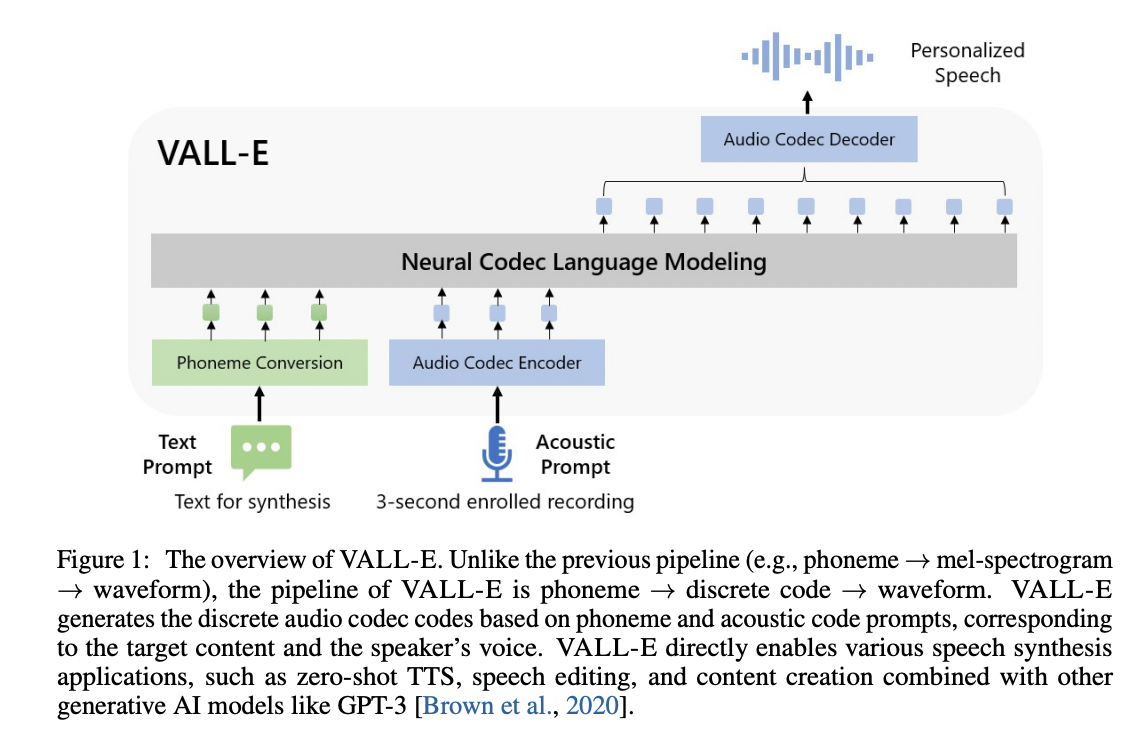
# VALL'E
An unofficial PyTorch implementation of [VALL-E](https://valle-demo.github.io/), utilizing the [EnCodec](https://github.com/facebookresearch/encodec) encoder/decoder.
> **Note** Development on this is very sporadic. Gomen.
## Requirements
* [`espeak-ng`](https://github.com/espeak-ng/espeak-ng/):
- For phonemizing text, this repo requires `espeak`/`espeak-ng` installed.
- Linux users can consult their package managers on installing `espeak`/`espeak-ng`.
- Windows users are required to install [`espeak-ng`](https://github.com/espeak-ng/espeak-ng/releases/tag/1.51#Assets).
+ additionally, you may be required to set the `PHONEMIZER_ESPEAK_LIBRARY` environment variable to specify the path to `libespeak-ng.dll`.
## Install
Simply run `pip install git+https://git.ecker.tech/mrq/vall-e` or `pip install git+https://github.com/e-c-k-e-r/vall-e`.
I've tested this repo under Python versions `3.10.9` and `3.11.3`.
## Try Me
To quickly try it out, you can run `python -m vall_e.models.ar_nar yaml="./data/config.yaml"`
Each model file has a barebones trainer and inference routine.
## Pre-Trained Model
My pre-trained weights can be acquired from [here](https://huggingface.co/ecker/vall-e).
A script to setup a proper environment and download the weights can be invoked with `./scripts/setup.sh`
## Train
Training is very dependent on:
* the quality of your dataset.
* how much data you have.
* the bandwidth you quantized your audio to.
* the underlying model architecture used.
### Pre-Processed Dataset
A "libre" dataset can be found [here](https://huggingface.co/ecker/vall-e) under `data.tar.gz`.
A script to setup a proper environment and train can be invoked with `./scripts/setup-training.sh`
### Leverage Your Own Dataset
> **Note** Preparing a dataset is a bit messy.
0. Set up a `venv` with `https://github.com/m-bain/whisperX/`.
+ At the moment only WhisperX is utilized. Using other variants like `faster-whisper` is an exercise left to the user at the moment.
+ It's recommended to use a dedicated virtualenv specifically for transcribing, as WhisperX will break a few dependencies.
