| data | ||
| scripts | ||
| vall_e | ||
| .gitignore | ||
| LICENSE | ||
| README.md | ||
| setup.py | ||
| vall-e.png | ||
{kind=link}
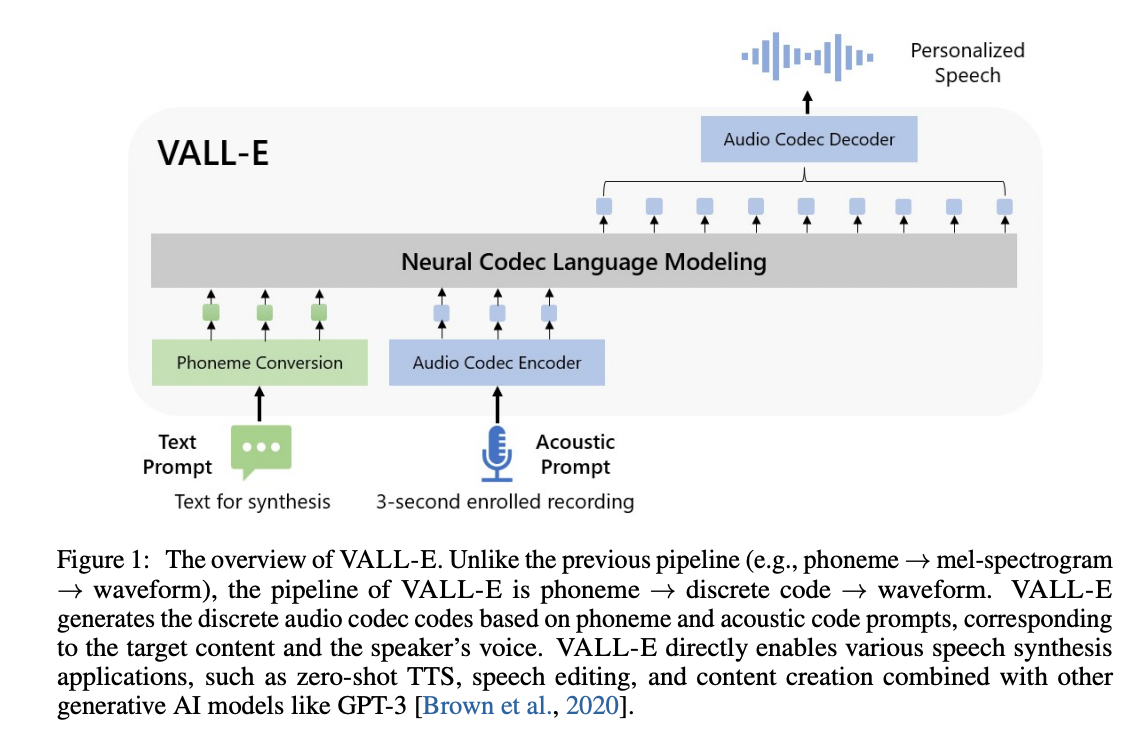
VALL'E
An unofficial PyTorch implementation of VALL-E, utilizing the EnCodec encoder/decoder.
Requirements
Besides a working PyTorch environment, the only hard requirement is espeak-ng for phonemizing text:
- Linux users can consult their package managers on installing
espeak/espeak-ng. - Windows users are required to install
espeak-ng.- additionally, you may be required to set the
PHONEMIZER_ESPEAK_LIBRARYenvironment variable to specify the path tolibespeak-ng.dll.
- additionally, you may be required to set the
- In the future, an internal homebrew to replace this would be fantastic.
Install
Simply run pip install git+https://git.ecker.tech/mrq/vall-e or pip install git+https://github.com/e-c-k-e-r/vall-e.
I've tested this repo under Python versions 3.10.9, 3.11.3, and 3.12.3.
Pre-Trained Model
Note
Pre-Trained weights aren't up to par as a pure zero-shot model at the moment, but are fine for finetuning / LoRAs.
My pre-trained weights can be acquired from here.
A script to setup a proper environment and download the weights can be invoked with ./scripts/setup.sh. This will automatically create a venv, and download the ar+nar-llama-8 weights and config file to the right place.
