WhisperX models (Large issue) #326
Labels
No Label
bug
duplicate
enhancement
help wanted
insufficient info
invalid
news
not a bug
question
wontfix
No Milestone
No project
No Assignees
1 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: mrq/ai-voice-cloning#326
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
So all the WhisperX models work apart from the large model and I get this error when I try transcribe and process a dataset :
Of course it's saying I should select large-v1 or large-v2. However I don't have this option nor do I know what I need to edit to make this option available to me :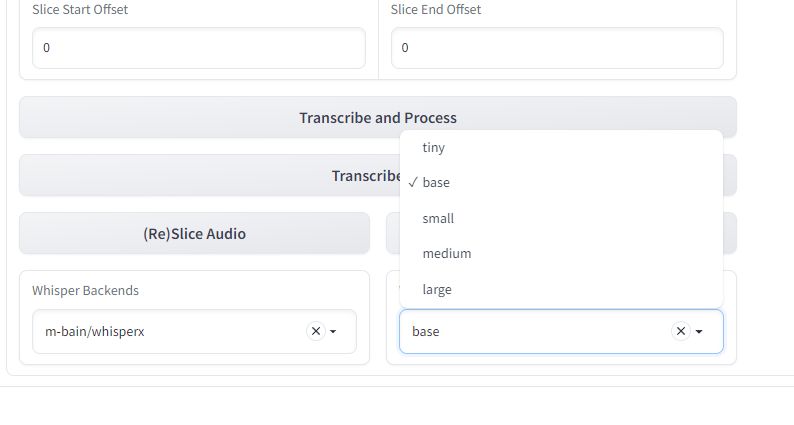
\ai-voice-cloning\venv\lib\site-packages\faster_whisper\utils.py - I edited this file and just added a "large" on line 22 and that seems to have work. Just to check this was the correct thing to do?