| data | ||
| scripts | ||
| vall_e | ||
| .gitignore | ||
| LICENSE | ||
| README.md | ||
| setup.py | ||
| vall-e.png | ||
{kind=link}
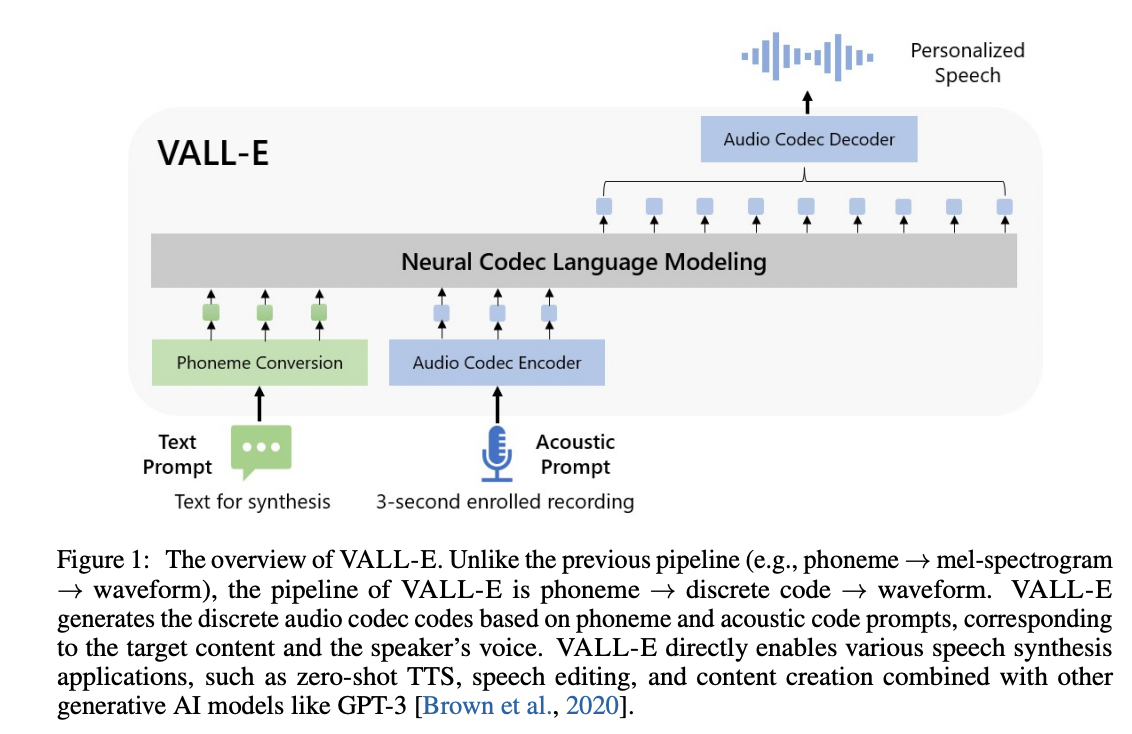
VALL'E
An unofficial PyTorch implementation of VALL-E, based on the EnCodec tokenizer.
Requirements
-
- DeepSpeed training is Linux only. Installation under Windows should ignore trying to install DeepSpeed.
- If your config YAML has the training backend set to
deepspeed, you will need to have a GPU that DeepSpeed has developed and tested against, as well as a CUDA or ROCm compiler pre-installed to install this package.
-
- For phonemizing text, this repo requires
espeak/espeak-nginstalled. - Linux users can consult their package managers on installing
espeak/espeak-ng. - Windows users are required to install
espeak-ng.- additionally, you may be require dto set the
PHONEMIZER_ESPEAK_LIBRARYenvironment variable to specify the path tolibespeak-ng.dll.
- additionally, you may be require dto set the
- For phonemizing text, this repo requires
Install
Simply run pip install git+https://git.ecker.tech/mrq/vall-e.
I've tested this repo under Python versions 3.10.9 and 3.11.3.
Try Me
To quickly try it out, you can choose between the following modes:
- AR only:
python -m vall_e.models.ar yaml="./data/config.yaml" - NAR only:
python -m vall_e.models.nar yaml="./data/config.yaml" - AR+NAR:
python -m vall_e.models.base yaml="./data/config.yaml"
Each model file has a barebones trainer and inference routine.
Pre-Trained Model
My pre-trained weights can be acquired from here.
For example:
git lfs clone --exclude "*.h5" https://huggingface.co/ecker/vall-e ./data/ # remove the '--exclude "*.h5"' if you wish to also download the libre dataset.
python -m vall_e "The birch canoe slid on the smooth planks." "./path/to/an/utterance.wav" --out-path="./output.wav" yaml="./data/config.yaml"
Train
Training is very dependent on:
- the quality of your dataset.
- how much data you have.
- the bandwidth you quantized your audio to.
Pre-Processed Dataset
A "libre" dataset can be found here. Simply place it in the same folder as your config.yaml, and ensure its dataset.use_hdf5 is set to True.
