side, that's quite interesting. A single AR for the 4 RVQ bins. I'm assuming it's that interleaved shit that I vaguely remember, which I suppose I could replicate, but I'm actually quite fine with an AR + NAR.
Trying to get proper transcriptions right now for this repo.
I just made use of the openai-whisper package and with the "tiny" model. Do you think that's sufficient? I see you're using whisperX for... timestamps? Are those needed before/after running the phonemizer? Thanks!
It depends... Whisper works best on English and it's possible to get away with using a smaller model than on a different language like Russian or Chinese... That said, I always use the largest model for the most robust transcription, especially if there are many audio files being transcribed. It's a PITA to go back through and check everything if you've got like a 100+ files in the dataset.
Yeah the problem with whisper is that it's hard to scale. Seems like batch inference doesn't seem to affect inference times much, and I can't get multi-GPU to work...
I'm using the smallest model, and I have a feeling it's too low quality of a transcription.
That said, all I'm doing is getting the text transcription and nothing else. A bit concerned maybe I need timestamps or something going through the history in this thread.
Depends. The bigger used the better the transcription quality, but desu I've been using
smallfor the past dataset batches, since, a sufficiently large enough dataset will be resilient to any transcription problems (which are already sort of smudged out when phonemized).But again, that's only with a sufficiently large enough dataset, and I don't really know still how big that is. As a reminder, my current dataset is clocked at 4065 hours of audio, and that's still magnitudes smaller than the original paper's 60K with LibriLight.
This repo's web UI handles it fine with the Train > Prepare Dataset tab (or whatever I ended up calling it again). It'll handle the entire stack from transcribing with Whisper (or preferably, WhisperX), using the outputted timestamps to to trim down utterances if requested, and exporting the quantized audio and phonemized text in a format that my VALL-E
forkimplementation's trainer can use, as long as you start the web UI with--tts-backend="vall-e".Shilling aside, there's a way to do it without the web UI as documented in the README, but I think it's a bit of a chore if you're leveraging Whisper, since you'll need to yank out the text itself.
From what I remember, Whisper doesn't have batch sizing, WhisperX originally only had batching with the VAD filter (which required a HF token), but currently supports batching with its faster-whisper backend, but I don't recall either having multi-GPU support.
Nah, it's only if you're on an extremely tight VRAM budget and need your audio trimmed as tightly as you can get. The original paper seems to be feeding in 20-30 second utterances, which I think the maximum Whisper will spit out is like, 16 seconds? before it'll segment it itself as best as it can.
I will give a bit of a caution that, I still don't feel quite comfortable with my
forkimplementation being used to spin out models, only because I still need to get around to figuring out why distributed training won't work, and desu I think it'll be a little ways off before I can get around to it from odd circumstances at the moment (I suppose I can bite the bullet and r*nt out a multi-GPU system for a few hours to test with without going through the agony of throwing in my 2x6800XTs back into my training system).Speaking of qualms about suggesting the VALL-E implementation from being used: I can finally stop calling it a fork and comfortably call it my own implementation. I've done my rewrite, overhaul, and restructuring through almost every facet of the code, save for (in short, anything credited at the top of their respective files): the original transformer-based implementation, the dataset sampler code, the training loop that handles stdin and saving/evaling X iterations, and some helper functions and boilerplate creature comforts.
I think the implementation (like my understanding of VALL-E now) has matured enough that I won't be breaking anything anytime soon, since the config YAML is cleaned up in a way I like it, the RetNet-based model seems stable enough, and anything pertaining to the dataset isn't going to change anytime soon (although I don't think it ever actually changed).
Additionally, I've set it up in a way that, if I wanted/needed to, I can pivot away from DeepSpeed and use a different framework, like HF's solution, or Lightning, or my own + BitsAndBytes (which I suppose technically is already in, I just need to extensively test it). As much as I like DeepSpeed, I think that, in the context of the model's largest preset size being around 400M parameters each, I don't think I need to leverage any of the ZeRO features.
I just hope that putting my faith in a RetNet for the current training pays off. I'm still rather impressed, but still holding my breath for it paying off.
Actually, I was only making use of the readme and repo. Where is the web UI?
This repo; the one originally for a web UI for TorToiSe.
So upset that I keep ending up having to constantly reset the epoch with training the full.
loss.nll(because it was summing up the precision and accuracy metrics too as the loss) until I used my training framework for a ResNet-based side project, about another quarter way through.I just want one full clean epoch to train against.
The evaluation output is sounding better in terms of actual speech, but it's having a bit of a hard time capturing the style right; I'm going to cope and say it needs more time because of the botched epochs (I should really look into finding a way to be able to "resume" an epoch exactly from where it was last left off). I'll probably share the outputs again in a few days, or when it starts sounding fine.
I'm very confident the RetNet-based approach is perfectly usable, it's just with a bunch of headaches and hurdles getting to a """decently""" trained model is quite the pain.
Quite the pain.
Does it seem the RetNet approach is better / more data efficient, or better to use the original vall-e implementation?
Also, I am using the phonemizer, but is keeps coming up with None values occasionally (I guess there are some tokens or substrings it's not expecting?). I modified it to just delete / ignore None entries, but maybe that's a bad idea?
It's a bit complicated.
desu I tried to express my sentiments, but both:
I'll probably give better thoughts whenever (ifever) the model gets to a good point.
I don't quite follow, since I haven't had any output issues with the phonemizer (technical issues before, yes, but not outright output problems).
But when I get a chance I'll see about looking into it.
mmm. Maybe I'm being a bit of a baby about it. Giving another listen to the most recent evaluation / validation output and listening to the reference for direct comparison, the current, RetNet-based model sounds about the same "cloning" quality as the transformer-based model has (from what I remember): samples (17250 is from a few days ago, 32750 is right now).
It definitely has a lot more room for improvement.
I suppose that, empirically, a RetNet-based model outperforms a transformer-based model, as technically right now the RetNet-based model has less training than the transformer-based model did.
I still don't really have any inferencing tests, like how fast it performs in comparison, how well it can extend past the "context limit" of ~12 seconds it was trained on right now, etc. (the things a RetNet boasts).
But of course, the next batch of evaluation / validation output, without listening to the reference, sounds pretty shit.
ETA 30 more hours until a full epoch is fully processed (despite the trainer saying it's currently 1.7 epochs in from the previous runs), but the model seems to still be better paced than the previous transformer-based one. Some notes that are quite silly in hindsight once more (and samples):
randomvoice option by using either:There's just one more thing I don't quite understand. From the homebrewed lifeiteng/vall-e implementation, I remember the training was something like "4xA100s for four days and 100 epochs". I feel my previous transformer-based model and current ResNet-based model have performed much better in much less compute time. I don't know if this is just a testament to my "optimizations" (tweaks) contributing to a much better throughput, or a testament to (what I imagine is) the crux of every "researcher" and throw their oodles of compute at any task and just bruteforce through it.
Oh well. I just hope I do get enough time to do whatever I do expect to do (finetune test, quarter sized retrain, muck around with distributed training, etc).
Alrighty, the full epoch finished, and I was able to finally get off my ass and put my 2x6800XTs back into my training rig to muck around with getting distributed training working. The whole time it really was just that I needed to use
DistributedSamplerand make sure the corresponding batch received was on the right device. Everything seems to be in order, as the total iteration count aligned with being half the size of what it was before with one device. Woo.On the flipside, what a nightmare. First with finally diagnosing why Xorg didn't want to launch when using an AMD card (because Xorg.conf was set to explicitly load Nvidia drivers, I suppose when I had
mhwdinstall them, it also configured Xorg.conf "proper"), and then remembering that torch2.0+ still doesn't work with ROCm, as I'll keep gettingnans in the forward pass. Going back to torch1.13.0 fixed this, but with a nasty performance hit. It'd be nice to use newer torch against newer ROCm, as my iteration rate now is 18s/it for an effective batch size of 32. Woo.There were also some fixes like making sure exporting actually worked cross-device, and inferencing works again, as I imagine I broke that too earlier.
As a side note, I'm still not really sure what to do after this point. I think I should go and throw my shit onto a rental machine again and eat another epoch or two from there. Using P*p*rsp*c* to train in 6 hour intervals was bad, but it might be fine if I did pivot to my proposed idea of "have the dataloader sample against speakers themselves, and then randomly pick the target from the speaker's pool", since the major issue was that an interrupted epoch is very le bad.
