Discussion About BitsAndBytes Integration #25
Labels
No Label
bug
duplicate
enhancement
help wanted
insufficient info
invalid
news
not a bug
question
wontfix
No Milestone
No project
No Assignees
7 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: mrq/ai-voice-cloning#25
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Completely not coping for a lack of discussion or any way to provide news to my users.My fellow gamers, I've struck gold once more with another impossible feat: training on low(er) VRAM cards: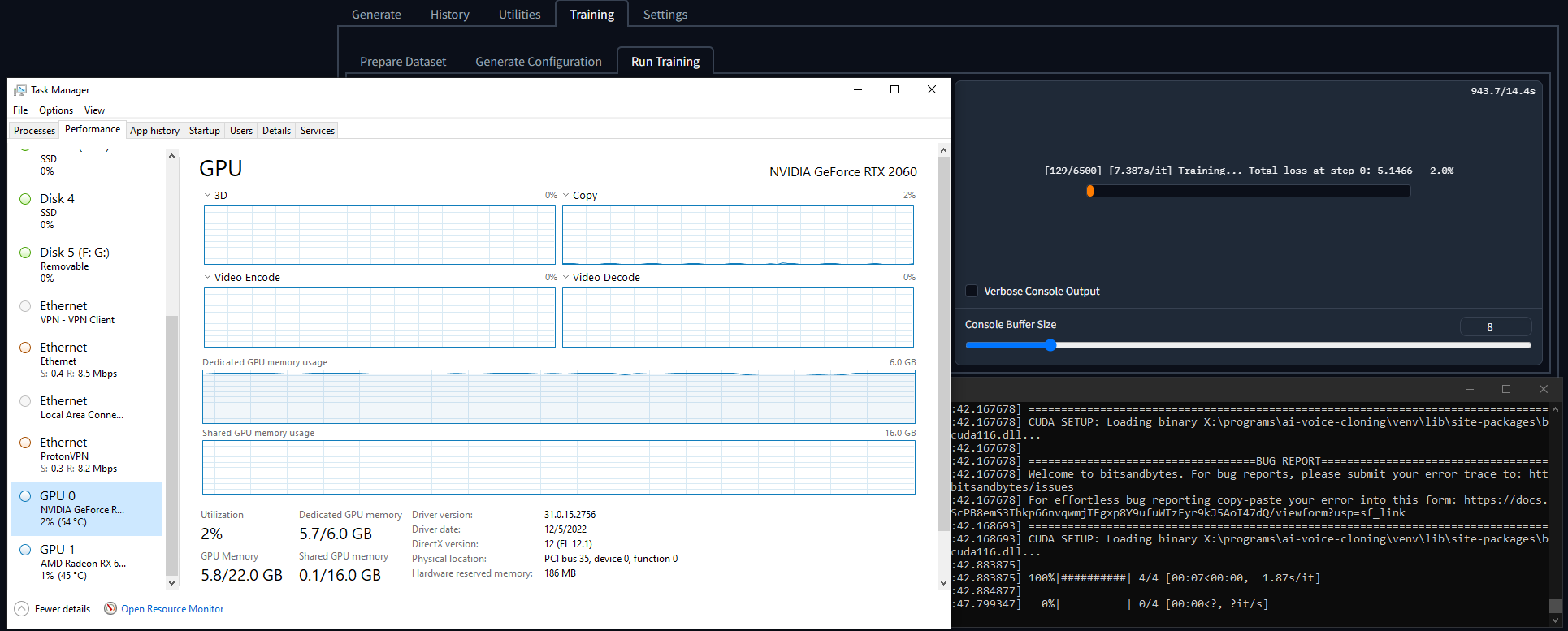
With it, I'm able to train models on my 2060 (batch size 3, mega batch factor 2).
These gains leverage TimDettmers/bitsandbytes, with deep magic wizardry involving quantization to net huge VRAM gains.
In short (at least, from my understanding of quantizing vertex data to "compress" meshes in graphics rendering), this will quantize float32 data into int8 and leverage special hardware on Turing/Ampere/Lovelace cards to compute on those tensors, achieving 4x VRAM savings, and 4x data throughout.
In theory. This should pretty much only quantize the big models like the autoregressives and maybe the VQVAE, and any performance uplift would come from anything bandwidth limited (to my understanding at least, I am not a professional). I honestly don't care about performance uplifts, as I'm moreso focused on reducing VRAM usage.
For now, I'm training both locally and on a paperspace instance with an A4000, and both seem to be training swimingly. I'm not sure how much of a quality hit either will have from training at effectively integer8, as float16 does have inherent quality problems.
Right now, it should be as easy as running the update script for it to pull an update to mrq/DL-Art-School and install an extra dependency:
bitsandbytes==0.35.0.On Linux, no additional setup is required. On Windows:
./ai-voice-cloning/dlas/bitsandbytes_windows/in one window./ai-voice-cloning/venv/Lib/site-packages/bitsandbytes/In the future, I'll include this for Windows in the setup batch files.