+ The following command should work:
```
python3 -m venv venv-whisper
source ./venv-whisper/bin/activate
pip3 install torch torchvision torchaudio
pip3 install git+https://github.com/m-bain/whisperX/
```
1. Populate your source voices under `./voices/{group name}/{speaker name}/`.
2. Run `python3 ./scripts/transcribe_dataset.py`. This will generate a transcription with timestamps for your dataset.
+ If you're interested in using a different model, edit the script's `model_name` and `batch_size` variables.
3. Run `python3 ./scripts/process_dataset.py`. This will phonemize the transcriptions and quantize the audio.
4. Copy `./data/config.yaml` to `./training/config.yaml`. Customize the training configuration and populate your `dataset.training` list with the values stored under `./training/dataset_list.json`.
+ Refer to `./vall_e/config.py` for additional configuration details.
### Dataset Formats
Two dataset formats are supported:
* the standard way:
- for Encodec/Vocos audio backends, data is stored under `./training/data/{group}/{speaker}/{id}.phn.txt` and `./training/data/{group}/{speaker}/{id}.qnt.pt`
- for Descript-Audio-Codec audio backend, data is stored under `./training/data/{group}/{speaker}/{id}.json` and `./training/data/{group}/{speaker}/{id}.dac`
* using an HDF5 dataset:
- you can convert from the standard way with the following command: `python3 -m vall_e.data yaml="./training/config.yaml"`
- this will shove everything into a single HDF5 file and store some metadata alongside (for now, the symbol map generated, and text/audio lengths)
- be sure to also define `use_hdf5` in your config YAML.
### Initializing Training
For single GPUs, simply running `python3 -m vall_e.train yaml="./training/config.yaml`.
For multiple GPUs, or exotic distributed training:
* with `deepspeed` backends, simply running `deepspeed --module vall_e.train yaml="./training/config.yaml"` should handle the gory details.
* with `local` backends, simply run `torchrun --nnodes=1 --nproc-per-node={NUMOFGPUS} -m vall_e.train yaml="./training/config.yaml"`
You can enter `save` to save the state at any time, or `quit` to save and quit training.
The `lr` will also let you adjust the learning rate on the fly. For example: `lr 1.0e-3` will set the learning rate to `0.001`.
### Plotting Metrics
Included is a helper script to parse the training metrics. Simply invoke it with, for example: `python3 -m vall_e.plot yaml="./training/config.yaml"`
You can specify what X and Y labels you want to plot against by passing `--xs tokens_processed --ys loss stats.acc`
### Notices
#### Training Under Windows
As training under `deepspeed` and Windows is not (easily) supported, under your `config.yaml`, simply change `trainer.backend` to `local` to use the local training backend.
Keep in mind that creature comforts like distributed training or `float16` training cannot be verified as working at the moment with the local trainer.
#### Training Caveats
Unfortunately, efforts to train a *good* foundational model seems entirely predicated on a good dataset. My dataset might be too fouled with:
* too short utterances: trying to extrapolate longer contexts seems to utterly fall apart from just the `text` being too long.
* too tightly trimmed utterances: there being little to no space at the start and end might harm associating `` and `` tokens with empty utterances.
* a poorly mapped phoneme mapping: I naively crafted my own phoneme mapping, where a HuggingFace tokenizer might supply a better token mapping.
#### Backend Architectures
As the core of VALL-E makes use of a language model, various LLM architectures can be supported and slotted in. Currently supported:
* `transformer`: a basic attention-based transformer implementation, with attention heads + feed forwards.
* `retnet`: using [TorchScale's RetNet](https://github.com/microsoft/torchscale/blob/main/torchscale/architecture/retnet.py) implementation, a retention-based approach can be used instead.
- Its implementation for MoE can also be utilized.
* `retnet-hf`: using [syncdoth/RetNet/](https://github.com/syncdoth/RetNet/) with a HuggingFace-compatible RetNet model
- inferencing cost is about 0.5x, and MoE is not implemented.
* `llama`: using HF transformer's LLaMa implementation for its attention-based transformer, boasting RoPE and other improvements.
* `mixtral`: using HF transformer's Mixtral implementation for its attention-based transformer, also utilizing its MoE implementation.
* `bitnet`: using [this](https://github.com/kyegomez/BitNet/) implementation of BitNet's transformer.
- Setting `bitsandbytes.bitnet=True` will make use of BitNet's linear implementation.
If you're training a true foundational model, consider which backend you want to use the most. `llama` backends can benefit from all the additional tech with it, while exotic ones like `retnet` or `bitnet` can't at the moment, but may leverage experimental gains.
## Export
To export the models, run: `python -m vall_e.export yaml=./training/config.yaml`.
This will export the latest checkpoints, for example, under `./training/ckpt/ar+nar-retnet-8/fp32.pth`, to be loaded on any system with PyTorch, and will include additional metadata, such as the symmap used, and training stats.