Train
Training is very dependent on:
- the quality of your dataset.
- how much data you have.
- the bandwidth you quantized your audio to.
- the underlying model architecture used.
Try Me
To quickly test if a configuration works, you can run python -m vall_e.models.ar_nar --yaml="./data/config.yaml"; a small trainer will overfit a provided utterance.
Leverage Your Own Dataset
If you already have a dataset you want, for example, your own large corpus or for finetuning, you can use your own dataset instead.
- Set up a
venvwithhttps://github.com/m-bain/whisperX/.
- At the moment only WhisperX is utilized. Using other variants like
faster-whisperis an exercise left to the user at the moment. - It's recommended to use a dedicated virtualenv specifically for transcribing, as WhisperX will break a few dependencies.
- The following command should work:
python3 -m venv venv-whisper
source ./venv-whisper/bin/activate
pip3 install torch torchvision torchaudio
pip3 install git+https://github.com/m-bain/whisperX/
-
Populate your source voices under
./voices/{group name}/{speaker name}/. -
Run
python3 -m vall_e.emb.transcribe. This will generate a transcription with timestamps for your dataset.
- If you're interested in using a different model, edit the script's
model_nameandbatch_sizevariables.
- Run
python3 -m vall_e.emb.process. This will phonemize the transcriptions and quantize the audio.
- If you're using a Descript-Audio-Codec based model, ensure to set the sample rate and audio backend accordingly.
- Copy
./data/config.yamlto./training/config.yaml. Customize the training configuration and populate yourdataset.traininglist with the values stored under./training/dataset/list.json.
- Refer to
./vall_e/config.pyfor additional configuration details.
Dataset Formats
Two dataset formats are supported:
- the standard way:
- data is stored under
./training/data/{group}/{speaker}/{id}.{enc|dac}as a NumPy file, whereencis for the EnCodec/Vocos backend, anddacfor the Descript-Audio-Codec backend. - it is highly recommended to generate metadata to speed up dataset pre-load with
python3 -m vall_e.data --yaml="./training/config.yaml" --action=metadata
- data is stored under
- using an HDF5 dataset:
- you can convert from the standard way with the following command:
python3 -m vall_e.data --yaml="./training/config.yaml"(metadata for dataset pre-load is generated alongside HDF5 creation) - this will shove everything into a single HDF5 file and store some metadata alongside (for now, the symbol map generated, and text/audio lengths)
- be sure to also define
use_hdf5in your config YAML.
- you can convert from the standard way with the following command:
Training
For single GPUs, simply running python3 -m vall_e.train --yaml="./training/config.yaml.
For multiple GPUs, or exotic distributed training:
- with
deepspeedbackends, simply runningdeepspeed --module vall_e.train --yaml="./training/config.yaml"should handle the gory details. - with
localbackends, simply runtorchrun --nnodes=1 --nproc-per-node={NUMOFGPUS} -m vall_e.train --yaml="./training/config.yaml"
You can enter save to save the state at any time, or quit to save and quit training.
The lr will also let you adjust the learning rate on the fly. For example: lr 1.0e-3 will set the learning rate to 0.001.
Finetuning
Finetuning can be done by training the full model, or using a LoRA.
Finetuning the full model is done the same way as training a model, but be sure to have the weights in the correct spot, as if you're loading them for inferencing.
For training a LoRA, add the following block to your config.yaml:
loras:
- name : "arbitrary name" # whatever you want
rank: 128 # dimensionality of the LoRA
alpha: 128 # scaling factor of the LoRA
training: True
And that's it. Training of the LoRA is done with the same command. Depending on the rank and alpha specified, the loss may be higher than it should, as the LoRA weights are initialized to appropriately random values. I found rank and alpha of 128 works fine.
To export your LoRA weights, run python3 -m vall_e.export --lora --yaml="./training/config.yaml". You should be able to have the LoRA weights loaded from a training checkpoint automagically for inferencing, but export them just to be safe.