But since I have my 2x6800XTs in my training rig again, I did kind of want to muck around with LLaMa again but for real on a GPU with exllama and not painfully on my personal rig with tight system RAM, despite it being DDR5.
Oh well, I think for the night I'll let my 4070Ti rest a bit, although it doesn't seem to break 50C during training anyhow. It might benefit from a modest overclock, if anything one for memory, since I imagine it's memory bandwidth limited.
It seems the ROCm + pytorch 2.0 issues derived from an issue with GPUs whose PCIe lanes go through the chipset rather than the CPU itself, effectively dashing any hope of homelabbing since all chipsets on Ryzen boards do that I'm not too sure how that was causing the
nanissues, but I've got other ROCm + pytorch 2.0 things working on a single 6800XT. Not a big deal, since my 4070Ti works on the 2nd PCIe slot.I resumed training on a smaller range of the dataset (I think I set it to only pick utterances with phoneme lengths under 64 tokens, and durations under 8 seconds?) to try and chew through an epoch faster, as I didn't have much time left to work on pivoting from a "have a dataset pool from paths rather than speakres" approach before conking out. Doing this lets me comfortably double the batch size to 16, and the ETA is about half of what it was before with a "full" dataset (ETA 60 hours).
I did some inferencing tests before this and... zeroshot is pretty inconsistent with the non-LibriTTS voices, and using LibriTTS voices has it consistently fall apart. I'll just cope and say it's from the model not being as trained as the transformer-based model was when I did do inference tests. Although I'm now realizing I might have not been loading the right copy of the model, but I doubt that's the issue.
Some voices that should not have had enough training time compared to the audiobooks performed a little too well for what it's worth at least, which I guess is a good sign, but it's still an issue of getting consistent speech that doesn't sound like some alien trying to mimic human speech.
Testing the RetNet's capabilities of extending well past the context window it was trained against seems promising. It's just hard to judge how well it works without the baseline performing consistently during inference. It doesn't sound like it completely falls apart, but it seems that after an arbitrary point, and for an arbitrary length, the voice will sound different, and then snap back to "normal" after (normal insofar being that it sounds like the output in the beginning).
I suppose the ultimate test is seeing how training on a much smaller context window will fare with the RetNet. Again though, I'm just not too sure how to go about this again, since the last time I tried pivoting on a narrower dataset, it seemed to be for the worse, but I don't think it's feasible to do another full epoch for marginal improvement. I suppose I might need to dump in more data to help with the speech, but I'm not too sure how necessary that is, as I've demonstrated the models can speak before.
runpod.io has H100s, so I suppose I'll paypig and give a real GPU a spin.
desu it doesn't seem to be that bad of a deal, compared to P*p*rsp*c*, so a few hours to dip my toes in the water shouldn't be too bad. RTX 6000s Adas and 4090s seem much more cheaper than I remember, so I can also pivot to either before scaling up even more if I find them to be a little bit of a better value proposition compared to H100s.
The throughput increase was... not as much as I was expecting. The ETA with the full dataset on one H100 racked up to 80 hours, and throwing four H100s had it go down to a little above 22 hours without specifying any ZeRO configurations or special flavors of optimizers.
I'm going to pivot towards renting 4090s and see if it's a better value, since I'm just thinking training these models just don't scale all that well, both with throwing more compute at something from cards of a same arch/similar arches, or increasing the batch size.
I suppose $10 down the drain isn't so bad.
I burned another $10 on nothing over night for the 2x4090s because the training got botched two hours in and ran out of disk space. I suppose I should really re-implement the "keep the X latest checkpoints" from AIVC into the VALL-E trainer.
While it's not quite apples to apples of a comparison because:
the ETA when using 2x4090s rounds out to about 20 hours. With the 2x reduction in the ETA from locally pivoting the full dataset to this throughput-focused one, this should be about comparable with the ETA 22 hours the 4xH100s were able to estimated-clock-at for the full dataset (I think, I'm pretty sure I pivoted to it for that test).
While I think I should give the 4xH100s another shot with ZeRO, I don't think it's going to change much as the ~4x in price isn't worth it for a menial change in throughput. I suppose the purpose of large enterprise GPUs like the H100s are for extremely large models, rather than tiny ones, so they're not a good fit for me. If anything, I suppose I can get away with renting a cluster of 4070Ti's, or a giant cluster of V100s.
I suppose I'll have it eat out another full epoch as I have the quarter-sized model baking on my local machine. It's starting to sound better after putting more time into it, so I guess it's just a matter of giving it some more time to develop.
I decided to move this out of the """blog""" update comment above, since it should be it's own section for me to continue updating my thoughts on:
It seems M$ has an answer to Zucc's voicebox or whatever it's called: https://www.microsoft.com/en-us/research/project/speechx/
Giving a look at it, it seems like a rather simpler method to Zucc's "flow-matching" based model voicebox uses: with some light adapting, they turned an existing VALL-E model into one that can do more than zero-shot voice cloning by making use of special tokens and formatting in the input prompt and procedurally generating output that fits the task at hand. It's something I could even try and pivot to, since the paper explicitly mentions using an existing VALL-E model to start with, and detailed how it goes about preparing the target outputs to train against, and even mentions how well it boosted the zero-shot capabilities from it.
It's something I should probably look into once the model is good enough, since the methodology seems very straightforward. I think all the necessary changes can be done in the dataloader's getitem to all the input data accordingly as a procedural post processing. I think the only issue would be any of the noise-related tasks, as I would have to decode the EnCodec tokens, apply the noise to the waveform, and then reencode them. Sure, I could have that as an ahead-of-time dataset, but the noise wouldn't be random per utterance sampled.
It also reminds me I should give the VALL-E X paper another look, since, knowing so much more now than I do before, I should be able to have insight on how they went about it.
Thanks for everything your doing to replicate this project- Microcuck will never give us access to these tools.
The work and commentary is awesome!
The new SpeechX (and voicebox) model showcases content editing capabilities where some parts of a sentence are replaced but other parts remain intact (not referring to background editing). Can the Vall-E model do this too?
I am keen to donate A100s or H100s if you would like to use them. Would it be helpful?
The one thing that puzzles me is that no code has been released for SpeechX, NaturalSpeech2, nor VALL-E. I understand them not releasing weights, but no code is a bit silly, since it still requires an """ethicist""" with the compute to still bake up some weights effectively.
I suppose that's just the nature of voice synthesis; there's no need to be competitive, so everything can toss up paper tigers with their research papers.
Yes-ish. Yes, because the core of SpeechX is still VALL-E. Ish, because it still requires training for that task, but is definitely do-able for me to implement.
The only challenges I have imagined up are:
proms_emb's input count from 1024(+1 for the AR) an extra couple of tokens for the extra tokens that mark a task in the input prompt. This is allegedly easy, but it'd be kind of a pickle to automagically extend weights from a pre-extended model (I have ideas, but I need to figure out what is feasible for the end user who happens to have weights from before this change).Since SpeechX's paper shows that VALL-E can easily be extended to more tasks than just text-to-speech, I feel like it'd be cool to also add in my own set of tasks to, but I can't really think of any other tasks to have it to outside of something similar to VITS/RVC. The only crux is that I would need to rely on RVC to generate my own dataset for training such a task.
mmm.
While I am an arbitrary amount of more comfortable in the notion, now that I'm much more confident in the implementation able to spin out something that semi-works (and with distributed training, more or less), I still feel I can't do that just yet. The 2x4090s felt very comfortable to use, despite there being some weird quirks to contend with. The batch size was able to be set to a comfortable amount that wasn't wasting VRAM to account for the chance of OOMing from the backwards pass.
When I was testing on the rental H100s, I did not feel comfortable at all, as I felt I wasn't able to nail out a comfortable batch size without risking OOMing in the backwards pass, and the uplift in throughput felt very flaccid in comparison. Although, I suppose I should revisit it with ZeRO/ZeRO++ when I get the chance.