By default, the MITMing of some
torch.optimcalls are disabled, as I need to validate the output models, but it should be as simple as flipping a switch when it's ready.If you're fiending to train absolutely now, you can open
./ai-voice-cloning/dlas/codes/torch_intermediary/__init__.py, and change lines 16 and 17 fromFalsetoTrue.So far, I don't see any, except for annoying console spam on Windows.
BitsAndBytes also boasts optimizations for inferencing, and I can eventually leverage it for generating audio too, but I need to see how promising it is for training before I rape mrq/tortoise-tts with more intermediary systems.
Success!
I was able to successfully train a model on my 2060. I didn't have anyone come and break in and CBT me, nor are my outputs from a model finetuned with this optimization degraded at all, it sounds similar to a model trained without it (similar, I trained it up until the same loss rate).
I've tested training on Windows and on paperspace instance running Linux, so both are good to go. I'm pretty sure bitsandbytes won't work with Linux + ROCm, as the libs seem to be dependent on a CUDA runtime, so ROCm's
torch.cudacompatibility layer thing won't be able to catch it (on the other hand, you probably have more than enough VRAM anyways if you do have an AMD card).The only thing I haven't yet tested are:
.\dlas\bitsandbytes_windows\Hello. I have good news and a potential bug report.
I ran a 15 sample dataset, batch size 16, mega batch factor 4, at half precision. I ran it for 125 epochs for a quick stability test.
I ran this on a RTX3070 with 8gb VRAM.
The VRAM usage hovers around 7.2-7.6GB, but thankfully it never OOMed and it was able to complete its training.
However, after loading up this new model and attempting to generate a new voice, I get the following error:
Good to hear.
Not too sure how you managed to gum it up, but it should be remedied in commit
1cbcf14cff.@mrq I'm training with an approx. 100 sample dataset, with the exact same settings as you. It calculated the total steps as 15666.
(500 epochs * 94 lines / batch size 3)
When I start training, I get a progress bar which goes up to 31 (which is 94 lines / 3).
In the "Run Training" tab in the WebUI, in the progress counter
[x/xxxxx], 'x' goes up by one every time the progress bar completes. To my knowledge, that should be one epoch.However, the WebUI, shows the total steps
[x / 15666]instead of the total epochs[x / 500]. So the ETA is a ridiculously high number, and also it doesn't save training states as configured. (i.e. it won't save 5 times per epoch, but instead once per 4-5 epochs).Unless I'm misunderstanding and that's just how long it takes with bitsandbytes...
No you're right, there's a bit of a discrepancy. The training output will interchange iterations and steps, as evident here:
while I make the assertion that steps make up iterations, and iterations and epochs are interchangable.
I'll adjust the parsing output to reflect this. Goes to show that I shouldn't have done this mostly on max batch sizes.
As I understand it, when the progress bar in the command line fills up, it's gone through the entire dataset, thus one epoch is complete. This is reflected in the webui by increasing the value of
xin[x/xxxxx]by one. However, the value ofxxxxx, which should be the number of epochs (or iterations), is currently the number of steps (which is a much higher number obviously). So the progress bar fills up much slower, and the ETA is way off.I think that's what I mean as well, though I'm not sure
Right, that makes sense. Thanks!
Remedied in commit
487f2ebf32, at the cost of my Bateman finetune because I accidentally deleted it and not the re-test setup (oh well). Outputted units are in terms of epochs, rather than the incestuous blend of iterations and steps.Funny, since I was intending to make it show in terms of epochs anyways.
oh dear :(
By the way, another strange bug I've noticed sometimes while training is that if you have
Verbose Console Outputchecked, and are on the Run Training sub-tab, the training goes extremely slow, to the point where it looks like it's frozen. Changing the sub-tab or the tab fixes the issue, and the training resumes at normal speed.I have no idea what could be causing it, and if occurs every time, but I thought I'd let you know.
Not a huge deal, only the 5 hours I slept while it trained.
I'll look into it in a bit, but I wouldn't rely on verbose outputting since it interrupts the progress, and was a remnant of debugging.
Highly Experimental BitsAndBytes Supportto Discussion About BitsAndBytes IntegrationI keep getting these errors while training, did a clean install as well but it still can't find libcudart.so
Did you copy the files from
.\ai-voice-cloning\dlas\bitsandbytes_windows\into.\ai-voice-cloning\venv\Lib\site-packages\bitsandbytes\?The
setup-cuda.shscript should do it automagically with:copy .\dlas\bitsandbytes_windows\* .\venv\Lib\site-packages\bitsandbytes\. /YHi
I had the same error.
copy .\dlas\bitsandbytes_windows\* .\venv\Lib\site-packages\bitsandbytes\. /Ydidn't overwrite for me, I still had to copy manually.
Now it's training fine on 8GB VRAM
However, Cuda usage seems very low (just spikes no constant usage) and CPU is high at 95% avg constant usage
Will compare with same model trained on colab later.
