| ESRGAN | ||
| modules | ||
| scripts | ||
| .gitignore | ||
| artists.csv | ||
| README.md | ||
| requirements_versions.txt | ||
| requirements.txt | ||
| screenshot.png | ||
| script.js | ||
| style.css | ||
| webui.bat | ||
| webui.py | ||
{kind=link}
Stable Diffusion web UI
A browser interface based on Gradio library for Stable Diffusion.
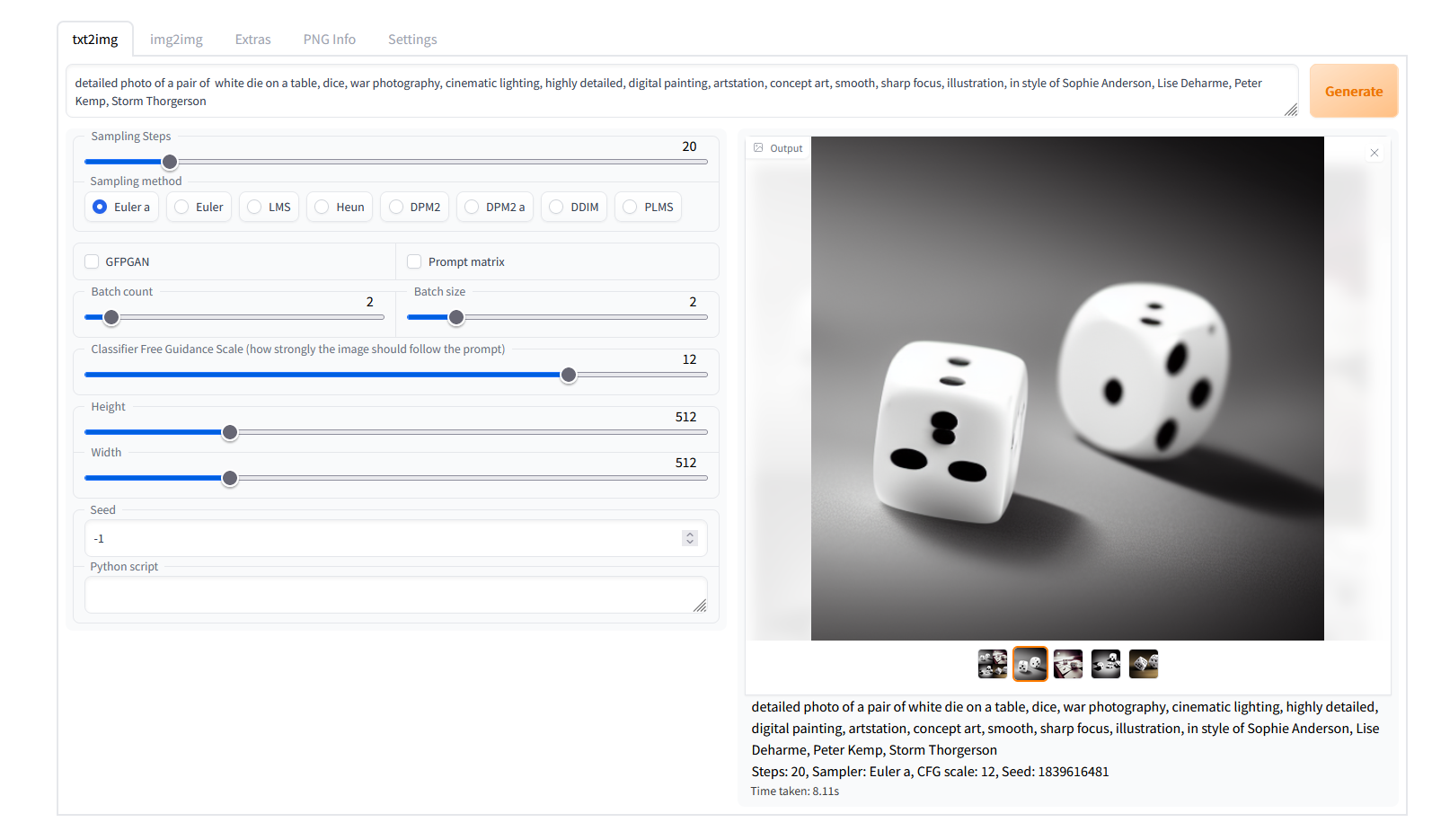
Feature showcase
Detailed feature showcase with images, art by Greg Rutkowski
- Original txt2img and img2img modes
- One click install and run script (but you still must install python, git and CUDA)
- Outpainting
- Inpainting
- Prompt matrix
- Stable Diffusion upscale
- Attention
- Loopback
- X/Y plot
- Textual Inversion
- Extras tab with:
- GFPGAN, neural network that fixes faces
- RealESRGAN, neural network upscaler
- ESRGAN, neural network with a lot of third party models
- Resizing aspect ratio options
- Sampling method selection
- Interrupt processing at any time
- 4GB videocard support
- Correct seeds for batches
- Prompt length validation
- Generation parameters added as text to PNG
- Tab to view an existing picture's generation parameters
- Settings page
- Running custom code from UI
- Mouseover hints fo most UI elements
- Possible to change defaults/mix/max/step values for UI elements via text config
- Random artist button
- Tiling support: UI checkbox to create images that can be tiled like textures
- Progress bar and live image generation preview
Installing and running
You need python and git installed to run this, and an NVidia videocard.