I appreciate the offer, and I'll definitely keep it in mind. Aside from the "ugh... just not comfy enough..." cope, I do feel there's still quite some things left I need to adjust with my methodology, like expanding my dataset, what's the best way to even train it in terms of learning rate, and maybe pivoting away from DeepSpeed's quantization as I don't think it's working (there's just no documentation on how to actually use it), and some other things that should be done sooner than later.
Having said that, I do feel much more confident in the models.
Over the course of however long I did leave the model to bake on the 2x4090s, I also was having the quarter sized model train on my 4070Ti, and the improvements were looking (sounding) good. It's able to actually produce rather coherent speech, but still has a lot of room for improvement. The "clone-ability" is still lacking, but I trust there's enough parameters for it to grow stronger.
The full size model is improving too. It's definitely getting better at trying to clone speech, and the general "linguistics" it produces is getting more and more consistent. Testing the RetNet capabilities, it definitely can extend past the context size it was trained on... but it seems to produce a stop token after extending past 3x (from one sentence to three sentences). I suppose things will get better as it trains more.
With even the quarter sized being able to provide decent-ish speech for its size, and the full being able to work, it makes me curious to try and see how well a model larger than the full size (probably 30 layers?) will compete, but I imagine the speed and even training it to be a pain.
However, inferencing still feels very inconsistent. It's pretty much a coin flip as to whether or not the output is good enough, while a lot of the evaluation/validation output sounds fine. I'm not sure where the issue might lie, as the inferencing code is pretty much the evaluation/validation code, and it can't be an issue of it being text from outside the dataset. It can't be, since both, the validation output sounds fine, and using text from the dataset also has inconsistencies. I'll have to double check my work I suppose.
The training code also got some love, from distributed training finally working, to it being able to (properly) prune old checkpoints.
However I did catch one assumption I was wrong about. I assumed that the default provided dataloader and sampling technique would have every piece of the dataset visited once within the epoch, but after auditing the dataloader and sampler, I was grossly wrong. It's effectively just randomly picking a speaker and then randomly picking an utterance, not quite the same as what I'm doing of having an "epoch" cover every speaker, but every speaker picks a random utterance. My entire ick about my training getting interrupted mid-epoch was for naught, as a full epoch in fact did not guarantee the entire dataset was visited. I suppose this would explain how past training experiments had some speakers strive despite said speakers barely being visited. I suppose it would be better to, instead, ignore the sampler and just have the dataloader shuffle and pick from the paths. There's the interleave_reorder call to guarantee the list of paths to pick from is balanced, but I think it incurs quite the performance cost. I'll just have to gut out most of that code then.
Aside from the shocking revelation, I think I'm quite comfortable with just leaving the model to train on a smaller learning rate now, as it seems to be improving over the past few days with the more-explicit "sample by speakers" approach. A RetNet works, and so does the model. I just need to give it time to improve and not be half-assed. Although, I think I need to expand the dataset with more parts of LibriLight. I don't think ~4.5k hours / ~3.5k speakers is going to cut it.
Lastly, the changes to the dataset by including punctuation in the phonemes definitely improved the speech output. I incidentally compared against the P3 Mitsuru finetune samples I put out and my god was that awful in terms of pacing. The current outputs I got out of it sounded much more natural.
Don't really have any metrics to show, since the actual numbers don't tell that there's an improvement, but I'll try and provide a batch of samples when I get the chance.
Apologies if this sounds quite stilted and all over the place. I've had quite the notes saved up in my head, but as soon as I needed to recall them all, my brain turned to mush.
Implemented the SpeechX tasks. New models will just need to ensure that the model configuration has
taskset to at least 8 to guarantee enough extra tokens. Existing models that want to pivot to using SpeechX tasks will need to be exported as fp32 weights and then re-used withtrainer.load_state_dict = True. I'm able to modify the state dict to be expanded to a newly specified prompt embedding size (say if you change your prompt levels, or add in extra tokens for tasks).I still need to figure out an elegant way to go about implementing the clean/noisy speech editing, as I'm very certain I need to grab word-level timestamps unless I go an extremely dirty way of stitching three utterances together as the input prompt, and the target is the middle one changed. I guess with a large enough dataset and enough training, the model should be robust enough from any errors.As soon as I typed that, I realized I can just do that. Each utterance is guaranteed to be no more solid of a piece of an utterance than it already is for TTS. The only problem would be not getting matching tone between pre/mid/edit/post, but I'm not able to guarantee that regardless of what methodology I use.I've tested everything except the speech editing. I just wanted to whip something up when I had the revelation before going to bed. I did a brief test making sure everything got outputted right for the other tasks, at least.
I'm not really sure when to pivot to allow the SpeechX tasks to be used during training. The paper mentions it really does help to have a solid VALL-E base anyways, and even if I did have one, training with SpeechX tasks is quite the pain as it effectively will eat up a lot more VRAM, both from having the EnCodec model loaded (despite specifying to do it on the CPU side) and the extra prompt size / target size will make tight setups OOM during the backwards pass. I don't notice too big of a performance penalty from having these tasks enabled, they're rather quick and I imagine the dataloader can process them all before a forward pass completes. The only issue is that the EnCodec model will have to be duplicated across all worker processes.
The other issue I can think of is that there's just not enough bandwidth to resolve anything with noise in the decoded waveform.
The other issue is that the paper doesn't seem very clear on saying if the task-tailored input prompts are only for the AR or for both. Realistically, I don't think the NAR needs to be trained for these tasks, as the first level should be more than enough to guide the rest of the output. But who knows.
I suppose I'll give training with the SpeechX tasks a shot for a day or so and see where it takes me. My qualms:
nse,cse, andtserequire, at worst, 3x the data ( prom => target vs pre+mid+post prom => pre+edit+post target ), 2.5x the data ( prom => target vs pre+post => pre+edit+post target) and 1.5x the data ( prom => target vs prom+overlayed target => target ). To comfortably train, I had to set my batch size to 4 (from 16) especially while under the reduced dataset.Either way, it was a nice fun exercise to test my knowledge to try and incorporate it in under a night or two, and if I cared, I can boast that my implementation has more features.
Did some more sanity checks with the trainer.
I realized that it would probably be more saner to, instead, process the input prompts / target responses at the maximum RVQ bin/quant. level (8), and then trim off the remainder when finalizing the batch. This should help make anything using merged audios (target speaker extraction, anything with noise) work better from working with as much bandwidth as possible, rather than the yucky 2 RVQ bins. I actually haven't gotten a chance to validate the noise audio all that much, as I think right after getting everything running again, I crashed out.
Additionally, I reused the
proms_emb"when loading the state dict, handle resizing it when adding in the special tasks tokens / adjusting theprom_levels" code to also adjust theresps_embwhen increasing the output quant-levels (for the NAR mostly). Doing so, I ended up growing a wild hair and ended up in a rabbit hole of sticking to targeting 4 RVQ bins entirely (the NAR handles 3 levels instead of 1 now) to go ahead and bite the bullet to try and aim for better quality sounding outputs. I should have probably stuck to the full 8 while I'm doing this already, but I think the difference between 4 and 8 with Vocos is very much marginal.Having said that, I did also bite the bullet and toss another $50 into rental training, but this time on 4x4090s instead; at a batch size of 64, it can eat through an "epoch" of 3.5k speakers in a minute, a huge increase over my one 4070Ti eeking out at about 10 minutes to do so. I think the way to try and fully utilize cards with more oomph to them is through increasing the RVQ-bins being processed, rather than increase the batch size, but this is just conjecture at the moment. I'm mostly using this to try and bring the NAR back up to par now that it has to contend with two more RVQ bin levels to output and kind of repairing the AR (doing the tasks training this early had its problems).
While I'm doing this, I'm putting the quarter-sized model under a similar treatment on my 4070Ti, where I'm pivoting from targeting 2 RVQ bins to 4, and letting things re-bake to help it out. I trust there'll be enough progress from the both of them over the course of the ETA 22 hours until I burn up the credit I spent on runpod, just in time for the weekend to be over.
Aside from those detours, I'm hoping (coping) that this is the last of the detours and I can go back to shutting the fuck up and letting the model train without interruptions. Worst case, the final interruption would be to add in more data to the dataset.
Just wish I had some audio samples or metric curves to provide, but my logs are completely tainted. Although, I think at this point the training metric curves are useless as any progression in the losses/accuracies are very noisy.
