Resume training with expanded dataset #353
Labels
No Label
bug
duplicate
enhancement
help wanted
insufficient info
invalid
news
not a bug
question
wontfix
No Milestone
No project
No Assignees
2 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: mrq/ai-voice-cloning#353
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Hi mrq, great work here and thank you for replying to the issues opened.
Quick question - I have already completed training on my current dataset. If I want to add more audio files (of the same voice) to this existing dataset, how can I resume training?
I see that you that you have some instructions here on Resuming Training, but I wasn't sure whether this applies to the same dataset or if I can resume training after I've added more audio files to the existing dataset.
Thanks in advance!
The training script should be able to resume training from the last checkpoint without needing to update anything else, even if you modified the dataset.
The "Resume Training" or whatever it was called is for specifying which model weights to start from, which is usually the existing AR model. You can also make use of finetuning existing finetunes (for example, a language finetune being finetuned on a specific voice of that language), which is where the feature comes into play.
You can use the "Resume Training" to start from your previous finetune, the only difference would be a clean set of optimizer states and starting from iteration/epoch 0, but those effectively only govern the LR scheduling.
Thanks for the reply. I have tried to train based on the last saved state path, but am running into an issue where the model stops training after only 10 minutes (from 1005_gpt.pth to 1016_gpt.pth). Would appreciate your advice please.
I've added the new input wav files into ./voices/me2.
