Update 'Training'
parent
0d8a9fe9a5
commit
2725e40145
37
Training.md
37
Training.md
@ -15,7 +15,7 @@ Before continuing, please be sure you have an adequate GPU. The bare minimum req
|
||||
- Pascal (10-series) and before: a card with at least 16GiB of VRAM.
|
||||
- Turing (20-series) and beyond: a card with at least 6GiB of VRAM.
|
||||
|
||||
Unfortunately, only Turing cards (and beyond) have the necessary dedicated silicon to do integer8 calculations, an optimization leveraged by BitsAndBytes to allow for even the low-end consumer cards to train. However, BitsAndByte's documentation says this restriction is only for inferencing, and instead, the real requirement is Kepler and beyond. Unfortunately, I have no real way to test this, as it seems users with Kepler/Pascal cards are getting esoteric CUDA errors when using BitsAndBytes.
|
||||
Unfortunately, while the official documentation says Kepler-and-beyond cards are able to leverage some of BitsAndBytes' optimizations, in practice (at least on Windows), it seems it's only Turing-and-beyond. Some users have reported issues on Pascal GPUs.
|
||||
|
||||
If you're on Windows and using an installation of this software from before 2023.02.24, and you want to (and can) use BitsAndBytes, please consult https://git.ecker.tech/mrq/ai-voice-cloning/issues/25 for a simple guide to copying the right files.
|
||||
|
||||
@ -23,7 +23,7 @@ If you're on Windows using an installation after 2023.02.24, the setup should ha
|
||||
|
||||
To check if it works, you should see a message saying it is using BitsAndBytes optimizations on training startup.
|
||||
|
||||
### Capabilities
|
||||
### Finetune Capabilities
|
||||
|
||||
Training/finetuning a model offers a lot of improvements over using the base model. This can range from:
|
||||
* better matching to a given voice's traits
|
||||
@ -37,17 +37,17 @@ If any of the above is of interest, then you're on the right track.
|
||||
|
||||
## Prepare Dataset
|
||||
|
||||
This section will aid in preparing the dataset for fine-tuning.
|
||||
This section will aid in preparing the dataset for finetuning.
|
||||
|
||||
Dataset sizes can range from a few sentences, to a large collection of lines. However, do note that smalller dataset sizes require more epochs to finetune against, as there's less iterations invested to train per epoch.
|
||||
Dataset sizes can range from a few sentences, to a large collection of lines. However, do note that training behavior will vary depending on dataset size.
|
||||
|
||||
Simply put your voice sources in its own folder under `./voices/` (as you normally would when using a voice for generaton), specify the language to transcribe to (default: English), then click Prepare.
|
||||
Simply put your voice sources in its own folder under `./voices/` (as you normally would when using a voice for generating), specify the language to transcribe to (default: English), then click Prepare.
|
||||
|
||||
This utility will leverage [openai/whisper](https://github.com/openai/whisper/) to transcribe the audio. Then, it'll slice the audio into pieces that the transcription found fit. Afterwards, it'll output this transcript as an LJSpeech-formatted text file: `train.txt`.
|
||||
|
||||
As whisper uses `fffmpeg` to handle it's audio processing, you must have a copy of `ffmpeg` exposed and accessible through your PATH environment variable. On Linux, this is simply having it installed through your package manager. On Windows, you can just download a copy of `ffmeg.exe` and drop it into the `./bin/` folder.
|
||||
|
||||
Transcription is not perfect, however. Be sure to manually quality check the outputted transcription, and edit any errors it might face. For things like Japanese, it's expected for things that would be spoken katakana to be coerced into kanji. In addition, when generating a finetuned model trained on Japanese:
|
||||
Transcription is not perfect, however. Be sure to manually quality check the outputted transcription, and edit any errors it might face. For things like Japanese, it's expected for things that would be spoken katakana to be coerced into kanji. In addition, when generating a finetuned model trained on Japanese (these may just be problems with my dataset, however):
|
||||
* some kanji might get coerced into the wrong pronunciation.
|
||||
* small kana like the `っ` of `あたしって` gets coerced as the normal kana.
