UnicodeDecodeError: 'utf-8' codec can't decode byte 0x84 in position 0: invalid start byte #292
Labels
No Label
bug
duplicate
enhancement
help wanted
insufficient info
invalid
news
not a bug
question
wontfix
No Milestone
No project
No Assignees
5 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: mrq/ai-voice-cloning#292
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
When start Training get an Error:
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x84 in position 0: invalid start byte
How to Fix it?
See #166
New Error. "Error no kernel image is available for execution on the device at line 167"
Do you know how to Fix It?
[Training] [2023-07-05T21:55:53.754053] Error no kernel image is available for execution on the device at line 167 in file D:\ai\tool\bitsandbytes\csrc\ops.cu
Traceback (most recent call last):
File "D:\AI\ai-voice-cloning\venv\lib\site-packages\gradio\routes.py", line 394, in run_predict
output = await app.get_blocks().process_api(
File "D:\AI\ai-voice-cloning\venv\lib\site-packages\gradio\blocks.py", line 1075, in process_api
result = await self.call_function(
File "D:\AI\ai-voice-cloning\venv\lib\site-packages\gradio\blocks.py", line 898, in call_function
prediction = await anyio.to_thread.run_sync(
File "D:\AI\ai-voice-cloning\venv\lib\site-packages\anyio\to_thread.py", line 33, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "D:\AI\ai-voice-cloning\venv\lib\site-packages\anyio_backends_asyncio.py", line 877, in run_sync_in_worker_thread
return await future
File "D:\AI\ai-voice-cloning\venv\lib\site-packages\anyio_backends_asyncio.py", line 807, in run
result = context.run(func, *args)
File "D:\AI\ai-voice-cloning\venv\lib\site-packages\gradio\utils.py", line 549, in async_iteration
return next(iterator)
File "D:\AI\ai-voice-cloning\src\utils.py", line 1953, in run_training
for line in iter(training_state.process.stdout.readline, ""):
File "C:\Users\dench\AppData\Local\Programs\Python\Python39\lib\codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x84 in position 0: invalid start byte
"Error no kernel image is available for execution on the device" likely indicates that you don't have CUDA installed correctly.
I don't know if the author solved the problem.
But this is a gtx 1080ti video card problem
It can be solved by strictly setting the version for torch==2.0.1 in setup-cuda.bat
you also still need to change the version bitsandbytes==0.38.1 in modules/dlas/requirements.txt (at the bottom of the file)
No not solved yet! I have the same problem and i dont know how to fix it. Can you please give me a specific instructio to solve it. I have a gtx1060 6gb.
(I have this problem)
[Training] [2023-10-19T18:37:13.854109] 23-10-19 18:37:13.297 - INFO: Random seed: 5458
[Training] [2023-10-19T18:37:14.655347] 23-10-19 18:37:14.655 - INFO: Number of training data elements: 66, iters: 1
[Training] [2023-10-19T18:37:14.659310] 23-10-19 18:37:14.655 - INFO: Total epochs needed: 500 for iters 500
[Training] [2023-10-19T18:37:15.640808] C:\Users\danik\ai-voice-cloning\venv\lib\site-packages\transformers\configuration_utils.py:363: UserWarning: Passing
gradient_checkpointingto a config initialization is deprecated and will be removed in v5 Transformers. Usingmodel.gradient_checkpointing_enable()instead, or if you are using theTrainerAPI, passgradient_checkpointing=Truein yourTrainingArguments.[Training] [2023-10-19T18:37:15.644798] warnings.warn(
[Training] [2023-10-19T18:37:24.986426] 23-10-19 18:37:24.986 - INFO: Loading model for [./models/tortoise/autoregressive.pth]
[Training] [2023-10-19T18:37:26.021187] 23-10-19 18:37:26.005 - INFO: Start training from epoch: 0, iter: 0
[Training] [2023-10-19T18:37:27.989015] [2023-10-19 18:37:27,989] torch.distributed.elastic.multiprocessing.redirects: [WARNING] NOTE: Redirects are currently not supported in Windows or MacOs.
[Training] [2023-10-19T18:37:29.995408] [2023-10-19 18:37:29,995] torch.distributed.elastic.multiprocessing.redirects: [WARNING] NOTE: Redirects are currently not supported in Windows or MacOs.
[Training] [2023-10-19T18:37:31.288200] C:\Users\danik\ai-voice-cloning\venv\lib\site-packages\torch\optim\lr_scheduler.py:136: UserWarning: Detected call of
lr_scheduler.step()beforeoptimizer.step(). In PyTorch 1.1.0 and later, you should call them in the opposite order:optimizer.step()beforelr_scheduler.step(). Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate[Training] [2023-10-19T18:37:31.289197] warnings.warn("Detected call of
lr_scheduler.step()beforeoptimizer.step(). "[Training] [2023-10-19T18:37:32.650757] C:\Users\danik\ai-voice-cloning\venv\lib\site-packages\torch\utils\checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
[Training] [2023-10-19T18:37:32.650757] warnings.warn(
[Training] [2023-10-19T18:40:58.104836] Error no kernel image is available for execution on the device at line 167 in file D:\ai\tool\bitsandbytes\csrc\ops.cu
@Arachnolog Arachnolog Sorry sure but i dont find the "torch==2.0.1 in setup-cuda.bat" what u had mentiond in ur previes comment. Can u please more specific where i schould search for it?
You just have to add
==2.0.1aftertorchin the install command.It should look like this.
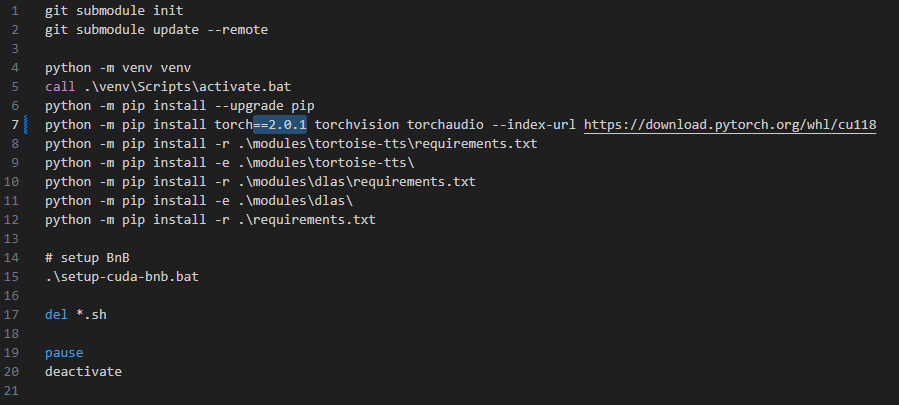
This fix worked for my 1050ti.