Update 'Training'
parent
7d07ba3e5c
commit
2c82776be7
39
Training.md
39
Training.md
|
|
@ -8,14 +8,14 @@ This tab will contain a collection of sub-tabs pertaining to training.
|
|||
Before continuing, please be sure you have an adequate GPU. The bare minimum requirements depend on your GPU's architecture, VRAM capacity, and OS.
|
||||
|
||||
* Windows + AMD: unfortunately, I cannot leverage DirectML to provide compatibility for training on Windows + AMD systems. If you're insistent on training, please use a Colab notebook.
|
||||
* Linux + AMD: (**!**UNVERIFIED**!**)
|
||||
- a card with at least 16GiB of VRAM (without bitsandbytes)
|
||||
- (theoretically) a card with at least 6GiB of VRAM, with [broncotc/bitsandbytes-rocm](https://github.com/broncotc/bitsandbytes-rocm)
|
||||
* Linux + AMD:
|
||||
- a card with at least 6GiB of VRAM (with `bitsandbytes-rocm`)
|
||||
- a card with at least 12GiB of VRAM (without `bitsandbytes-rocm`)
|
||||
* NVIDIA:
|
||||
- Pascal (10-series) and before: a card with at least 16GiB of VRAM.
|
||||
- Pascal (10-series) and before: a card with at least 12GiB of VRAM.
|
||||
- Turing (20-series) and beyond: a card with at least 6GiB of VRAM.
|
||||
|
||||
Unfortunately, while the official documentation says Kepler-and-beyond cards are able to leverage some of BitsAndBytes' optimizations, in practice (at least on Windows), it seems it's only Turing-and-beyond. Some users have reported issues on Pascal GPUs.
|
||||
Unfortunately, while the official documentation says Kepler-and-beyond cards are able to leverage some of BitsAndBytes' optimizations, in practice (at least on Windows), it seems it's only Turing-and-beyond. Some users have reported issues on Pascal GPUs, while others were able to get training to work with bitsandbytes, albeit with harmed performance.
|
||||
|
||||
If you're on Windows and using an installation of this software from before 2023.02.24, and you want to (and can) use BitsAndBytes, please consult https://git.ecker.tech/mrq/ai-voice-cloning/issues/25 for a simple guide to copying the right files.
|
||||
|
||||
|
|
@ -41,19 +41,17 @@ This section will aid in preparing the dataset for finetuning.
|
|||
|
||||
Dataset sizes can range from a few sentences, to a large collection of lines. However, do note that training behavior will vary depending on dataset size.
|
||||
|
||||
Simply put your voice sources in its own folder under `./voices/` (as you normally would when using a voice for generating), specify the language to transcribe to (default: English), then click Prepare.
|
||||
Simply put your voice sources in its own folder under `./voices/` (as you normally would when using a voice for generating), specify the language to transcribe to (default: English), then click Prepare. Leave the Language field blank to attempt to auto-deduce the language.
|
||||
|
||||
This utility will leverage [openai/whisper](https://github.com/openai/whisper/) to transcribe the audio. Then, it'll slice the audio into pieces that the transcription found fit. Afterwards, it'll output this transcript as an LJSpeech-formatted text file: `train.txt`.
|
||||
This utility will leverage [openai/whisper](https://github.com/openai/whisper/) to transcribe the audio. Then, it'll slice the audio into pieces that the transcription found fit. Afterwards, it'll output this transcript as an LJSpeech-formatted text file: `train.txt`, and that file will also print to the console output on the side.
|
||||
|
||||
As whisper uses `fffmpeg` to handle it's audio processing, you must have a copy of `ffmpeg` exposed and accessible through your PATH environment variable. On Linux, this is simply having it installed through your package manager. On Windows, you can just download a copy of `ffmeg.exe` and drop it into the `./bin/` folder.
|
||||
|
||||
Transcription is not perfect, however. Be sure to manually quality check the outputted transcription, and edit any errors it might face. For things like Japanese, it's expected for things that would be spoken katakana to be coerced into kanji. In addition, when generating a finetuned model trained on Japanese (these may just be problems with my dataset, however):
|
||||
Transcription is not perfect, however. Be sure to manually quality check the outputted transcription, and edit any errors it might face. Empty slices may be produced, and will be culled when detected. For things like Japanese, it's expected for things that would be spoken katakana to be coerced into kanji. In addition, when generating a finetuned model trained on Japanese (these may just be problems with my dataset, however):
|
||||
* some kanji might get coerced into the wrong pronunciation.
|
||||
* small kana like the `っ` of `あたしって` gets coerced as the normal kana.
|
||||
* some punctuation like `、` may prematurely terminate a sentence.
|
||||
|
||||
**!**NOTE**!**: you might get some funky errors; consult this [issue](Issues#user-content-attributeerror-module-ffmpeg-has-no-attribute-input) if you do.