I tested the installation to work Windows with Python 3.8.10, and with Python 3.10.6. You may be able to have success with different versions.
You need model.ckpt, Stable Diffusion model checkpoint, a big file containing the neural network weights. You
can obtain it from the following places:
- official download
- file storage
- magnet:?xt=urn:btih:3a4a612d75ed088ea542acac52f9f45987488d1c&dn=sd-v1-4.ckpt&tr=udp%3a%2f%2ftracker.openbittorrent.com%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337
You optionally can use GPFGAN to improve faces, then you'll need to download the model from here.
To use ESRGAN models, put them into ESRGAN directory in the same location as webui.py. A file will be loaded as model if it has .pth extension. Grab models from the Model Database.
Automatic installation/launch
- install Python 3.10.6 and check "Add Python to PATH" during installation. You must install this exact version.
- install git
- install CUDA 11.3
- place
model.ckptinto webui directory, next towebui.bat. - (optional) place
GFPGANv1.3.pthinto webui directory, next towebui.bat. - run
webui.batfrom Windows Explorer.
Troublehooting:
- According to reports, intallation currently does not work in a directory with spaces in filenames.
- if your version of Python is not in PATH (or if another version is), edit
webui.bat, change the lineset PYTHON=pythonto say the full path to your python executable:set PYTHON=B:\soft\Python310\python.exe. You can do this for python, but not for git. - if you get out of memory errors and your videocard has low amount of VRAM (4GB), edit
webui.bat, change line 5 to fromset COMMANDLINE_ARGS=toset COMMANDLINE_ARGS=--medvram(see below for other possible options) - installer creates python virtual environment, so none of installed modules will affect your system installation of python if you had one prior to installing this.
- to prevent the creation of virtual environment and use your system python, edit
webui.batreplacingset VENV_DIR=venvwithset VENV_DIR=. - webui.bat installs requirements from files
requirements_versions.txt, which lists versions for modules specifically compatible with Python 3.10.6. If you choose to install for a different version of python, editingwebui.batto haveset REQS_FILE=requirements.txtinstead ofset REQS_FILE=requirements_versions.txtmay help (but I still reccomend you to just use the recommended version of python). - if you feel you broke something and want to reinstall from scratch, delete directories:
venv,repositories.
Google collab
If you don't want or can't run locally, here is google collab that allows you to run the webui:
https://colab.research.google.com/drive/1Iy-xW9t1-OQWhb0hNxueGij8phCyluOh
What options to use for low VRAM videocards?
- If you have 4GB VRAM and want to make 512x512 (or maybe up to 640x640) images, use
--medvram. - If you have 4GB VRAM and want to make 512x512 images, but you get an out of memory error with
--medvram, use--medvram --opt-split-attentioninstead. - If you have 4GB VRAM and want to make 512x512 images, and you still get an out of memory error, use
--lowvram --always-batch-cond-uncond --opt-split-attentioninstead. - If you have 4GB VRAM and want to make images larger than you can with
--medvram, use--lowvram --opt-split-attention. - If you have more VRAM and want to make larger images than you can usually make, use
--medvram --opt-split-attention. You can use--lowvramalso but the effect will likely be barely noticeable. - Otherwise, do not use any of those.