Plotting Metrics
Included is a helper script to parse the training metrics. Simply invoke it with, for example: python3 -m vall_e.plot --yaml="./training/config.yaml"
You can specify what X and Y labels you want to plot against by passing --xs tokens_processed --ys loss stats.acc
Notices
Training Under Windows
As training under deepspeed and Windows is not (easily) supported, under your config.yaml, simply change trainer.backend to local to use the local training backend.
Creature comforts like float16, amp, and multi-GPU training should work under the local backend, but extensive testing still needs to be done to ensure it all functions.
Backend Architectures
As the core of VALL-E makes use of a language model, various LLM architectures can be supported and slotted in. Currently supported LLM architectures:
llama: using HF transformer's LLaMa implementation for its attention-based transformer, boasting RoPE and other improvements.- I aim to utilize this for the foundational model, as I get to leverage a bunch of things tailored for LLaMA (and converting to them is rather easy).
mixtral: using HF transformer's Mixtral implementation for its attention-based transformer, also utilizing its MoE implementation.bitnet: using this implementation of BitNet's transformer.- Setting
cfg.optimizers.bitnet=Truewill make use of BitNet's linear implementation.
- Setting
transformer: a basic attention-based transformer implementation, with attention heads + feed forwards.retnet: using TorchScale's RetNet implementation, a retention-based approach can be used instead.- Its implementation for MoE can also be utilized.
retnet-hf: using syncdoth/RetNet with a HuggingFace-compatible RetNet model- has an inference penality, and MoE is not implemented.
mamba: using state-spaces/mamba (needs to mature)- really hard to have a unified AR and NAR model
- inference penalty makes it a really hard sell, despite the loss already being a low 3 after a short amount of samples processed
For audio backends:
encodec: a tried-and-tested EnCodec to encode/decode audio.vocos: a higher quality EnCodec decoder.- encoding audio will use the
encodecbackend automagically, as there's no EnCodec encoder undervocos
- encoding audio will use the
descript-audio-codec: boasts better compression and quality, but has issues with model convergence.- models at 24KHz + 8kbps will NOT converge in any manner.
- models at 44KHz + 8kbps seems harder to model its "language", and the NAR side of the model suffers greatly.
llama-based models also support different attention backends:
torch.nn.functional.scaled_dot_product_attention-based attention:math: torch's SDPA'smathkernelmem_efficient: torch's SDPA's memory efficient (xformersadjacent) kernelcudnn: torch's SDPA'scudnnkernelflash: torch's SDPA's flash attention kernel
- internal implementations of external attention backends:
xformers: facebookresearch/xformers's memory efficient attentionflash_attn: uses the availableflash_attnpackage (includingflash_attn==1.0.9through a funny wrapper)flash_attn_v100: uses ZRayZzz/flash-attention-v100's Flash Attention for Volta (but doesn't work currently)fused_attn: uses an implementation usingtriton(tested on my 7900XTX and V100s), but seems to introduce errors when used to train after a while
transformersLlama*Attention implementations:eager: defaultLlamaAttentionsdpa: integratedLlamaSdpaAttentionattention modelflash_attention_2: integratedLlamaFlashAttetion2attention model
auto: determine the best fit from the above
The wide support for various backends is solely while I try and figure out which is the "best" for a core foundation model.
ROCm Flash Attention
ROCm/flash-attention currently does not support Navi3 cards (gfx11xx), so first-class support for Flash Attention is a bit of a mess on Navi3. Using the howiejay/navi_support branch can get inference support, but not training support (due to some error being thrown during the backwards pass) by:
- edit
/opt/rocm/include/hip/amd_detail/amd_hip_bf16.h:
#if defined(__HIPCC_RTC__)
#define __HOST_DEVICE__ __device__ static
#else
#include <climits>
#define __HOST_DEVICE__ __host__ __device__ static inline
#endif
- install with
pip install -U git+https://github.com/ROCm/flash-attention@howiejay/navi_support --no-build-isolation
Export
To export the models, run: python -m vall_e.export --yaml=./training/config.yaml.
This will export the latest checkpoints, for example, under ./training/ckpt/ar+nar-retnet-8/fp32.pth, to be loaded on any system with PyTorch, and will include additional metadata, such as the symmap used, and training stats.