|
||||
|
||||
## Generate Configuration
|
||||
|
||||
This will generate the YAML necessary to feed into training. For documentation's sake, below are details for what each parameter does:
|
||||
|
|
@ -81,23 +79,23 @@ After filling in the values, click `Save Training Configuration`, and it should
|
|||
|
||||
### Suggested Settings
|
||||
|
||||
**!**NOTE**!**: some of my findings are based around training in a multi-GPU environment. I'll need to validate that some of these hold true in a single GPU training environment.
|
||||
|
||||
Getting decent training results is quite the pickle, and it seems my nuggets of wisdom are getting spread over the wiki, so here, I'll (try to) detail my findings with training, now that I'm able to actually test various settings with ease.
|
||||
* your target epoch count has no bearing on how something is trained, as it's just a number telling the trainer how long to train
|
||||
- In other words, there's no (perceptable) difference between training for 25 epochs, then 25 epochs, over training for just 50 epochs.
|
||||
- **!**NOTE**!**: there seems to be some quirk with the learning rate scheduler, where it'll take some time for it to "re-adjust" when resuming, so keep in mind your learning rate might be un-decayed for a few iterations when training-then-resuming.
|
||||
* (assumption) leave the learning rate where it's at, as training with BitsAndBytes or half-precision will yield worse results the higher the learning rate is.
|
||||
- Don't try and be clever and doing what I do with Textual Inversions by training at a high learning rate briefly, then dropping it down to save some epochs worth of training; you'll definitely fry the model.
|
||||
- For smaller datasets, you can crank this up to the maximum (1e-4), as it will be quicker for the learning rate schedule to decay this.
|
||||
* Text CE LR Ratio most definitely should not be touched.
|
||||
- I'm under the impression that it actually wants a high loss ratio to not overfit.
|
||||
* As for a learning rate schedule, I *feel* like very large datasets require tighter scheduling, but the suggested schedule was for a dataset of around either 4k or 7k files, so it should be fine regardless.
|
||||
* Your batch size and gradient accumulation size greatly determine how much VRAM gets consumed. It is a bit tough to nail right, yet easy to fail and get un-optimal training (desu, it should be ratio instead of factor).
|
||||
- The batch size divided by the gradient accumulation size will determine how much VRAM gets used. For example, similar VRAM is consumed if using a ratio of 64:1, 128:2, 256:4, 512:8, 1024:16.
|
||||
- I need to play around with this more, as I feel one set of understanding gets replaced with a different set of understandings when applying them.
|
||||
- The only downside is that increasing your gradient accumulation size means more system RAM is consumed, at least, appears to. Reduce the worker size if needed.
|
||||
- The smaller your print and save frequencies, the more time training will pause to return metrics and dump to disk. I don't think printing very often will harm *too* much, but it pleases my autism to have a tight resolution for my training losses. Naturally, saving often also means more checkpoints on disk.
|
||||
- I haven't thoroughly tested half-precision training, as using it was the means of reducing VRAM consumption before BitsAndBytes was integrated.
|
||||
+ in theory, this should be mutually exclusive with BitsAndBytes, as in, you can only enable one or the other.
|
||||
- If your system says BitsAndBytes is active, you ***should*** use it. At low learning rates, the drawbacks of possible precision errors isn't exacerbated.
|
||||
- The worker size was default to 8 workers. I'm not too sure what increasing this is necessary for (I imagine it was 8 because the original model was trained with 8 GPUs, and it was misnomer-ed as using 8 workers), but leaving this high will definitely creep up on you with increased system RAM usage. 2 is sensible, and I haven't had any performance penalties.
|
||||
|
||||
|
||||
### Resuming Training
|
||||
|
|
@ -117,11 +115,13 @@ I've done this plenty of times and haven't had anything nuked or erased. As a sa
|
|||
|
||||
In the future, I'll adjust the "resume state" to provide a dropdown instead when selecting a dataset, rather than requiring to import and deduce the most recent state, to make things easier.
|
||||
|
||||
**!**NOTE**!**: due to a quirk in the learning rate scheduler, it'll take some time for it to "catch up" to where it should be. Keep this in mind, as your loss rate jump around as the learning rate re-settles and decays.
|
||||
|
||||
### Changing Base Model
|
||||
|
||||
Currently in the web UI, there's no way to specify picking a different model (such as, using a finetune to train from). You must manually edit the `train.yaml` by specifying the path to the model you want to fine tune at line 117.
|
||||
In addition to finetuning the base model, you can specify what model you want to finetune, effectively finetuning finetunes. Theoretically, this is useful for finetuning off of language models to fit a specific voice.
|
||||
|
||||
I have not tested if this is feasible, but I have tested that you can finetune from a model you have already finetuned from. For example, if you were to train a large dataset for a different language (Japanese), but you also want to finetune for a specific voice, you can re-finetune the Japanese model.