|
||||
* some punctuation like `、` may prematurely terminate a sentence.
|
||||
@ -106,14 +106,11 @@ After preparing your dataset and configuration file, you are ready to train. Sim
|
||||
|
||||
If you check `Verbose Console Output`, *all* output from the training process gets forwarded to the console window on the right until training starts. This output is buffered, up to the `Console Buffer Size` specified (for example, the last eight lines if 8).
|
||||
|
||||
If you bump up the `Keep X Previous States` above 0, it will keep the last X number of saved models and training states, and clean up the rest on training start, and every save. **!**NOTE**!** I did not extensively test this, only on test data, and it did not nuke my saves. I don't expect it to happen, but be wary.
|
||||
If you bump up the `Keep X Previous States` above 0, it will keep the last X number of saved models and training states, and clean up the rest on training start, and every save.
|
||||
|
||||
**!**Linux only**!**: If you're looking to use multiple GPUs, set how many GPUs you have in the `GPUs` field, and it will leverage distrubted training.
|
||||
* **!**NOTE**!**: this is experimental. It seems to train so far, and both my 6800XTs have a load on them, but I'm not too sure of the exact specifics.
|
||||
If everything is done right, you'll see a progress bar and some helpful metrics. Below that, is a graph of the loss rates.
|
||||
|
||||
If everything is done right, you'll see a progress bar and some helpful metrics. Below that, is a graph of the total GPT loss rate.
|
||||
|
||||
After every `print rate` iterations, the loss rate will update and get reported back to you. This will update the graph below with the current loss rate. This is useful to see how "ready" your model/finetune is. The general rule of thumb is the lower, the better. I used to swear by values around `0.15` and `0.1`, but I've had nicer results when it's lower. But be wary, as this *may* be grounds for overfitment, as is the usual problem with training/finetuning.
|
||||
After every `print rate` iterations, the loss rate will update and get reported back to you. This will update the graph below with the current loss rate. This is useful to see how "ready" your model/finetune is. However, there doesn't seem to be a "one-size-fits-all" value for what loss rate you should aim at. I've had some finetunes benefit a ton more from sub 0.01 loss rates, while others absolutely fried after 0.5 (although, it entirely depends on how low of a learning rate you have, rather than haphazardly quick-training it).
|
||||
|
||||
If something goes wrong, please consult the output, as, more than likely, you've ran out of memory.
|
||||
|
||||
@ -121,10 +118,22 @@ After you're done, the process will close itself, and you are now free to use th
|
||||
|
||||
You can then head on over to the `Settings` tab, reload the model listings, and select your newly trained model in the `Autoregressive Model` dropdown.
|
||||
|
||||
### Multi-GPU Training
|
||||
|
||||
**!**NOTE**!**: This is Linux only, only because I don't have a way to test it on Windows, or the care to have the batch script match the shell script.
|
||||
|
||||
If you have multiple GPUs, you can easily leverage them by simply specifying how many GPUs you have in the `Run Training` tab. With it, it'll divide out the workload by splitting the batches to work on among the pool (at least, my understanding).
|
||||
|
||||
However, it seems a little odd. One training test, I had a big discrepancy between VRAM usage at low-ish batch sizes (bs=~128), while astronomically increasing my batch size (bs=256, 512) brought VRAM to parity.