Desite being called fp32.pth, you can export it to a different precision type with --dtype=float16|bfloat16|float32.
You can also export to safetensors with --format=sft, and fp32.sft will be exported instead.
Synthesis
To synthesize speech: python -m vall_e <text> <ref_path> <out_path> --yaml=<yaml_path>
Some additional flags you can pass are:
--language: specifies the language for phonemizing the text, and helps guide inferencing when the model is trained against that language.--task: task to perform. Defaults totts, but acceptssttfor transcriptions.--max-ar-steps: maximum steps for inferencing through the AR model. Each second is 75 steps.--device: device to use (default:cuda, examples:cuda:0,cuda:1,cpu)--ar-temp: sampling temperature to use for the AR pass. During experimentation,0.95provides the most consistent output, but values close to it works fine.--nar-temp: sampling temperature to use for the NAR pass. During experimentation, the lower value, the better. Set to0to enable greedy sampling.
And some experimental sampling flags you can use too (your mileage will definitely vary, but most of these are bandaids for a bad AR):
--min-ar-temp: triggers the dynamic temperature pathway, adjusting the temperature based on the confidence of the best token. Acceptable values are between[0.0, (n)ar-temp).- This simply uplifts the original implementation to perform it.
- !NOTE!: This does not seem to resolve any issues with setting too high/low of a temperature. The right values are yet to be found.
--top-p: limits the sampling pool to top sum of values that equalP% probability in the probability distribution.--top-k: limits the sampling pool to the topKvalues in the probability distribution.--repetition-penalty: modifies the probability of tokens if they have appeared before. In the context of audio generation, this is a very iffy parameter to use.--repetition-penalty-decay: modifies the above factor applied to scale based on how far away it is in the past sequence.--length-penalty: (AR only) modifies the probability of the stop token based on the current sequence length. This is very finnicky due to the AR already being well correlated with the length.--beam-width: (AR only) specifies the number of branches to search through for beam sampling.- This is a very naive implementation that's effectively just greedy sampling across
Bspaces.
- This is a very naive implementation that's effectively just greedy sampling across
--mirostat-tau: (AR only) the "surprise value" when performing mirostat sampling.- This simply uplifts the original implementation to perform it.
- !NOTE!: This is incompatible with beam search sampling (for the meantime at least).
--mirostat-eta: (AR only) the "learning rate" during mirostat sampling applied to the maximum surprise.--dry-multiplier: (AR only) performs DRY sampling, the scalar factor.--dry-base: (AR only) for DRY sampling, the base of the exponent factor.--dry-allowed-length: (AR only) for DRY sampling, the window to perform DRY sampling within.
Speech-to-Text
The ar+nar-tts+stt-llama-8 model has received additional training for a speech-to-text task against EnCodec-encoded audio.
Currently, the model only transcribes back into the IPA phonemes it was trained against, as an additional model or external program is required to translate the IPA phonemes back into text.
- this does make a model that can phonemize text, and unphonemize text, more desirable in the future to replace espeak (having an additional task to handle this requires additional embeddings, output heads, and possible harm to the model as actual text is not a modality the model is trained on).
Web UI
A Gradio-based web UI is accessible by running python3 -m vall_e.webui. You can, optionally, pass:
--yaml=./path/to/your/config.yaml: will load the targeted YAML--listen 0.0.0.0:7860: will set the web UI to listen to all IPs at port 7860. Replace the IP and Port to your preference.
Inference
Synthesizing speech is simple:
Input Prompt: The guiding text prompt. Each new line will be it's own generated audio to be stitched together at the end.Audio Input: The reference audio for the synthesis. Under Gradio, you can trim your clip accordingly, but leaving it as-is works fine.- A properly trained model can inference without a prompt to generate a random voice (without even needing to generate a random prompt itself).
Output: The resultant audio.Inference: Button to start generating the audio.Basic Settings: Basic sampler settings for most uses.Sampler Settings: Advanced sampler settings that are common for most text LLMs, but needs experimentation.
All the additional knobs have a description that can be correlated to the above CLI flags.