|
||||
I have not got a chance to test this, as I mistakenly deleted my Japanese model, and I've been having bad luck getting it re-trained.
|
||||
|
||||
## Run Training
|
||||
|
||||
|
|
@ -139,6 +139,7 @@ If everything is done right, you'll see a progress bar and some helpful metrics.
|
|||
* `iteration throughput rate`: the time it took to process the last iteration
|
||||
* `ETA`: estimated time to completion; will use the epoch throughput rate to estimate
|
||||
* `Loss`: the last reported loss value
|
||||
* `LR`: the last reported learning rate
|
||||
* `Next milestone in:` reports the next "milestone" for training, and how many more iterations left to reach it.
|
||||
- **!**NOTE**!**: this is pretty inaccurate, as it uses the "instantaneous" rate of change
|
||||
|
||||
|
|
@ -156,12 +157,6 @@ You can then head on over to the `Settings` tab, reload the model listings, and
|
|||
|
||||
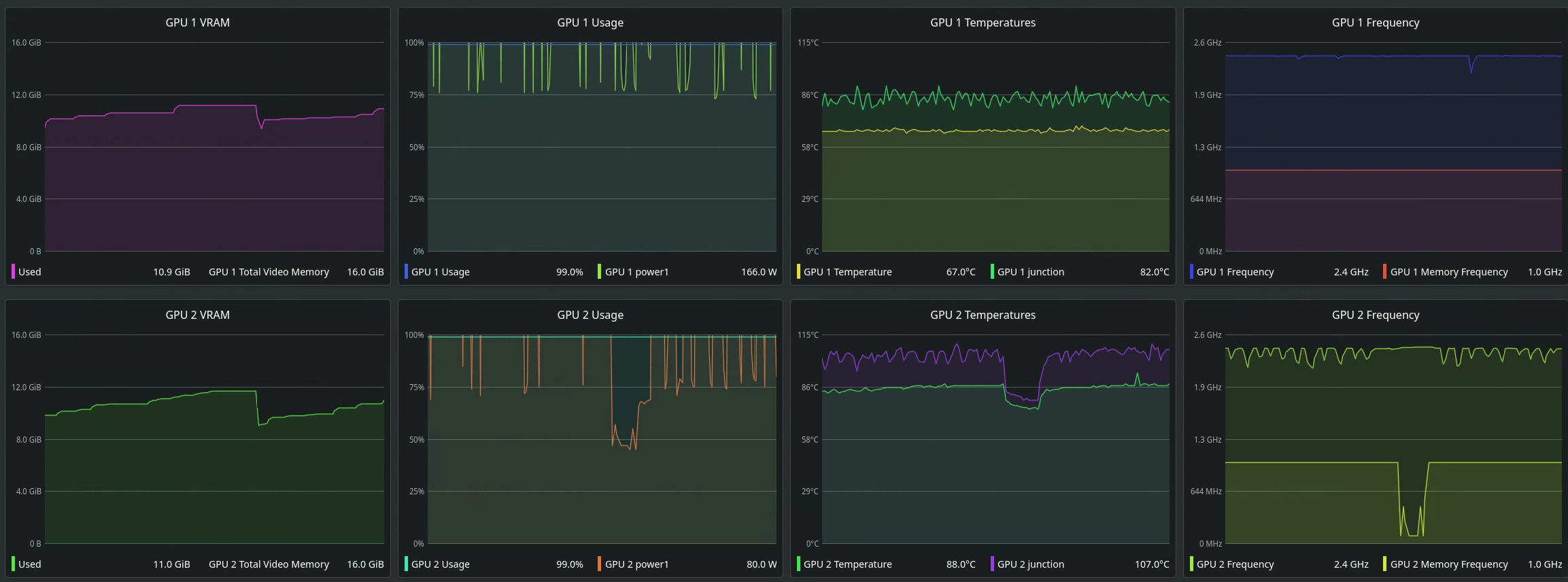
If you have multiple GPUs, you can easily leverage them by simply specifying how many GPUs you have in the `Run Training` tab. With it, it'll divide out the workload by splitting the batches to work on among the pool (at least, my understanding).
|
||||
|
||||
However, it seems a little odd. One training test, I had a big discrepancy between VRAM usage at low-ish batch sizes (bs=~128), while astronomically increasing my batch size (bs=256, 512) brought VRAM to parity.
|
||||
|
||||
Do note, you really should try and aim to have identical GPUs (as in, same AIB), as even a difference in coolers will serve as a bottleneck, as evident with my misfortune:
|
||||
|
||||
|
||||
|
||||
### Training Output
|
||||
|
||||
Due to the nature of the interfacing with training, some discrepancies may occur:
|
||||
|
|
|
|||
Loading…
Reference in New Issue
Block a user