Prepare Dataset> I enabled "Skip Already Transcribed" and clicked "Transcribe and Process".
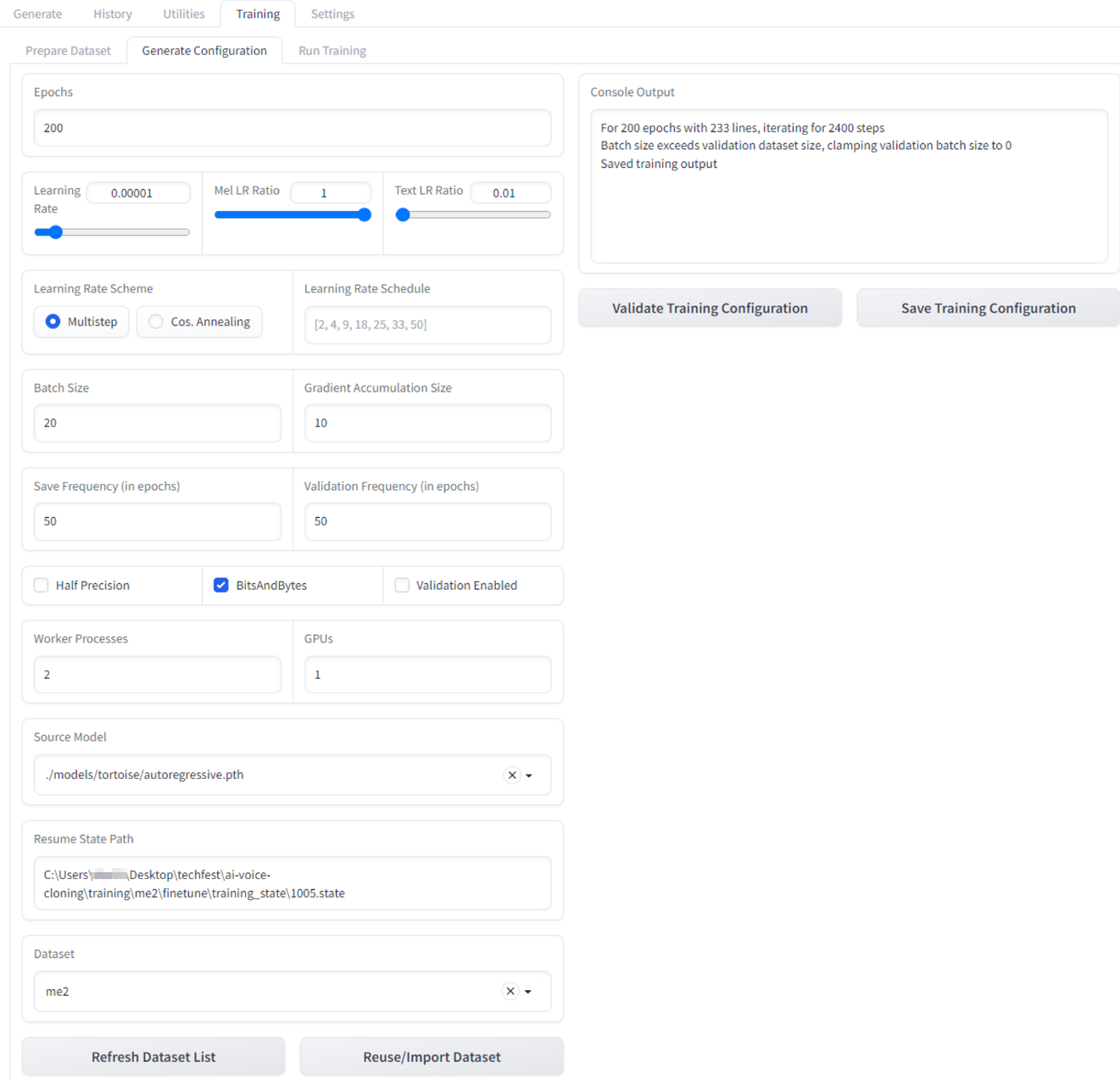
Generate Configuration> I set the same configurations (Epochs: 200, Batch Size: 20, Gradient Accumulation: 10) as before. Resume State Path =
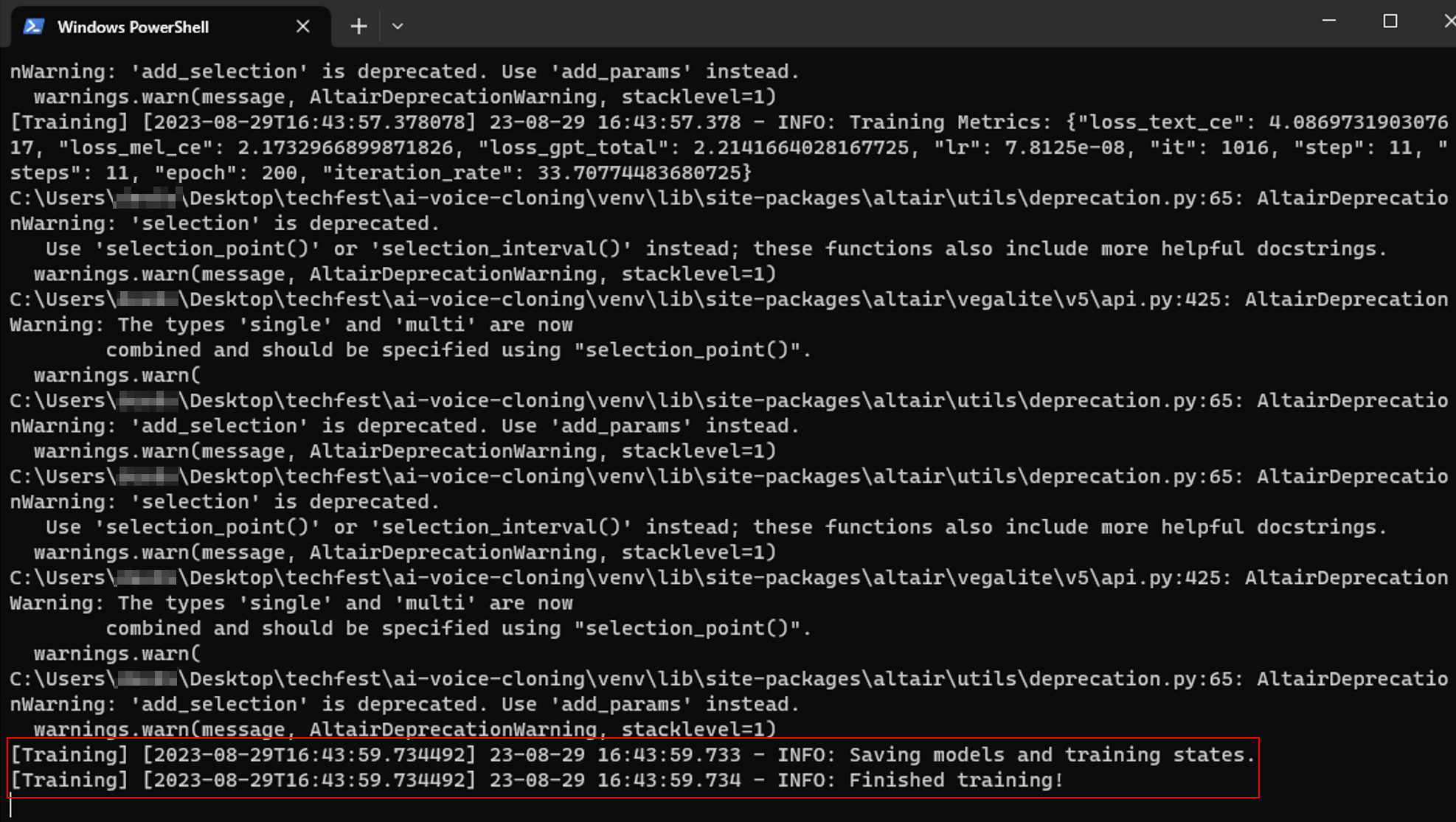
<path>\training\me2\finetune\training_state\1005.stateHowever, in the "Run Training" tab, after I clicked "Train", the model trains for 10 minutes and stops at 1016_gpt.pth, saying that training has completed. I'm not sure why it stops after 10 minutes, and that it only increases from 1005_gpt.pth to 1016_gpt.pth. My original dataset had 100 wav files (took 8h to train the first time), and my dataset now has 233 wav files. Shouldn't this expanded dataset take ~12h to train?
I have checked in ./training/me2 and see that train.txt contains the transcription of all 233 wav files (including the newly added ones).