Eh, I guess I can provide samples: early this morning and a few minutes ago.
The actual speech sounds fine and mostly-consistent, I say an arbitrary 70%, but it's still not as consistent as I want it to be. The errors I can pinpoint:
Training on the 4x4090s is being a bit of a pill. I woke up this morning to it already running out of diskspace but somehow kept running? I had to stitch together the good checkpoint of the weights with optimizer states of the last known checkpoint, and restart from the FP32 weights. After going back to sleep and waking up again, I feel like the training kept resetting itself a few times as I'm not saving often enough, and I suppose if one device OOMs, then it'll hang and not properly save. I thought the old implementation handled that fine, but I suppose I botched something over time.
Either way, I think I need to wait for the NAR's outputted RVQ bins 3 and 4 to mature again. It definitely picked up the pace over the few hours overnight I had it train on just that, so I expect the rest of the day to be rather fruitful. I still haven't gotten a chance to test finetuning if it will magically save my hide. I hope so, since I can at least release the weights with good confidence if it can easily be finetuned into something competent. I just really do not want to release the weights when it outputs nothing but unsalvagable doodoopoopoo.
And if not, I suppose I'll have to accept the offer to accept the offer for using the A100s/H100s. I think the training protocol is solid enough now that I can comfortably either:
Regardless, I'm HOPING that I will finally get somewhere by the end of this week for sure. I think I have exhausted all possible detours now, and I just need to shut the fuck up and let it train without being wishy-washy.
alsothere'sthequartersizedmodelstillbeingtrainedbutIfeelit'sagenuinefool'serrandtoexpectittoproduceanythingfruitfulatthtispoint
One more sample batch: here
I suppose in hindsight it's obvious that I should have been paying much more attention to the input prompt being fed rather than just comparing it to the target reference clip. A lot of the generate output does match against the input prompt being fed, although there's still a few times where the output is a bit busted and breaks. Notably, I did hypothesize with being able to generate a "random" voice with an empty input prompt, and it seemed that one of the evaluation output did do just that with a piece of dead air in the input prompt.
Sucks I don't have any consistent metrics now that I've been pushing back and forth the models between my 4070Ti to the 4090s I've been renting; I wish I knew how many samples / epochs (in terms of the dataset) have passed now, but if I remember right, I think about a little under an epoch for the full dataset (two epochs for the reduced dataset that makes training more stable) have passed, so I suppose this puts my weights at five epochs worth of data compared to the whole dataset?
Regardless, I'll probably dump another $50 to keep the model training for another day as it seems to be cleaning up things rather quickly with 4x4090s to handle it. I'm having my 4070Ti handle transcribing and processing LibriLight-6K proper to supplement the dataset for when I do release it alongside the weights.
I should probably use this time as well to play around with inferencing again and finetuning the weights with my 6800XT idly sitting around, but it's just a bit of a chore to export and jettison the weights from the rental rig.
Hey @mrq , I sent you an email to mrq@ecker.tech reaching out about some things. Let me know if you’ve seen it and are able to respond there, thanks!
mmm.
I suppose I'll generalize-address it to the other people with similar propositions (including one from a month ago that I feel a bit bad for just now catching). I'll preface that I do not intend to be abrasive, blunt, mistrusting, or a schizo, but it'd be better to bite my tongue for most of my thoughts and be curt about it than spend another hour (out of the probably three I've spent trying to make things "elegant"):
While I do appreciate the offers to converse and collaborate, out of my dozens of copes I had to redact from giving:
I'm going to have to decline.
Gomen.
I forgot to also provide some more samples: pre-pivoting to the full dataset and post-pivoting to the full dataset ("full" dataset being without reducing the dataset to utterances shorter than 8 seconds to increase throughput).
I'm using the last days worth of credit on runpod on 4x3090s to try and wrap the model up with being fed longer utterances again to see how it shapes up, and, I think it's for the worse right now. While it's probably only a difference between maybe 1000644*4 samples, I feel the latest evaluation/validation outputs sound worse. At least I've made backups in case I do need to revert, but yeesh.
On another note, it appears that the 4x3090s have a rather similar throughput to the 4x4090s. Kind of sucks, since I could have just used those instead of the 4090s that are almost twice the price. Especially sucks, since I could have just bought a 3090 to begin with instead of a 4070Ti since there's effectively not much of a difference between Ampere and Ada for this workload.
Oh well. I shouldn't try and sweat over it so much and get some rest while the model continues training and my local system is properly preparing and transcribing 6K hours of LibriLight.
@mrq Appreciate the response, and I totally get it. Thanks for letting me know, and good luck with all the work you’re doing here.
Although, if you do have any questions, concerns, suggestions, whatever about using mrq/vall-e itself, I'll be happy to help out. I feel that the documentation still is pretty lacking, not straightforward to use, and digging through here for a detail is a fool's errand, so any outside input helps.
More samples, same kind of remarks: it sounds better after giving it more time from re-introducing longer utterances, I'll need to do inference tests to see if it did correlate to stabilizing longer utterances, etc. etc. I'm giving it another day to train while my 4070Ti continues to transcribe before pivoting to finetune tests.
Oh joy, another new Zucc toy: https://ai.meta.com/blog/seamless-m4t/. It seems to aim to "unify" a bunch of translation tasks between text and speech, and not just with a demo, but with code and weights to.
mmm... I'm not sure if it's the recent introspection the past few days, or just constantly tending to the training and repo the past few days consecutively, but I'm feeling quite at unease. In the event I do fuck off for the next few days, I'll (finally) go ahead and jettison my weights and dataset here: https://huggingface.co/ecker/vall-e.
I'll preface that the model output is by no means perfect, I feel they're serviceable at best. Sometimes it beats TorToiSe output, but there's still too many inconsistencies I feel at the moment (I could probably apply a similar cope bandaid to TorToiSe's CLVP/CVVP and generate in a batch and pick the best ones of the bunch). Aside from that, it'll be a good starting point for anyone looking to try and train from existing weights or finetune them with their own dataset.
I'm also going to provide a "libre" copy of my datset in the repo too. "Libre", as it'll contain the LibriTTS/portion of LibriLight-6K in it, with all the other gray-ly acquired data left out; the donated audiobooks that I'm still grateful for, the rips from muh vidya, etc. are culled. While I've been occasionally watching my 4070Ti transcribe LibriLight-6K proper, I'm reminded that the biggest hurdle is the dataset when training a model, and it would be very beneficial to anyone to have it as a starting point.
For sure, having an already prepared dataset is very helpful. I had tried the script for your provided dataset that you had in the readme, but there were errors unpickling the audios that I couldn’t resolve. Maybe that is just due to dependency differences.
What kind of latency are you seeing with the model compared to tortoise? Tortoise was too slow, I’m expecting vall-e will also be slow without quantization and/or model distillation.
Yeah, the prepare_*.sh scripts have been relics from several months ago when it was for quickly preparing a dataset to train with on rentals. I never got around to replacing them since I had my own draconian method to prepare the datasets.
I might go back and provide a script to create one from a pile of audio files instead, but it would have to be predicated on replacing/rewriting AIVC.
I need to do proper benchmarks, but inferencing with VALL-E is very snappy even with the weights at float32 after giving the inference script some love.
resps_length - 1passes.I'm definitely pleased by the speeds I'm getting now with VALL-E, and I feel there's much more room for improvement. Compared to TorToiSe, the only limiting factor is the AR's throughput speed (the NAR and EnCodec/Vocos decoding are practically instant for all intents and purposes) instead of TorToiSe's batching in the AR + CLIP/CLVP candidate sampling + diffusion sampling + vocoder.
Having mentioned getting 75% real time speed, it sort-of opens the idea of having streamed output in real time (or at the very least, buffered), but:
It's just a thought that crossed my mind yesterday. I don't expect getting around to toying with it anytime soon, but it's something that can be done that TorToiSe (and I imagine a lot of other neural TTS systems) can't.
Streaming is very valuable but yeah it is surprisingly tough for most things.
Looks like you’re moving forward with RetNet, right? Why is that when the “vanilla” (no recurrent steps) transformer architectures are much more tried and tested at scale?