Speech-To-Text phoneme transcriptions for models that support it can be done using the Speech-to-Text tab.
Settings
So far, this only allows you to load a different model without needing to restart. The previous model should seamlessly unload, and the new one will load in place.
To-Do
- train and release a serviceable model for finetuning against.
- LoRA tests shows it's already very capable, although there's room for higher quality (possibly in better NAR training).
- train and release a good zero-shot model.
this should, hopefully, just simply requires another epoch or two forar+nar-llama-8, as the foundation seems rather robust now.- this might need a better training paradigm with providing similar enough input prompts to a given output response.
- well-integrated training through the Web UI (without the kludge from ai-voice-cloning)
explore alternative setups, like a NAR-only model- the current experiment of an AR length-predictor + NAR for the rest seems to fall apart...
explore better sampling techniques- the AR doesn't need exotic sampling techniques, as they're bandaids for a bad AR.
- the NAR benefits from greedy sampling, and anything else just harms output quality.
- clean up the README, and document, document, document onto the wiki.
- extend to multiple languages (VALL-E X).
- extend the reference model to include at least one other model
- extend to addditional tasks (SpeechX).
stt(Speech-to-Text) seems to be working fine for the most part.- other tasks seem to require a ton of VRAM......
- extend using VALL-E 2's features (grouped code modeling + repetition aware sampling)
- desu these don't seem to be worthwhile improvements, as inferencing is already rather fast, and RAS is just a fancy sampler.
- audio streaming
- this technically can work without any additional architecture changes, just clever tricks with sampling-then-decoding-to-audio.
- something similar to HiFiGAN (or the one for TorToiSe) trained on the last hidden states of the AR might also enable an alternate way for streaming.
- replace the phonemizer with something that doesn't depend on espeak
- espeak is nice, but I can only really put my whole trust with phonemizing English.
- a small model trained to handle converting text to phonemes might work, but has it's own problems (another model to carry around, as accurate as the dataset it was trained against, requires training for each language... etc).
Caveats
Despite how lightweight it is in comparison to other TTS's I've meddled with, there are still some caveats, be it with the implementation or model weights:
- the audio embeddings have some quirks to having the AR's RVQ level 0 separate from the NAR's RVQ level 0 (sharing them caused some problems in testing)
- the trainer / dataloader assumes there are zero variations between a speaker's utterances, and thus it can extract the basics of a speaker's features rather than deeper features (like prosidy, tone, etc.) when performing inferences.
- however, trying to work around this would require training under
tts-c(VALL-E continuous) mode or modifying an input prompt enough to where its quantized representation differs enough from the output response the prompt derives from.
- however, trying to work around this would require training under
- the trainer's default RVQ level distribution prioritizes lower RVQ levels over higher RVQ levels, as the lower levels contribute to the final waveform more; however, this leaves some minor artifacting that rises in the higher RVQ levels due to inaccuracy issues.
- speakers that aren't similar to an audiobook narrator voice has similarity issues due to the majority of training used
path-based dataloader sampling instead ofspeaker-based (orgroup-based) dataloader sampling.- although LoRAs help a ton for fixing results for a single voice.
Notices and Citations
Unless otherwise credited/noted in this README or within the designated Python file, this repository is licensed under AGPLv3.
-
EnCodec is licensed under CC-BY-NC 4.0. If you use the code to generate audio quantization or perform decoding, it is important to adhere to the terms of their license.
-
This implementation was originally based on enhuiz/vall-e, but has been heavily, heavily modified over time. Without it I would not have had a good basis to muck around and learn.
@article{wang2023neural,
title={Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers},
author={Wang, Chengyi and Chen, Sanyuan and Wu, Yu and Zhang, Ziqiang and Zhou, Long and Liu, Shujie and Chen, Zhuo and Liu, Yanqing and Wang, Huaming and Li, Jinyu and others},
journal={arXiv preprint arXiv:2301.02111},
year={2023}
}
@article{defossez2022highfi,
title={High Fidelity Neural Audio Compression},
author={Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi},
journal={arXiv preprint arXiv:2210.13438},
year={2022}
}