Am I missing out something in the configurations/settings?
Screenshots for reference: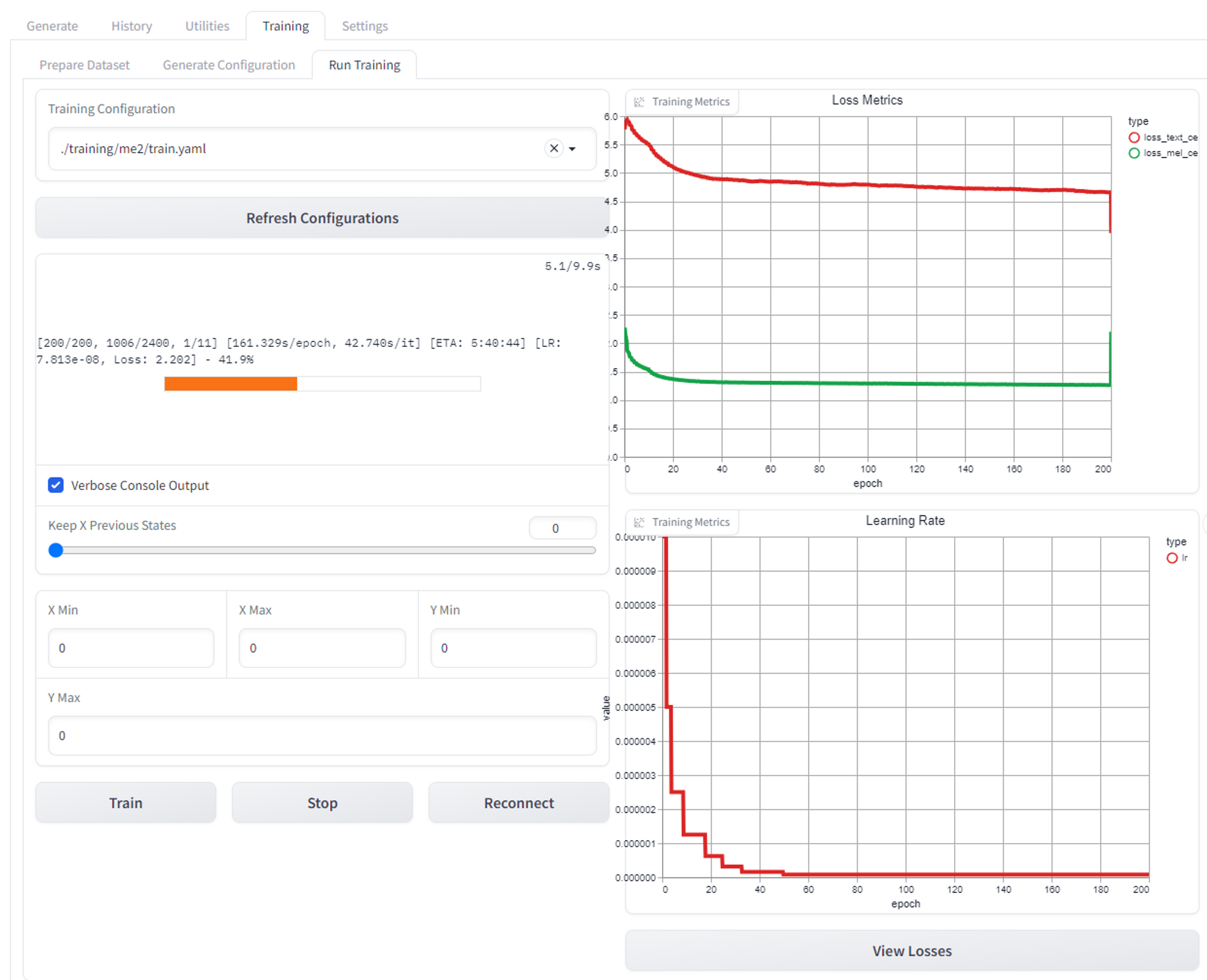
Training tab -
Console log -
Generate Configuration tab -
Oh, I suppose this is a bit of a mismatch between what is considered an "epoch" between my side creating the YAML, and the DLAS training script, which may or may not be also retaining that bit of information in the checkpointed states, although I'm not really too sure how.
A simple fix would be to increase your "epochs count" from 200 to something more, that should fix it.
I see. I've increased the epochs from 200 to 500, and the training seems to work now. Pretty interesting to see the loss metric increase so sharply after adding the new data to the dataset (which I assume is expected behaviour since the model has to undergo more training to learn the new data).