I might as well. I've put the most training time into this current model (ignoring when I've spent several weeks on a deadend model with ~500 hours of data and the worst LR scheduling imaginable).
I'd have to retrain from scratch, as the previous attention-based weights are rather flawed from a lack of punctuation in the phonemes. I could salvage it with gumming up the phoneme symmap, but why bother.
Ackshually, the RetNet implementations work without needing to use the special recurrent_forward / chunkwise_forward passes; to my understanding those routines re-leverages some "internal states" from the initial pass to offer a throughput increase for little to no extra cost.
The analogue for attention-based transformers (or at least, GPT) would be a KV-cache (which TorToiSe uses but incurs a memory cost, and I believe didn't work under DirectML).
Training.
I've noted that the progression of training seemed noticeably faster in comparison to the attention-based "experiments", where the model reached a given loss/accuracy much earlier along the epoch, and if I recall right, specific traits emerged earlier too; I felt it was good at capturing the acoustics much earlier, and while I felt speech wasn't as precocious as I'd like, it still emerged rather quickly from being concerning to passable.
The reduction in the model size, and the optimizer tending to less parameters, led to enough of a sizeable reduction in VRAM usage I was able to pass the savings along to a larger batch size, leading to much better throughput in training.
However, the RetNet's literature mentions attention-based transformers under 2B parameters still outperformed the RetNet, and only until after that do RetNets outshine, but I can't really say for sure if it's true or not without training another attention-based model.
Sure, I suppose by sticking to an arch that still has yet to have any actual use in the wild, I'm opting out of all the other bandaids like xformers or flash-attention or whatever warts to cope with how intensive transformers can be. I'm fine with that, partly because I really do not like those bandaids and how much extra complexity gets added, and the other part is that it never got that far in scraping for savings for TorToiSe.
mmm...
Training is paused for the meantime on the runpod rentals. The improvements seem very marginal now, and I think I'm starting to hit a wall with how much continued training with a low LR will get me. I should be training it on the SpeechX tasks, but desu that's both low priority right now as the entire point of this is zero-shot TTS, and I feel is something I should supervise on my 4070Ti locally and not experiment on rentals. Besides, with LibriLight-6K properly being added, I feel it would be better to wait until then.
The LibriLight-6K transcription finished two days earlier than expected, but quantizing everything is quite the pain with a measly 25it/s and a lot of utterances. I expect two days until it's finished. I could try and speed this up with batching for EnCodec, but sequences will be padded to the longest sequence in a batch, and I'm not so sure if there's an intuitive way to unpad, although I'm sure the answer would be obvious when I try and bang my head against the wall to figure it out.
I don't know. I want to focus on improving zero-shot with more speakers in the dataset (which I won't gain any new speakers, as I already had some weird portion of LibriLight-6K in it already), but I still need to focus on getting consistent utterances outputted, which more utterances per speaker is the answer to that (as proven when I added the donated audiobooks with fewer speakers but many more utterances per speaker). The other side is that zero-shot doesn't seem all that bad, as it does copy the input prompt, but it's the input prompts themselves that are flawed at times and causes problems, so I might just be chasing the wrong animal entirely and need to better improve my methodology in sampling input prompts.
Oh well, I should have my answer soon on what's best.
I'm looking to make use of multiple GPUs, but for all scripts used in the repo, looks like it's overriding my PyTorch DataParallel settings, etc with whatever's being set by deepspeed. Struggling to find where these are set in the configs (where are the deepspeed configs?). Are they here?
Most likely. DeepSpeed handles whatever distributed training initialization it calls for. I don't recall if you can specify a communication backend (nccl, mpi, etc) through command line arguments passed to DeepSpeed or requires me setting it under
./vall_e/engines/deepspeed.py(do to the nature I'm invoking DeepSpeed, it needs an explicit call somewhere to initialize the distributed shit)../vall_e/config.py:271correlates to theconfig.yaml'straining.deepspeedsection and generating the DeepSpeed config on the fly (with values that work for me but I'm sure needs saner defaults, especially for ZeRO and quantization/compression training).You can override any de-facto DeepSpeed config values by providing a JSON under
./data/ds_config.json(per line 361) with what it normally takes from this mess of documentation.I honestly forgot I've had that override in from the very beginning as I never ended up using it, and I should have it set to instead use
f'{cfg.cfg_path}/ds_config.json'for overrides.Thanks, I'll look into that.
And what about model size? How do you control that currently? I didn't see any params for it in config.yaml.
Currently guided only by presets:
quarter,half, andfullhere and in the YAML here.I need to add in a way to either specify model size or preset size for better control (for example, size being a dict defining tokens/dim/heads/layers or a string specifying a preset).
Idle hands are truly the devil's workshop.
I'm getting tempted to make another poor purchase decision. My gut wants to go with a 7900XTX despite:
If I do cave and it's a bad investment, I can always sell it or return it within 30 days (although, that was my plan with the 2060 when I needed to debug a Vulkan-based engine of mine with, when it turns out my Steam Deck had the same issues as Nvidia cards).
Keeping the sinful thoughts at bay, I've been doing cleanup while I wait for LibriLight-6K to finish quantizing/phonemizing.
localbackend.pykakasito romanize the text, and it seems that the phonemizer can process romaji with the segments backend, but the outputted phonemes don't seem consistent with the IPAs from English + espeak.Should have forced myself to use the downtime as a brief break, but the unease will push me to keep working anyways. Oh well.
I've been theorizing in my head the next course of action with training, and I think I'll just resume training (from the previous weights, I don't think the issue of Frankenstein-ing datasets of the past will be an issue) with the content editing SpeechX-task enabled (alongside base TTS) with the full LibriLight-6K. These two in tandem should help bolster the strength of the model to generalize and not be overtrained.
As for my decision with just using the content editing SpeechX task:
I suppose I'll go back and try and benchmark my 6800XT to get the best ROCm performance possible out of it before I make any purchasing decisions.
I managed to get pytorch2.1.0+rocm5.5 working on my 6800XT but not rocm5.6 (segfaults with the nightly and the precompiled
python-pytorch-opt-rocmfrom the AUR).With apples-to-apples settings:
It's not even really worth trying to increase the batch size for the 6800XT to try and close out the gap; it's not feasible to gimp the 4070Ti to train at float32. I suppose it's better to compare AMD vs Nvidia with a 7900XTX. Bleh.
Additionally, while trying to make
recurrent_forwardwork, I think I managed to finally fix the issue with inferencing. It seems thatchunkwise_recurrentdoes in fact work, and it was actually being used. It was not only harming the output, but also performance. Consistency seems to be boosted, but there's still a few hiccups.My 4070Ti is able to top out at an orgasmic 105it/s while the 6800XT barely peaked at 40it/s at float16. With float32, the 4070Ti peaked at 80it/s and the throughput dropped to 60it/s, while the 6800XT maintained a constant 34it/s.
I'm going to do more inference tests just to validate this did in fact fix everything, but my test inferences are in fact working.
On the other hand, I did try and take a crack at making use of
chunkwise_recurrentand I don't think there's an elegant way to make use of it, unless I'm just stupid and am using the wrong way to sample the logits. The output is destroyed no matter what I try.I think I've got everything I wanted to do done before the next training session, so I can just leave the GPUs (yes, plural) training and shutting up for a while (or at least not overworking myself).
largedataset that I really don't want to touch right now.[unknown dataset size].python3 -m vall_e.data --action=metadata), helpfulmetadata.jsonwill be generated to store, in each speaker folder, a JSON where the keys are the IDs, and the values are the duration/phoneme lengths. This helps speed up the validation step (culling data not within a requested size) a shit ton, as even querying the HDF5's attributes takes some time, and when not using an HDF5 dataset, the phonemes/quants have to be loaded to query this.pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/rocm5.5) is the sweet spot, as pytorch2.0.1+rocm5.4.2 lacks bfloat16 and is slower (I suppose as evident with the 6800XT), and pytorch2.1.0+rocm5.6 segfaults still, no matter which nightly I install OR using the AUR's precompiled copy of pytorch2.0.1 (I'm currently trying to compile it again, but it just threw a==> ERROR: A failure occurred in package_python-pytorch().with no helpful info.)@torch.inference_mode()has better optimizations). The 7900XTX tops out at 40it/s compared to the 4070Ti's peak 110it/s (but drops off rather fast to 75it/s). I imagine getting recurrent_forward/chunkwise_forward working would close the gap, as I had accidentally left recurrent_forward enabled and the 7900XTX had better throughput (110it/s in the prefil, 90it/s after).I just hope my efforts and impulsiveness pays off. At worst, I'm 2xing my training throughput, although I wonder if I should have done this earlier. I hope I can get some peace of mind now, although the smell of a new GPU is plastered onto my face (better than having the smell of not-so-clean gas mysteriously clinging to me like yesterday).