Extra: if you get a green screen instead of generated pictures, you have a card that doesn't support half
precision floating point numbers. You must use --precision full --no-half in addition to other flags,
and the model will take much more space in VRAM.
Running online
Use --share option to run online. You will get a xxx.app.gradio link. This is the intended way to use the
program in collabs.
Use --listen to make the server listen to network connections. This will allow computers on local newtork
to access the UI, and if you configure port forwarding, also computers on the internet.
Textual Inversion
To make use of pretrained embeddings, create embeddings directory (in the same palce as webui.py)
and put your embeddings into it. They must be .pt files, each with only one trained embedding,
and the filename (without .pt) will be the term you'd use in prompt to get that embedding.
As an example, I trained one for about 5000 steps: https://files.catbox.moe/e2ui6r.pt; it does not produce very good results, but it does work. Download and rename it to Usada Pekora.pt, and put it into embeddings dir and use Usada Pekora in prompt.
How to change UI defaults?
After running once, a ui-config.json file appears in webui directory:
{
"txt2img/Sampling Steps/value": 20,
"txt2img/Sampling Steps/minimum": 1,
"txt2img/Sampling Steps/maximum": 150,
"txt2img/Sampling Steps/step": 1,
"txt2img/Batch count/value": 1,
"txt2img/Batch count/minimum": 1,
"txt2img/Batch count/maximum": 32,
"txt2img/Batch count/step": 1,
"txt2img/Batch size/value": 1,
"txt2img/Batch size/minimum": 1,
Edit values to your liking and the next time you launch the program they will be applied.
Manual instructions
Alternatively, if you don't want to run webui.bat, here are instructions for installing everything by hand:
:: crate a directory somewhere for stable diffusion and open cmd in it;
:: make sure you are in the right directory; the command must output the directory you chose
echo %cd%
:: install torch with CUDA support. See https://pytorch.org/get-started/locally/ for more instructions if this fails.
pip install torch --extra-index-url https://download.pytorch.org/whl/cu113
:: check if torch supports GPU; this must output "True". You need CUDA 11. installed for this. You might be able to use
:: a different version, but this is what I tested.
python -c "import torch; print(torch.cuda.is_available())"
:: clone Stable Diffusion repositories
git clone https://github.com/CompVis/stable-diffusion.git
git clone https://github.com/CompVis/taming-transformers
:: install requirements of Stable Diffusion
pip install transformers==4.19.2 diffusers invisible-watermark
:: install k-diffusion
pip install git+https://github.com/crowsonkb/k-diffusion.git
:: (optional) install GFPGAN to fix faces
pip install git+https://github.com/TencentARC/GFPGAN.git
:: go into stable diffusion's repo directory
cd stable-diffusion
:: clone web ui
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
:: install requirements of web ui
pip install -r stable-diffusion-webui/requirements.txt
:: update numpy to latest version
pip install -U numpy
:: (outside of command line) put stable diffusion model into models/ldm/stable-diffusion-v1/model.ckpt; you'll have
:: to create one missing directory;
:: the command below must output something like: 1 File(s) 4,265,380,512 bytes
dir models\ldm\stable-diffusion-v1\model.ckpt
:: (outside of command line) put the GFPGAN model into same directory as webui script
:: the command below must output something like: 1 File(s) 348,632,874 bytes
dir stable-diffusion-webui\GFPGANv1.3.pth
After that the installation is finished.
Run the command to start web ui:
python stable-diffusion-webui/webui.py
If you have a 4GB video card, run the command with either --lowvram or --medvram argument:
python stable-diffusion-webui/webui.py --medvram
After a while, you will get a message like this:
Running on local URL: http://127.0.0.1:7860/
Open the URL in browser, and you are good to go.
Credits
- Stable Diffusion - https://github.com/CompVis/stable-diffusion, https://github.com/CompVis/taming-transformers
- k-diffusion - https://github.com/crowsonkb/k-diffusion.git
- GFPGAN - https://github.com/TencentARC/GFPGAN.git
- ESRGAN - https://github.com/xinntao/ESRGAN
- Ideas for optimizations and some code (from users) - https://github.com/basujindal/stable-diffusion
- Idea for SD upscale - https://github.com/jquesnelle/txt2imghd
- Initial Gradio script - posted on 4chan by an Anonymous user. Thank you Anonymous user.
- (You)