Thank you so much for your quick response, I was honestly mindblown when I saw that you replied so quickly.
I'll close this issue for now, fingers crossed it trains all the way. Will reopen if otherwise.
Thanks and keep up the great work :)
I have finished this round of training for 300 epochs (increased from 200 to 500 epochs in "Generate Configuration"). I decided to increase to 800 epochs so it would train again for another 300 epochs (800 - 500).
Question - Why does loss_mel_ce spike up when I continue training from 500 epochs? I'm not adding any new data into the dataset.
Train logs: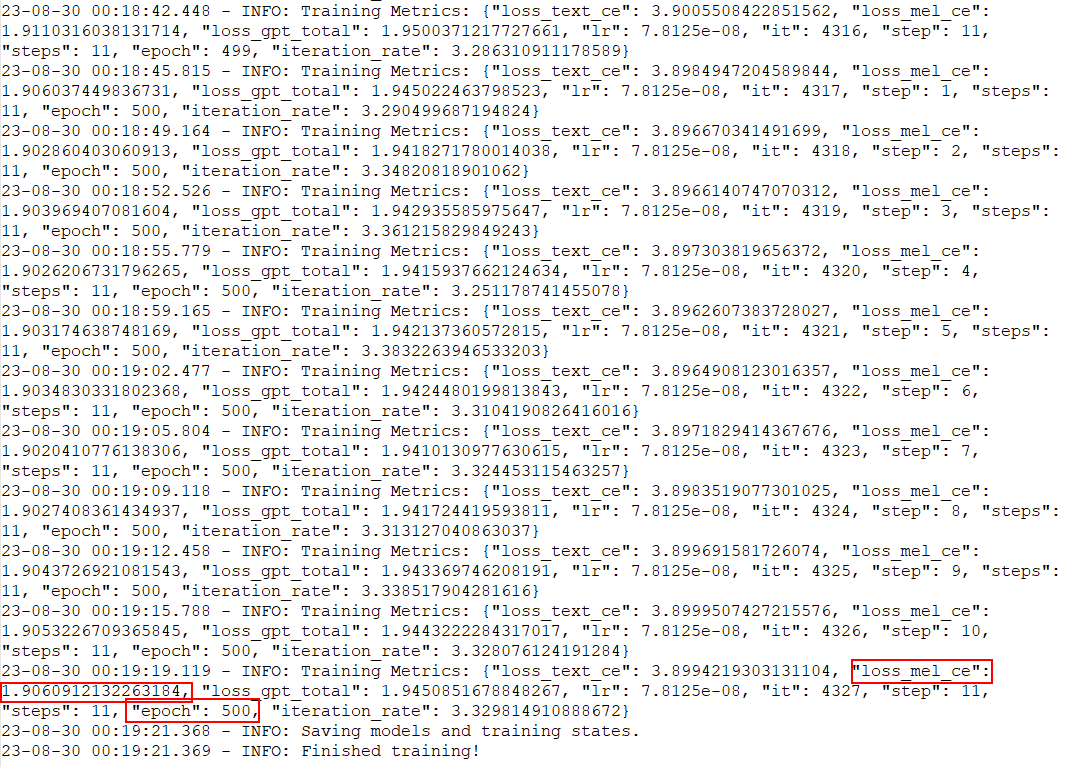
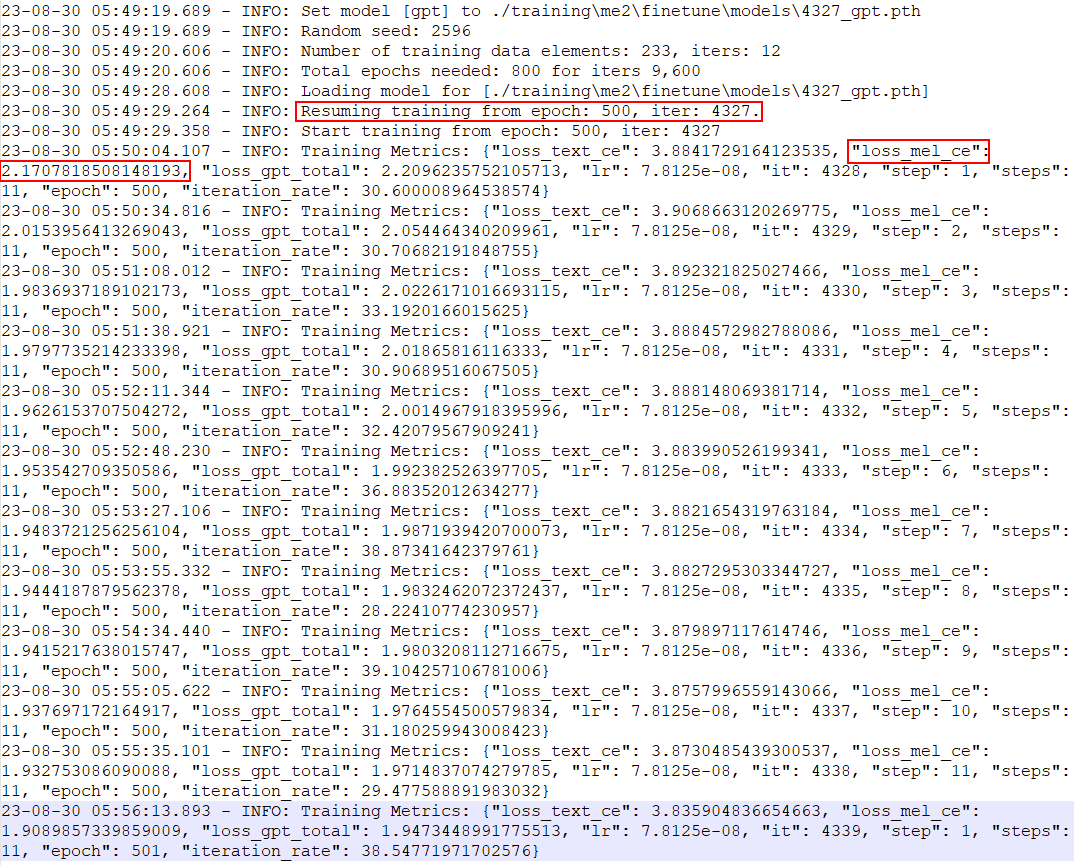
Stopped at 500 epochs, "loss_mel_ce": 1.9060912132263184
Continuing from 500 epochs, "loss_mel_ce": 2.170781850814819
P.S. It looks like loss_mel_ce goes back to 1.90x at epoch = 501 but I'm curious why it spikes when I continue training from epoch = 500.