Leverage Your Own Dataset
Note It is highly recommended to utilize mrq/ai-voice-cloning with
--tts-backend="vall-e"to handle transcription and dataset preparations.
-
Put your data into a folder, e.g.
./data/custom. Audio files should be named with the suffix.wavand text files with.txt. -
Quantize the data:
python -m vall_e.emb.qnt ./data/custom -
Generate phonemes based on the text:
python -m vall_e.emb.g2p ./data/custom -
Customize your configuration and define the dataset by modifying
./data/config.yaml. Refer to./vall_e/config.pyfor details. If you want to choose between different model presets, check./vall_e/models/__init__.py.
If you're interested in creating an HDF5 copy of your dataset, simply invoke: python -m vall_e.data --action='hdf5' yaml='./data/config.yaml'
- Train the AR and NAR models using the following scripts:
python -m vall_e.train yaml=./data/config.yaml
You may quit your training any time by just entering quit in your CLI. The latest checkpoint will be automatically saved.
Dataset Formats
Two dataset formats are supported:
- the standard way:
- data is stored under
${speaker}/${id}.phn.txtand${speaker}/${id}.qnt.pt
- data is stored under
- using an HDF5 dataset:
- you can convert from the standard way with the following command:
python3 -m vall_e.data yaml="./path/to/your/config.yaml" - this will shove everything into a single HDF5 file and store some metadata alongside (for now, the symbol map generated, and text/audio lengths)
- be sure to also define
use_hdf5in your config YAML.
- you can convert from the standard way with the following command:
Plotting Metrics
Included is a helper script to parse the training metrics. Simply invoke it with, for example: python3 -m vall_e.plot yaml="./training/valle/config.yaml"
You can specify what X and Y labels you want to plot against by passing --xs tokens_processed --ys loss stats.acc
Notices
Modifying prom_levels, resp_levels, Or tasks For A Model
If you're wanting to increase the prom_levels for a given model, or increase the tasks levels a model accepts, you will need to export your weights and set train.load_state_dict to True in your configuration YAML.
Training Under Windows
As training under deepspeed is not supported, under your config.yaml, simply change trainer.backend to local to use the local training backend.
Keep in mind that creature comforts like distributed training cannot be verified as working at the moment.
Training on Low-VRAM Cards
During experimentation, I've found I can comfortably train on a 4070Ti (12GiB VRAM) with trainer.deepspeed.compression_training enabled with both the AR and NAR at a batch size of 16.
VRAM use is also predicated on your dataset; a mix of large and small utterances will cause VRAM usage to spike and can trigger OOM conditions during the backwards pass if you are not careful.
Additionally, under Windows, I managed to finetune the AR on my 2060 (6GiB VRAM) with a batch size of 8 (although, with the card as a secondary GPU).
If you need to, you are free to train only one model at a time. Just remove the definition for one model in your config.yaml's models._model list.
Export
Both trained models can be exported, but is only required if loading them on systems without DeepSpeed for inferencing (Windows systems). To export the models, run: python -m vall_e.export yaml=./data/config.yaml.
This will export the latest checkpoints, for example, under ./data/ckpt/ar-retnet-2/fp32.pth and ./data/ckpt/nar-retnet-2/fp32.pth, to be loaded on any system with PyTorch.
Synthesis
To synthesize speech, invoke either (if exported the models): python -m vall_e <text> <ref_path> <out_path> --ar-ckpt ./models/ar.pt --nar-ckpt ./models/nar.pt or python -m vall_e <text> <ref_path> <out_path> yaml=<yaml_path>
Some additional flags you can pass are:
--max-ar-steps: maximum steps for inferencing through the AR model. Each second is 75 steps.--ar-temp: sampling temperature to use for the AR pass. During experimentation,0.95provides the most consistent output.--nar-temp: sampling temperature to use for the NAR pass. During experimentation,0.2provides the most clean output.--device: device to use (default:cuda, examples:cuda:0,cuda:1,cpu)
To-Do
- reduce load time for creating / preparing dataloaders (hint: remove use of
Path.globandPath.rglob). - train and release a good model.
- extend to multiple languages (VALL-E X) and
extend totrain SpeechX features.
Notice
- EnCodec is licensed under CC-BY-NC 4.0. If you use the code to generate audio quantization or perform decoding, it is important to adhere to the terms of their license.
Unless otherwise credited/noted, this repository is licensed under AGPLv3.
Citations
@article{wang2023neural,
title={Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers},
author={Wang, Chengyi and Chen, Sanyuan and Wu, Yu and Zhang, Ziqiang and Zhou, Long and Liu, Shujie and Chen, Zhuo and Liu, Yanqing and Wang, Huaming and Li, Jinyu and others},
journal={arXiv preprint arXiv:2301.02111},
year={2023}
}
@article{defossez2022highfi,
title={High Fidelity Neural Audio Compression},
author={Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi},
journal={arXiv preprint arXiv:2210.13438},
year={2022}
}