Best ways to get rid of static? #352
Labels
No Label
bug
duplicate
enhancement
help wanted
insufficient info
invalid
news
not a bug
question
wontfix
No Milestone
No project
No Assignees
2 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: mrq/ai-voice-cloning#352
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
I've trained a model for 400 epochs and loss graph looked really solid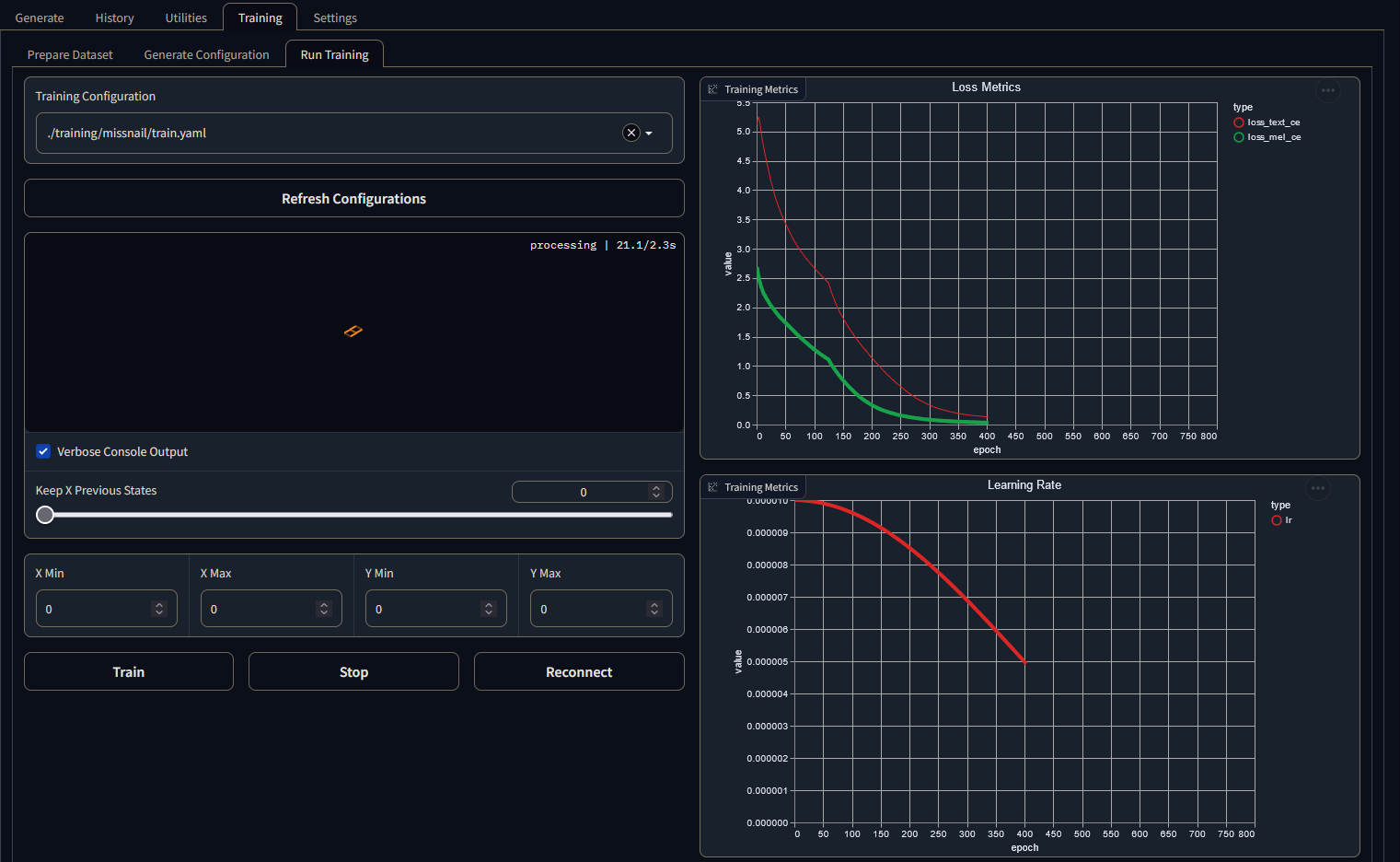 but unfortunately there is lots of static in inference outputs. I've tried a bunch of inference settings (even high quality and standard presets) and can't get rid of static in the output. Only thing I can think to improve is run the training audio sample through Ultimate Vocal Remover and then retrain the model. Any other suggestions?
but unfortunately there is lots of static in inference outputs. I've tried a bunch of inference settings (even high quality and standard presets) and can't get rid of static in the output. Only thing I can think to improve is run the training audio sample through Ultimate Vocal Remover and then retrain the model. Any other suggestions?
Context:
What I am after is a model that can capture porosity/tone/cadence of a voice well. I don't care too much about the quality of the voice (as long as doesn't contain a ton of static and distortion) because I'm going to be taking the output and shoving into RVC to match the voice pitch and quality really nicely. I'm trying to create a chatbot app so inference time is important to me (doesn't need to be realtime but needs to be reasonable.) I was inspired from Jarrod's video here https://www.youtube.com/watch?v=IcpRfHod1ic
Given the graph, loss curve, and LR curve, I think your LR scheduling might have been too lax and ended up frying the finetune from the LR decaying very slowly. The default scheduling should be fine, especially if you're going to train for 400 epochs.
I'd start training from scratch but with the default scheduling.