I suppose I'll follow through and just let things train and shut up for a few days now.
mmm... I think it's foolish to continue running training on the existing weights.
I don't know. I feel fate is telling me there's no point in trying to continue training with these weights. I just don't understand, since the models are using the same dimensions and what-not as the paper at full size.
I suppose it's what I feared: not knowing what to do when it gets to this point. I suppose I'll chip at processing the
duplicate4K or so hours of the LibriLight dataset for I think 800 more speakers? And by the time it finishes in another week, I'll evaluate the logistics of committing to increasing the model size, probably only the AR to 20 layers.I'm just posting to inform you that vast.ai is just a nugget for GPU cloud, often 3x cheaper than runpod for 3090/4090/A40.
The trick is to activate "Unverified Machines" (some machines may have a problem at first, it happens rarely).
However, the price of bandwidth also has a cost, determined by the vendor, so some are free, but it's easy to find very good deals.
Like here I see 4x 3090 at $0.496/hr or $0.678/hr if you want free bandwidth.
Ah I see, I didn't notice that every time I went to do price comparisons.
mmm, seems to be the bit of a monkey paw. I'm already sifting through them and a lot of them "recoup" the low price of having high upload/download per TiB.
I don't have to constantly sync and backup the training states, but the dataset's HDF5 alone is already at 100GiB, even with lz4 compression, but:
I'll keep that in mind if push comes to shove and I need to go back to taking the rentpill.
I think I've got a good wrangling of any electrical-related issues over painful trial and error and isolation over the past few days. Turns out there's quite the rabbit hole that I just so happened to be ignoring. As a bit of a redpill:
Aside from that, I'm going to have the 4070Ti take a crack at transcribing LibriLight's
duplicatedataset before doing tests with extending the model to more layers. It'd be a good time to try and take it easy again, but not completely devoid of any work that it'll eat at me for wasting a week.The more important reasons I'm writing an update:
Back into my cave I go for the next few days, I hope I can get better results with increasing the layer size without it being that much of a detriment to iteration rates OR VRAM consumption.
It looks like the original vall-e model used ~140B parameters. That can't fit into a 4070 can it, so are you using a smaller model size? Does
size: "full"correspond to the original paper model size?Where'd you get that number from? The papers (VALL-E, VALL-E X, SpeechX) don't mention a parameter count anywhere.
NaturalSpeech2's paper on page 19 mentions its parameter counts between every component, and twice mentions "scaling [...] to 400M parameters".
Voicebox's paper on page 9 mentions 330M parameters for the audio model (the difference being 24 layers instead of 16 layers, and some funny connections between layers).
From the paper,
fullcorresponds to the original dimensions of the model:which yields the AR and NAR having ~200M parameters each with the RetNet (I need to check the parameter count for the attention-based transformers). The feed-forward dimension is marked as 4 *
embedding dim.Now, the general consensus (or rather, what G**gle results mentioned) says that widening a model (increasing the dimensions) is better than increasing the layer count, although seeing voicebox increase the layer count seems to be the contrary to that nugget of wisdom. It just sucks, because this means I might have to conduct two experiments to pick a wider model over a deeper model.
Now, the other day, it crossed my mind if it would be better to either provide a transcription to the input acoustic prompt, and/or have it try and "continue" off from a given input acoustic prompt, to try and help steer it into more natural output. Coincidentally enough, while checking the paper if it mentioned a parameter count, there's this little detail:
In other words, the paper mentions two "modes" to sequence with, and it seems the original implementation I forked from enhuiz/vall-e didn't really take this into account.
Base VALL-E will have its sequences as so:
On the other hand, this mode will sequence as so:
where inferencing can be done as:
The original enhuiz/vall-e implementation never took this into account, so I never thought it was that necessary. The lifeiteng/vall-e (and naturally, the Plachtaa/VALL-E-X implementation, as it's a fork) has a prefix mode that I admittedly never looked much into since the documentation is rather rough, so it might take this into account, but I can't say for sure.
Now, whether implementing a
continualmode is all that imperative, who knows. The paper has comparison test scores between the modes and, while the word error rate is much lower for VALL-E continual, the speaker similar score was lower, so it seems I shouldn't really bother with this, as I moreso care about speaker similarity rather than reducing the WER.It shouldn't be too much effort to add it in, and even inferencing in this "mode" requires no code change, just putting the transcription of your input acoustic prompt before your desired output phonemes. I just feel like training with this mode in mind isn't going to amount to much of anything.
I had gotten that from here, but I think yeah it is just plain incorrect and probably closer to the number you gave.
On wider versus deeper, it's kind of random, but if you have a deep "enough" model, you'll want to increase width instead.
Seems like someone ran someone else's article (and not the paper itself) into a weak LLM to summarize from how littered it is with hallucinations (the parameter count, the second limitation being an outright lie, the given use cases being very milkytoast [sic], the acronym for VALL-E it hallucinated isn't even a proper acronym, etc).
I suppose I'll just wing it with increasing the layer count and hope for the best, since:
Playing around with encodec encoding + vocos decoding. As good as vocos is, it still gives some minor audio artifacts for higher pitch voices. This puts an upperbound on the quality of the model, no? Maybe that can be fixed by some minor postprocessing?
Also, reading through the paper more, the split between AR and NAR seems inelegant. They want it for inference speed. Why not just use an AR with all the codebooks, keep the inference speed slow, but then distill the model later to increase inference speed?
Another question: how are you plotting your loss curves etc? Was going to write some code for it, but looks like you were producing them somehow. Maybe I missed them in the repo.
I imagine that's more of a bandwidth limitation that can only really be """solved""" with increasing how many RVQ bins the NAR outputs. Although, I only did a brief dive into how much additional quant-levels matter for more complex voices, rather than for voices outside a normal range.
A couple of things (apologies if it seems a little disheveled, I'll have my thoughts primed and the moment I try and express them it just fades and needs to be milked out).
I'll still keep it in mind as an avenue for improvement. MusicGen's paper shows interleaving works, regardless if music is more "complex" to try and model versus it being able to leave a little more room for error. I just feel it should be something to explore later down the road, like when I can get RetNet's dedicated recurrent/chunkwise sampling sounding right (more on this later) to help reap the benefits of a pure AR.
This repo (mrq/ai-voice-cloning) repurposes the training tab for TorToiSe/DLAS's metric graphs, but I have a myriad of gripes about it (kludge mostly) with that approach, so I'll shy you away from using it.
Now, I was doing some housekeeping with the mrq/vall-e repo itself and stumbled upon this under
./scripts/plot.py, but it needs a bit of rework.It's a bit rustic, and I'll see about cramming it into the main package and have it derive most of everything from a provided YAML, but to invoke it now, it's:
As an aside update:
tts-c) just to help try and mix up the data. It doesn't seem to offer much of a difference in terms of loss/accuracy and output, though. I do need to extend the inferencing to allow for this guided mode as well, but it's low priority.duplicate4.5K hours of data is still transcribing off my 4070Ti. Extenuating circumstances had me wary of having any GPU workload for the past few days, but things seem fine now. I've also done some housekeeping in my current dataset of culling a lot of useless voices I've had in the beginning, and removing speakers from LibriTTS-R that are in my LibriLight-6K, as I felt it would be better to try and make an "epoch" of visiting every speaker smaller.I suppose I have to train the AR from scratch if I want to increase the layer count. There's been no perceptible change in the model after training it about a day.