## Synthesis
To synthesize speech, invoke either (if exported the models): `python -m vall_e --model-ckpt ./training/ckpt/ar+nar-retnet-8/fp32.pth` or `python -m vall_e yaml=`
Some additional flags you can pass are:
* `--language`: specifies the language for phonemizing the text, and helps guide inferencing when the model is trained against that language.
* `--max-ar-steps`: maximum steps for inferencing through the AR model. Each second is 75 steps.
* `--device`: device to use (default: `cuda`, examples: `cuda:0`, `cuda:1`, `cpu`)
* `--ar-temp`: sampling temperature to use for the AR pass. During experimentation, `0.95` provides the most consistent output, but values close to it works fine.
* `--nar-temp`: sampling temperature to use for the NAR pass. During experimentation, `0.2` provides clean output, but values upward of `0.6` seems fine too.
And some experimental sampling flags you can use too (your mileage will ***definitely*** vary):
* `--max-ar-context`: Number of `resp` tokens to keep in the context when inferencing. This is akin to "rolling context" in an effort to try and curb any context limitations, but currently does not seem fruitful.
* `--min-ar-temp` / `--min-nar-temp`: triggers the dynamic temperature pathway, adjusting the temperature based on the confidence of the best token. Acceptable values are between `[0.0, (n)ar-temp)`.
+ This simply uplifts the [original implementation](https://github.com/kalomaze/koboldcpp/blob/dynamic-temp/llama.cpp#L5132) to perform it.
+ **!**NOTE**!**: This does not seem to resolve any issues with setting too high/low of a temperature. The right values are yet to be found.
* `--top-p`: limits the sampling pool to top sum of values that equal `P`% probability in the probability distribution.
* `--top-k`: limits the sampling pool to the top `K` values in the probability distribution.
* `--repetition-penalty`: modifies the probability of tokens if they have appeared before. In the context of audio generation, this is a very iffy parameter to use.
* `--repetition-penalty-decay`: modifies the above factor applied to scale based on how far away it is in the past sequence.
* `--length-penalty`: (AR only) modifies the probability of the stop token based on the current sequence length. This is ***very*** finnicky due to the AR already being well correlated with the length.
* `--beam-width`: (AR only) specifies the number of branches to search through for beam sampling.
+ This is a very naive implementation that's effectively just greedy sampling across `B` spaces.
* `--mirostat-tau`: (AR only) the "surprise value" when performing mirostat sampling.
+ This simply uplifts the [original implementation](https://github.com/basusourya/mirostat/blob/master/mirostat.py) to perform it.
+ **!**NOTE**!**: This is incompatible with beam search sampling (for the meantime at least).
* `--mirostat-eta`: (AR only) the "learning rate" during mirostat sampling applied to the maximum surprise.
## To-Do
* train and release a ***good*** model.
* clean up the README, and document, document, document onto the wiki.
* extend to ~~multiple languages ([VALL-E X](https://arxiv.org/abs/2303.03926)) and~~ addditional tasks ([SpeechX](https://arxiv.org/abs/2308.06873)).
- training additional tasks needs the SpeechX implementation to be reworked.
* improve throughput (despite peaking at 120it/s):
- properly utilize RetNet's recurrent forward / chunkwise forward passes (does not seem to want to work no matter how the model is trained).
- utilize an approach similar to [FasterDecoding/Medusa](https://github.com/FasterDecoding/Medusa/) with additional heads for decoding N+1, N+2, N+3 AR tokens
+ this requires a properly trained AR, however.
* work around issues with extending context past what's trained (despite RetNet's retention allegedly being able to defeat this):
- "sliding" AR input, such as have the context a fixed length.
+ the model may need to be trained for this with a fancy positional embedding injected OR already trained with a sliding context window in mind. Naively sliding the context window while making use of the RetNet implementation's positional embedding doesn't seem fruitful.
## Notices and Citations
Unless otherwise credited/noted in this README or within the designated Python file, this repository is [licensed](LICENSE) under AGPLv3.
- [EnCodec](https://github.com/facebookresearch/encodec) is licensed under CC-BY-NC 4.0. If you use the code to generate audio quantization or perform decoding, it is important to adhere to the terms of their license.
- This implementation was originally based on [enhuiz/vall-e](https://github.com/enhuiz/vall-e), but has been heavily, heavily modified over time.
```bibtex
@article{wang2023neural,
title={Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers},
author={Wang, Chengyi and Chen, Sanyuan and Wu, Yu and Zhang, Ziqiang and Zhou, Long and Liu, Shujie and Chen, Zhuo and Liu, Yanqing and Wang, Huaming and Li, Jinyu and others},
journal={arXiv preprint arXiv:2301.02111},
year={2023}
}
```
```bibtex
@article{defossez2022highfi,
title={High Fidelity Neural Audio Compression},
author={Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi},
journal={arXiv preprint arXiv:2210.13438},
year={2022}
}
```