An unofficial PyTorch implementation of VALL-E
| config | ||
| data/test | ||
| scripts | ||
| vall_e | ||
| .gitignore | ||
| .gitmodules | ||
| LICENSE | ||
| README.md | ||
| requirements.txt | ||
| setup.py | ||
| vall-e.png | ||
{kind=link}
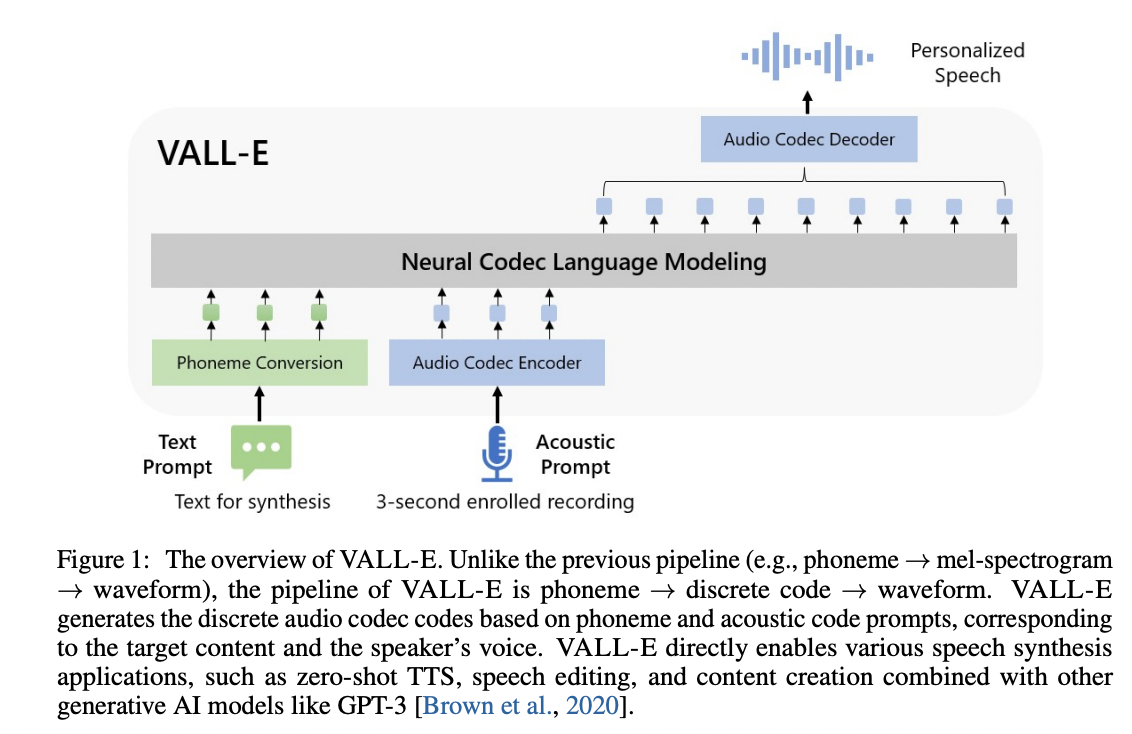
VALL-E
An unofficial PyTorch implementation of VALL-E, based on the EnCodec tokenizer.

Install
pip install git+https://github.com/enhuiz/vall-e
Note that the code is only tested under Python 3.10.7.
Usage
-
Put your data into a folder, e.g.
data/your_data. Audio files should be named with the suffix.wavand text files with.normalized.txt. -
Quantize the data:
python -m vall_e.emb.qnt data/your_data
- Generate phonemes based on the text:
python -m vall_e.emb.g2p data/your_data
-
Customize your configuration by creating
config/your_data/ar.ymlandconfig/your_data/nar.yml. Refer to the example configs inconfig/testandvall_e/config.pyfor details. You may choose different model presets, checkvall_e/vall_e/__init__.py. -
Train the AR or NAR model using the following scripts:
python -m vall_e.train yaml=config/your_data/ar_or_nar.yml
TODO
- AR model for the first quantizer
- Audio decoding from tokens
- NAR model for the rest quantizers
- Trainers for both models
- Implement AdaLN for NAR model.
- Sample-wise quantization level sampling for NAR training.
- Pre-trained checkpoint and demos on LibriTTS
Citations
@article{wang2023neural,
title={Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers},
author={Wang, Chengyi and Chen, Sanyuan and Wu, Yu and Zhang, Ziqiang and Zhou, Long and Liu, Shujie and Chen, Zhuo and Liu, Yanqing and Wang, Huaming and Li, Jinyu and others},
journal={arXiv preprint arXiv:2301.02111},
year={2023}
}
@article{defossez2022highfi,
title={High Fidelity Neural Audio Compression},
author={Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi},
journal={arXiv preprint arXiv:2210.13438},
year={2022}
}