On the other hand, training the new AR from scratch seems to be very fruitful, at least metrics wise:
ar.loss.nllmetric, and even then training might have been a bit flawed as I don't remember how long it took during that training run for me to correct that.tts-ctask ahead of time), since the previous sampling method wasn't very explicit in what it was doing.I'll let the AR train from scratch at this point and see how it fares before making more claims, such as:
I figured I wasn't going to do anything leisurely today besides sleep, so I elected to work on an interleaved AR. Initially, I was going to say it was very much not fruitful, but after doing the very simplest approach (just use
codes.flatten()andcodes.unflatten(...)to interleave/deinterleave), I managed to get the test trainer to output this: https://files.catbox.moe/5ynjcv.wavI am not happy with the crackle in the beginning. I am not happy with the inference speed effectively being reduced 4-fold. I do not expect RetNet's chunkwise sampling to save me as I'm pretty sure the next RVQ-bins depend on the previous one like the NAR does.
I did do another test trainer run and got: https://files.catbox.moe/t3uyvi.wav. There's no nasty crackle, so I suppose the model architecture is fine enough to further test on training real data against. But, I don't know. I'm kind of happy with the new-deepened AR already being at 72% accuracy despite only being 3% through an epoch's worth of data.
mmm... I guess I'm due for a bit of an update.
And speech is emerging once more.
As for experimenting with an interleaved AR: I'm not too sure if I should bother with it.
resp_emb, though. As it currently is implemented,n_resp_levelsis fixed at being 1. Some clever positional embedding could work too alongsideresp_emb.I don't know, once more. My 4070Ti is sitting idle, as I'm not too sure it has the VRAM for me to train a NAR at double-depth, but I suppose I can pivot to using SGD and a high LR and hoping for the best, especially when a NAR has faster throughput rates compared to the AR.
However, I think, instead of an interleaved AR, I could experiment with training a model that handles both the tasks of the AR in an autoregressive manner, and the NAR in a non-autoregressive manner, as:
When I get a moment I suppose I can run the test mini-trainer to see how it fares, and if it works, then I suppose I can throw it on the 4070Ti to train at 24 layers.
I feel rather silly.
I imagine the lifeiteng/vall-e implementation had the right idea with having an (almost) single model that handles both AR and NAR tasks. It's doable, and I like it as an option better than an interleaved AR approach. Some things to keep in mind:
resp_embto be split, where a dedicated one exists for AR tasks, and a dedicated one exists for NAR tasks. Without it, the model just won't perform properly. I'm not too sure why, as the providedMultiEmbeddingshould be able to handle this. I do wonder if the NAR tasks will perform better if there was a dedicatedresp_embper RVQ-bin level.quant_levelto train against for each sample in a batch. Training a dual model might require double the training time anyways, as I have to randomly decide between training for the AR or training for the NAR. I don't think I can have the forward pass procedurally decide whichresp_embto select (or at the very least, which weight for the embedding) and have the target sequence to compute the loss against procedurally formatted for a givenquant_level. Besides, it's probably for the better to have the first RVQ-bin level considered more than a single remaining RVQ-bin level, as the first level is rather important.I do like the idea, as:
resp_embout of thin air.However, I'm not too sure how it would perform, as I'm basically foregoing a "mixture-of-experts" approach with a monolithic approach. I'll need to evaluate which card would get which model to train, as I think I should pivot the double-deepend AR to the 4070Ti, and train the monolithic AR+NAR on the 7900XTX at an increased model dimensionality to make the parameter count higher (1536 dim / 24 heads / 48 layers) or something similar.
Also it seems that the provided attention-based transformer requires less parameters than a RetNet. I'm not really sure why it freed up VRAM when I pivoted to a RetNet.
I think I'm pretty pilled on using a monolithic AR+NAR.
I was training a half-sized monolithic model on the side (also making use of prodigy, major props), and even at 25% of the epoch processed, the AR-side of the model was already reaching ~73% accuracy, while the NAR side was looking a bit rough at ~44% accuracy, but that's expected. I don't have any samples since I forgot to meddle with the evaluation / validation routines to be aware of a monolithic AR+NAR (it seemed it was falling back to treating it like an AR), so I'll need to go back and yank out samples.
Now, I don't know if this is a testament to prodigy performing really well with getting it up to snuff, or a monolithic approach to the transformer (/ RetNet to pedantists) is what helps bolster the model.
I suppose the next few days I'll see about converting existing ARs into a monolithic approach.
prom_emb/resp_embs to the ~new~ way with my good full-sized AR weights.prom_emb/resp_embs, train for a bit until the AR seems to be back up to par, then train again with the main transformer (/ RetNet) weights unfrozen, since it still needs to be re-tuned for NAR tasks.I'm rather happy that I'm at a point to where I can start stepping out of the previously established comfort zone and start toying with things more and more. I just hope that I can get around to figuring out how to implement the more fancier sampling techniques like repetition penalties and what-not, since I don't have the luxuries from using huggingface wrappers like TorToiSe does for these things.
Also the double-deepened AR is rather fruitful too at 28% through the "epoch": samples. I only picked at some of the validation and I'm rather pleased. The only issue is that I wonder how many issues are from re-using my previous NAR as a supplement, since I feel some samples over time felt a little too compressed in terms of the range (where it sounds kind of muffled I suppose, no additional detail to help resolve any nuances, blah blah). I'm very pleased that it won't hit a flat wall in terms of loss/accuracy and approach a loss of ~1.0 / what I believe is 90% accuracy.
Before I go fuck off and let the models train for however long, a status update (in no particular order of importance):
full-sized AR is going along fine (samples), enough so that I opted to pivot the double-deepend AR to a monolithic approach, and so far it seems okay right now: (samples).resps_embto shape[0] = 4, and randomly initialize weights[1:] so the NAR'sresps_embcan train better (glueing a NAR'sresps_embis not helpful). It's probably better to not freeze any parameters so the main weights can be better trained for NAR tasks.I think I've crammed out everything I can think of. In my brief inference tests, whatever model I did end up testing seemed rather fruitful with short GLaDOS tests. Nothing fantastic, but it's definitely better than what I remembered.
I'll probably leave things be for another week as I think I overdid it again, so the 4070Ti is currently convert-training the monolithic
fullAR, while the 7900XTX is back to converting the monolithic double-deepened AR.@mrq have you tried https://github.com/Plachtaa/vallex-webui ?
pretty decent
the author say they use https://github.com/lifeiteng/vall-e for training code
with small modification
I gave it a cursory glance and I find it rather impressive, considering what I remember from the previous unofficial/homebrewed weights. I'll need to muck around with it more to test it capabilities, as I know my models have quite the issues I've noticed so far.
I'll reserve my judgment from my biases towards the base implementation being a pain, and the web UI and documentation taking too much inspiration from Bark in how it goes about things. If it works, it works.
I am curious, though, what the dataset looks like. The "model card" doesn't give much information outside of it being a bog-standard full-sized AR and NAR (separate, proving my assumption wrong as I looked at the implementation again) that targets 8 RVQ-bins. I'd be surprised if it was the full 60K hours of Librilight + whatever else LibriVox has for Japanese and Chinese.
Although, regardless if that model and implementation takes off, and/or mine finally gets to a decent output quality, my bigger fear is that the "sphere of voice synthesis" will still be rather stagnant in just waiting for someone else do improve upon things due to the lack of eyes on things because there's no model leak from big conglomerate (like Stable Diffusion was originally, or LLaMA was originally).
I suppose I'll go back to shutting up, not overworking myself, and not stressing over the model and let things train for another week and see how it fares. I just worry that I'd be better off training from scratch again, so perhaps I should set things up to be able to train off a rental again.
Don't expect any updates for a while.
Both the full sized model and double-deepend models are being retrained from scratch and not stitched and glued from existing ARs to the monolithic approach and now to the full eight RVQ bins. From the outputs so far it seems that it's much better in the RVQ bins 2-8 department (what the NAR targets), but actual speech is still waiting to be realized.
I did add a naïve implementation for beam searching a few days ago, but I don't know how well it fares. I feel the more I play with the instance running on the HuggingFace Space, I feel the worse the model really is.
These graphs aren't looking so great either, but that's probably just the nature of bruteforcing the model to randomly pick each level for each sample in a batch. I just hate that the computed loss/accuracy is rather useless now, and the aura-loss computed is still very forgiving when it's not factoring in the actual speech (or lack of it).
Oh well.
