Did something break after update? #35
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Updated with git pull and something seems to be broken
After
37d25573ac, running start.bat just gets stuck atInitializating voice-fixerIs there a way to trigger multiple GPUs if you have them? Currently it just uses one.
Well, it's missing the
./results/folder, which I suppose I forgot to have created if not available outside of a generation call. (Should be) remedied in commit261beb8c91.Haven't had any issues in testing. Either:
update.batI have it printing any errors thrown during initialization (despite it should just ignore voicefixer and disable it), since I don't have any other way to debug it.
Not elegantly. There's some "things" you can expose to the GPT2 autoregressive model to act in parallel with a list of devices, but I haven't bothered with it.
./results/folder and voicefixer issues seems to be related are are solved, thank you.However there seems to be a new problem, and I'm not sure what's going on here with connections?
It showed up after
Generation took 1007.0080227851868 seconds, saved to..Re: GPU, it's using the less powerful one that I have which is taking a lot of time to run this and heats up bad, meanwhile the more powerful one is sitting idle, unfortunately.
Those have usually happened for me. They're very innocuous so I haven't bothered with resolving it.
Ah, that can be remedied in a few ways:
pythoncall in the start script:start.bat:set CUDA_VISIBLE_DEVICES=1,0start.sh:export CUDA_VISIBLE_DEVICES=1,0cuda:1will pass it to Torch and get the 1th-indexed (second) device.However, for figuring out which device, I might just add a script that's simply the following to get your device IDs:
When I get some free time, I'll try and add it in.
Added argument
device-override/settingDevice Overridein commit7a4460ddf0. Pass a string returned from runninglist_devices.py, for example, passcuda:1into this box. I have not extensively tested this, as I do not have a multi-NVIDIA GPU setup, just used it to test forcing CPU-mode.Not sure if I'm doing it right,
start.batfile and adding cuda devices ❌cuda:1❌Just want it to use all GPUs available to make things fast.
Strange, wonder what's bugging it out there. It's an (unrelated) error related to the incrementing filename thing that I tried to fix a few hours ago. I don't think you'd have to clear out your
./results/folder, since it should work without needing to.If you can, edit
webui.pywith the following, then report back with what it prints:so the block looks like: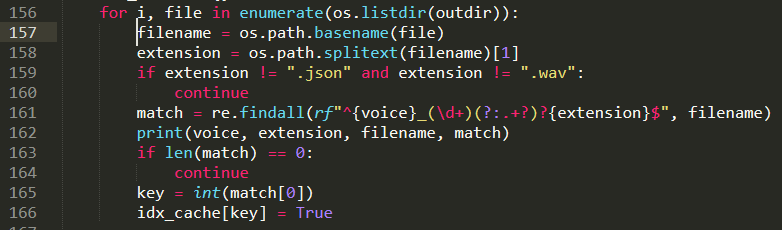
It'll debug print some info that might help me figure out why it breaks, and at worst it'll just skip it.
On the other hand, you should only need to do either 2 (the
set CUDA_VISIBLE_DEVICESthing) or 3, as 2 will also mess with the index order for 3, theoretically. And you only really need to do one or the other anyhow.Did a normal run with latest pull,
start.batis runOutput is still generated
2. When 'High Quality' is selectedSomething went wrong'CUDA out of memory. Tried to allocate ... reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF'
No outputTurns out it was because the voices/XXX/20.wav file was 2 mins long and it didn't like it
Sounds like you closed the process while it was downloading the model for voicefixer. In that case, delete the
%USERPROFILE%\.cache\folder.