|
||||
|
||||
Do note, you really should try and aim to have identical GPUs (as in, same AIB), as even a difference in coolers will serve as a bottleneck, as evident with my misfortune:
|
||||
|
||||
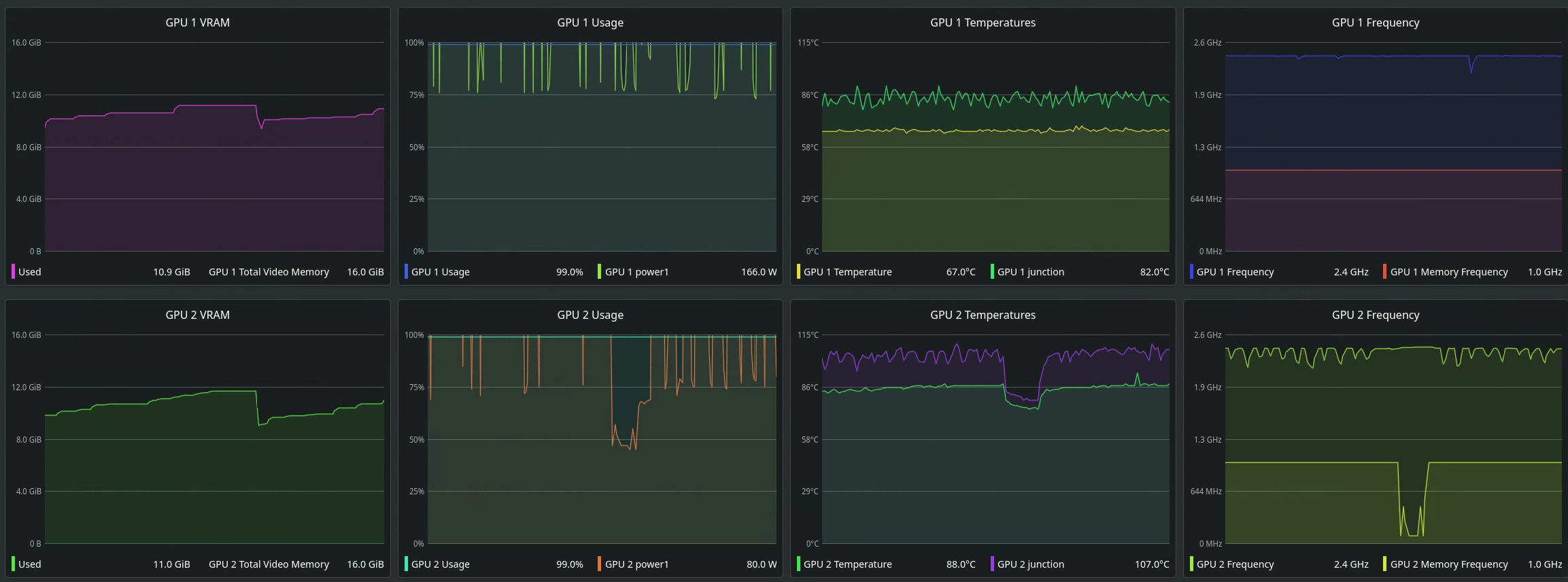
|
||||
|
||||
### Training Output
|
||||
|
||||
Due to the nature of the interfacing with training, some discrepancies may occur:
|
||||
* the UI bases its units in epochs, and converts to the unit the training script bases itself in: iterations. Some slight rounding errors may occur. For example, at the last epoch, it might save one iteration before how many iterations given to train.
|
||||
* the training script calculates what an epoch is slightly different than what the UI calculates an epoch as. This might be due to how it determines what lines in the dataset gets culled out from non-evenly-divisible dataset sizes by batch sizes. For example, it might think a given amount of iterations will fill 99 epochs instead of 100.
|
||||
* because I have to reparse the training output, some statistics may seem a little inconsistent. For example, the ETA is extrapolated by the last delta between iterations. I could do better ways for this (like by delta time between epochs, averaging delta time between iterations and extrapolating from it, etc.).
|
||||
* for long, long generations on a publically-facing Gradio instance (using `share=True`), the UI may disconnect from the program. This can be remedied using the `Reconnect` button, but the UI will appear to update every other iteration. This is because it's still trying to "update" the initial connection, and it'll grab the line of output from stdio, and will alternate between the two sessions.
|
||||
* because I have to reparse the training output, some statistics may seem a little inconsistent. For example, the ETA is extrapolated by the last delta between epochs. I could do better ways for this, but oh well.
|
||||
* for long, long generations on a publicly-facing Gradio instance (using `share=True`), the UI may disconnect from the program. This can be remedied using the `Reconnect` button, but the UI will appear to update every other iteration. This is because it's still trying to "update" the initial connection, and it'll grab the line of output from stdio, and will alternate between the two sessions.
|
||||
Loading…
Reference in New Issue
Block a user