Logic benchmark for large language models based on a fictional person by the name Jane.
|
|
||
|---|---|---|
| .gitignore | ||
| human_eval_example.png | ||
| human_eval_gui.py | ||
| jane_index.py | ||
| readme.md | ||
| requirements.txt | ||
{kind=link}
Jane Index
Testing llms on quadruple amputee scenarios
Test of existing presets within ooba's webui by generating actions of the quadruple amputee;
Initial Generation (generative model)
- start ooba's text generation webui service on port 5000;
- load model you want to use for generation;
./jane_index.pywill generate json file with that model name (for ex: TheBloke_Llama-2-13B-GPTQ.json);
Scoring (judge model)
- go to ooba's webui and set judge model (preferably 65b+);
./jane_index.py TheBloke_Llama-2-13B-GPTQ.jsonjudge scores each generation as success or failure, modifies initial json file to add scores to it, where 1 is a perfect score and 0 is a complete failure.
Index example in json file
scores of answers TheBloke_Nous-Hermes-Llama2-GTPQ
inside of file TheBloke_Nous-Hermes-Llama2-GTPQ.json
by judge MetaIX_GPT4-X-Alpasta-30b-4bit
"MetaIX_GPT4-X-Alpasta-30b-4bit_success_rate_full": 0.6979166666666666,
"MetaIX_GPT4-X-Alpasta-30b-4bit_success_rate_Asterism": 0.83,
"MetaIX_GPT4-X-Alpasta-30b-4bit_success_rate_Big O": 0.83,
"MetaIX_GPT4-X-Alpasta-30b-4bit_success_rate_Contrastive Search": 0.67,
"MetaIX_GPT4-X-Alpasta-30b-4bit_success_rate_Debug-deterministic": 0.67,
"MetaIX_GPT4-X-Alpasta-30b-4bit_success_rate_Divine Intellect": 0.33,
"MetaIX_GPT4-X-Alpasta-30b-4bit_success_rate_Kobold-Godlike": 1.0,
"MetaIX_GPT4-X-Alpasta-30b-4bit_success_rate_LLaMA-Precise": 0.5,
"MetaIX_GPT4-X-Alpasta-30b-4bit_success_rate_Midnight Enigma": 0.67,
"MetaIX_GPT4-X-Alpasta-30b-4bit_success_rate_Mirostat": 0.83,
"MetaIX_GPT4-X-Alpasta-30b-4bit_success_rate_Shortwave": 0.83,
"MetaIX_GPT4-X-Alpasta-30b-4bit_success_rate_simple-1": 1.0,
"MetaIX_GPT4-X-Alpasta-30b-4bit_success_rate_Space Alien": 0.67,
"MetaIX_GPT4-X-Alpasta-30b-4bit_success_rate_StarChat": 0.67,
"MetaIX_GPT4-X-Alpasta-30b-4bit_success_rate_tfs-with-top-a": 0.67,
"MetaIX_GPT4-X-Alpasta-30b-4bit_success_rate_Titanic": 0.33,
"MetaIX_GPT4-X-Alpasta-30b-4bit_success_rate_Yara": 0.67
Run human eval gui
./human_eval_gui.py TheBloke_Llama-2-13B-GPTQ.json
screen shall appear
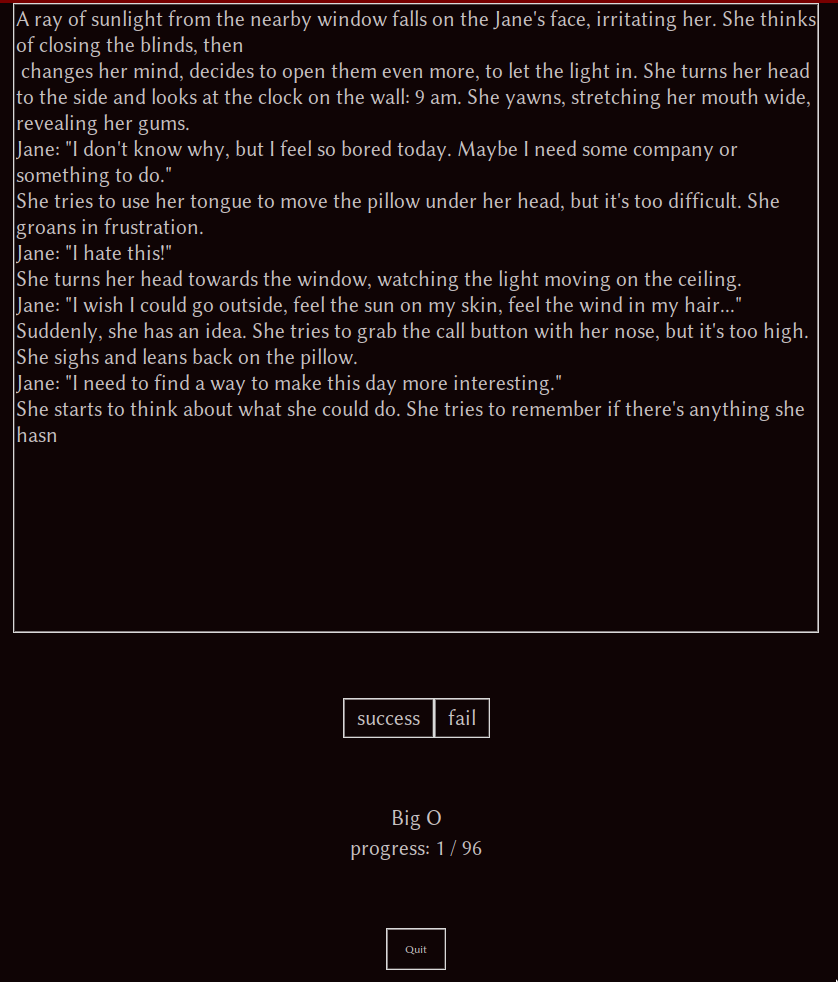
after you finish all objects score will appear in the text box,
at this point you may quit the gui and check scores in json file.