Noted, I'll dig around for the right flags to assume overwrite (although I thought that was what
/Ydid). I guess that might explain why, despite doing that command myself on my main setup, it didn't update to remove all the nagging messages.That seems fairly right (the low GPU usage at least, I didn't take note of CPU utilization); I noticed on my 2060 that it was heavily underutilized during training (similar to how it is during inference/generating audio), while all the other training I did on paperspace instances had the GPU pretty much pinned.
I assume it's just because it's bottlenecked by low batch sizes. In other words, it's just starved for work because of low VRAM.
Turned out that I somehow assumed
copy/xcopyjust copied folders too, so all files should copy now for bitsandbytes.I didn't get a good chance to test with
Verbose consolewhatever, but I made some changes so it only actually stores the lastbuffer_sizemessages instead of just slicing every time, although that issue should have affected normal training.I guess this is related, I can't train on AMD anymore, seems to get stuck on bitsandbytes despite me unchecking all the boxes related to it in Gradio.
If you want to be a guinea pig, run:
It's a specific variant for AMD cards (Linux only). I was going to get around to testing it end-of-day-tomorrow when my impulsive hardware purchase comes in, but you're free to try it for yourself.
If that won't work, then you should be able to force it off by editing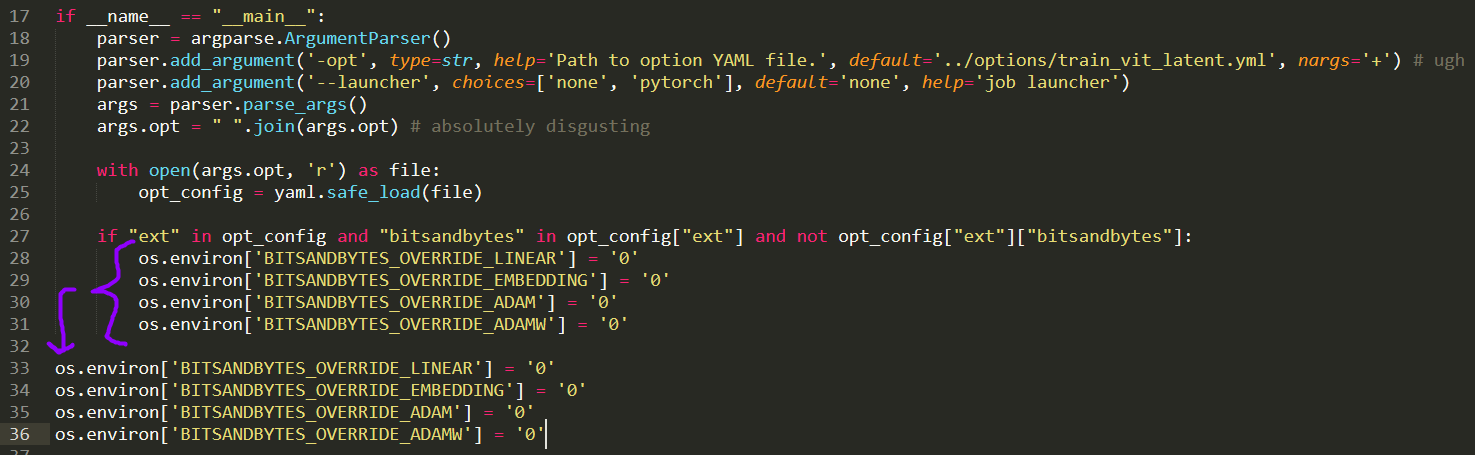
./src/train.pyand copy pasting this block:I installed the rocm version and can confirm it's actually started training now on my 6900XT, I'll drop an update in if/when the training finishes.
Naisu, I'll edit the
setup-rocm.shinstall script to have it install that.do get this "error" now when launching, might need removing or contextualising for AMD users
doesn't stop Tortoise from starting albeit
I guess I'll need to have the setup script do that. For now I'll just have it uninstall bitsandbytes when installing through ROCm, and tomorrow I should be able to get something cobbled to set it up.
Alrighty, I've successfully cobbled together my dedicated Linux + AMD system. Seems it's a bit of a chore to compile bitsandbytes-rocm. I might need to host a fork here with a slightly edited Makefile to make lives easier for Arch Linux users like myself (the fork's Makefile assumes
hipccunder/usr/bin/, but also assumes some some incs/libs under/opt/rocm-5.3.0/).It's faily simple if I didn't dirty my env vars. Just:
I'll validate this works by reproducing it with a script, and then ship it off as
setup-rocm-bnb.sh(able to be called for existing setups, and gets called for new setups)Naisu. Added the setup script for bitsandbytes-rocm in
e205322c8d. Technically you can deletebitsandbytes-rocmafterwards, as the compiled .egg gets copied over.I'm an idiot that bought a Pascal quadro instead of a 3090.
this is what I get:
I'm told it WILL work on training. After a slight patch that fixes cuda detection, it is possible to use it. Unfortunately it is very slow. About 1/2 the speed of FP16.