I lied. I suppose there's quite a bit of updates I need to vomit out before I forget about them.
Turns out, the NAR has been trained a little wrong for months.
A monolithic approach definitely does work when trained from the onset as one.
prom_embstokens, and instead just having an embedding for these tasks tokens. This approach can also be used to add in a language identifier, rather than subjugating the text tokens after the fact.As for the models being trained (again):
rep pen: 1.3,rep pen length decay: 0.3,top p: 0.95,top k: 768,beam width: 16, player preferences for the temps. I think repetition penalty with a bit of length decay really helps shape out the outputs.I think this should be all the news I've kept in my head for those that are interested still.
I'm hoping I can stop stressing too much over the models the more I realize I'm under no pressure to push out a model, as I'm still able to keep improving the project without needing a decent model from the get-go.
So, I'm trying to overfit on just 3 speakers just to ensure I have things set up correctly. I'd like to query exactly same data from the training set to ensure everything is going fine.
Right now, I've been training for about 40 epochs (~4M tokens) and getting close to 60% accuracy with loss sub-linearly dropping. But inference comes out a garbled mess. At what point do you start hearing human-like sounds?
Right, I never went back to try and test training on much narrower datasets, as I was doing things entirely wrong with my initial narrowed tests. I know you can definitely overfit for one single sample, as the mini/test trainers do, but I don't think I ever got anything fruitful with just one speaker. I'm sure it's doable, as the lifeiteng/vall-e implementation has a training script on LJSpeech alone.
Token wise, I'll need to check my metrics. A problem I noted a week or so ago with DeepSpeed is that the tokens processed metric isn't stored, so I'll need to muck around in
./vall_e/plot.pyto correct for this. When I do, I should be able to pick out where along training it was in relation to tokens processed.But, I can say now judging from all my evaluation / validation outputs from the current model (the AR+NAR monolithic RetNet, I'll have to check the numbers for the previous split AR and NAR models):
Although it's kind of hard to say exactly when these milestones precisely occurred. I'll have to assume an average sample would be 64 text tokens + 75 * 6 audio tokens = 514 tokens per sample, so for now my estimated tokens for those milestones would be:
Again, I'm not sure how different a model's progression would be with a much smaller dataset, but if my first naive test runs are anything to go by, it'll take what feels like a loooong time.
Also I just realized the issue is working again. I'm not sure why it broke, or how it resolved itself.
There wasn't really anything noteworthy outside of:
I suppose the things I still have left to do is:
I'm asking about the accuracies and losses you see once it turns into human sounding (just trying to debug inference for my custom dataset). E.g. is it 50% acc, 60%, 70%, 80%? Since losses and accs vs tokens vary with hyperparameter settings.
I had a huge block outlining why using a loss / accuracy metric is a baseless metric to go by, but I've omitted it for coming off far too blunt.
Your magic number with the current monolothic AR+NAR is loss = 3.1, acc = 0.7. Enjoy.
Cool, that's useful for the purposes of debugging anyway. I do see in some of your earlier posts how sometimes quality versus loss/acc can be inconsistent.
Another question, I'm using the monolithic ar+nar. I see you have a model class that is ar+nar, but in inference.py you separately instantiate and call the ar and nar. Is that correct? I know there's an ar_nar class here.
Again, just trying to debugging my inferencing (could also be there's nothing wrong and I just need to wait for it to train longer).
Another thing that would be fairly useful for the ar+nar class:
Right now, you can only see the combined loss and accuracy. One thing that may be useful to adjust over time is the
p_ar_level. If I can notice the ar loss is high but nar loss is low, I can set thep_ar_levelto be high.So, is there a simple way to additionally emit the losses for ar and nar separately? I'll take a look at that portion of the code somewhat soon.
You were right, at around loss 3.0 I am getting human-like sounds (this is just on 30 hours of audio...). I was able to add some lines to emit the metrics separately. It looks like the ar loss is a good deal lower than the nar loss, which is in line with some of your prior posts. What's your intuitive thoughts on what the ar versus nar losses should correspond to?
AR corresponds to the first quantized level, whereas NAR is the other ones. So, canonically, the paper mentions NAR should correspond the acoustics and speaker voice specifics, whereas AR should correspond to more the actual text synthesis accuracy?
If I'm getting good acoustics but bad text adherence (i.e. it's speaking gibberish, maybe sounds like another language, but human acoustics sounds are good), wouldn't that correspond to low NAR loss but high AR loss? I'm kind of seeing the opposite right now: human acoustic sounds are fairly good but basically no adherence to the text (just gibberish). So, I would expect that to be higher NAR loss and lower AR loss, but instead I see the opposite (~2.2 AR loss versus ~3.1 NAR loss).
Curious to hear what your thoughts and interpretation of these values are.
The AR/NAR/AR_NAR classes just have overloaded properties and a forward to do the sampling proper. I can very much assure you it's correct, as both the HuggingFace Space and the web UI are both fine with the monolithic model.
The AR does heavily guide the "accuracy" of the utterance, but only for the fact that it's the dependency for the remainder of the sequences, as every level after will depend on the prior level. The NAR governs the "finer" details of the waveform, but only in the "each additional quantization level is effectively another Whittaker-Shannon sinc interpolation wave, but its effect on the final waveform is smaller and smaller, thus resolving finer details that prior levels cannot resolve" sense.
However, saying that the first quantization level is solely responsible for "adherence to the text" was a naive interpretation of mine. There's properties/details of speech that the first level cannot ever resolve, but the NAR can even with it targeting one level, and vice versa. This is evident in the past when I would include pure AR / impure NAR outputs, where details in an utterance are kind of there but were never quite enough to resolve consistently.
That's just the model knowing how to generate something that sounds human-ish yet chaotic, but cannot apply order (language) to it, or the nuances of it. In fact, the AR is usually the first to have speech emerge (or at least, be the one that sounds fine when it does), while the NAR will still like crusty shit at that point in time and have a bunch of artifacts (at least, in the non-monolithic models).
You should instead split your loss per RVQ-bin level rather than per AR (1 level) and per NAR (7 levels). You should see that, as the quantization level increases, the average loss should increase. Should, since I only know that when making the jump from a NAR that targets 1 level to 3 then to 7, the loss climbed up more and more. I could be wrong, and they're all higher together/in aggregate.
There's also always the chance that preparing the target sequence for the NAR to compute the loss against to be flawed again, as evident when the loss for it dropped a significant amount when having it apply loss calculations against the text too. But loss isn't a good metric.
I don't have any.
Treating the loss/accuracy as a strong metric for a model's performance after speech emerges is quite naive, as evident with the reported losses with auraloss during the evaluation / validation routines meaning nothing. Any training after that point is essentially bruteforcing due to the lack of a meaningful way to quantify the accuracy for speech and praying that training in much much smaller steps to try and align with the targets will iron things out over time (at the risk of overfitting).
It was in my omitted blunt blurb, but there's simply no way for a naive loss computation to account for the accuracy of the speech itself from an already neural sequence of EnCodec codes while retaining the logits.
Now, I say retain the logits, as with retaining the logits, then the model can be improved through the backwards pass. Doing something like "compute a word-error rate score to gauge accuracy of the speech" can't be done while retaining logits and thus updating the model through the backwards pass. However, I imagine something like reinforced learning can help improve the model with word-error rate as a metric itself, but implementing it is beyond my knowledge, and RLHF is synonymous with ethics alignment, so it inherently has a sour taste.
Besides that, and the site issues, microsoft/torchscale did some commits that breaks compatibility with existing models using its RetNet. It messes with the normalization method (LayerNorm => RMSNorm), removes biases from the weights, and uses a gated linear unit (just an additional weight and removal of subln) in place of a feed-forward network. Playing around with re-enabling each new feature has the model suffer tremendously, and from the test trainer there seems to be no apparent gains from using RMSNorm / no biasing / a GLU instead, so I will not try and glue things around again and end up crippling the model like I kept doing in the past.
I suppose I'll go back to shutting up and trying not to stress too much over the model as I've had for who knows how long before. I feel I should do my re-evaluations when it hits maybe 4 or 5 epochs trained (it's currently on epoch 2.4) before making any further decisions with the model.
Thoughts on StyleTTS2?
https://github.com/yl4579/StyleTTS2