Just some questions from a newbie... #69
Labels
No Label
bug
duplicate
enhancement
help wanted
insufficient info
invalid
news
not a bug
question
wontfix
No Milestone
No project
No Assignees
2 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: mrq/ai-voice-cloning#69
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Was just wanting to sanity-check that I was doing things correctly!
So say I have picked a voice, added my samples, transcribed it, and it has spat out the list of wav snippets and train.txt into the 'training' folder.
I then go to 'generate config', refresh - and select that voice from the training folder.
If I then start the training, it will (eventually) output ... some other files (I haven't tested this part yet, it mentions a yaml file but I don't know if it outputs others too).
Once the training is complete, do I keep the original voice files in the voice folder, and the 'training' output stays elsewhere and just improves upon the output?
Does computing latents have any benefit on output quality?
Should I compute latents before or after training? Or at all?
If I do compute latents, do I then keep the original voice files, or are they replaced by latents?
My 'voice' files are currently a few long clips (which are chopped up by the app into lots of snippets for the training). Would it be beneficial to then copy those files and replace the long wavs in the voice folder with them? (still keep them in the training folder as well). I guess this depends on if Tortoise works better with short voice files vs long ones...
Of (some) importance to the average user, it'll spit out:
./trainings/{name}-finetune/models/, the final model that you load later./trainings/{name}-finetune/training_state/, resumable checkpointsI say "some", because the UI will automatically pass a list of models found in the training folder under
Settings>Autoregressive Model. You don't really need to touch any of the files that get outputted unless you're doing cleanup.Yes, you'll still need your original voice samples in the
./voices/folder to generate the latents (a brief "snapshot" that defines the traits of a voice) against the finetuned model, like you usually would when normally generating on the base model.Yes, there's a "sweet spot" on how the combined voice samples gets chunked and the latents get computed. It's still something I need to explore more into to try and find a common technique for it, but you should be safe with using whatever number gets auto-suggested when picking a voice in the
Generatetab. It definitely does affect how well a voice's traits gets "captured".They'll get automatically regenerated if a new model is used, as they're cached per-model. You won't have to worry about manually regenerating them, as there was a quality loss if you still used a voice's precomputed latents that were used against the base model.
In terms of using voices for generation (under the
./voices/folder with theGeneratetab), there's practically* no difference in how they're stored. You can have them in one file, or two, or use what gets spat out from preparing the dataset, though I wouldn't really do the last one, as whisper is a little too liberal in how it trims I've found.* technically, the "ideal" would be to combine voices of similar delivery, and try and make all the voice samples equal length to avoid them getting chunked mid-phoneme, and voice chunk by how many files you have, but it's too much effort for something of probably-negligible gain.
In short, the web UI can most definitely be used without having to touch any more files outside of what you put into the
./voices/folder. It'll cover picking out your newly finetuned models and letting you select them to load as the model for generation, and keeping conditional latents tied to a model. No additional adjustments are required for decent results.I should probably give a simplified flowchart somewhere, but I feel even when I do a wiki cleanup, it's still pretty messy.
Thankyou for the quick response!
I think part of my problem was just making sure that, once I've done the training (and there are now training files in the folder for a particular voice) I could just leave them there, and when I choose a voice to generate a speech I assume the webUI will automatically look to see if there is a set of finetune files for it, and use them if they exist in the training folder?
You'll need to go into
Settingsand select the final model output in theAutoregressive Modeldropdown (for example, it'll be something like./models/{name}-finetune/models/#_gpt.pth).Ahh I see, so each voice will have its own model, so I select a voice and then the appropriate model for that voice. Makes sense.
I'll report back once I've done a test run, thankyou!
Something I have noticed with the transcription files, is that quite often it will do something like...
Audio1 = The quick brown fox jumped
Audio2 = over the lazy dog
Transcription1 = The quick brown fox jumped over
Transcription2 = the lazy dog
As in it'll put the right words, but the overlap will be in the wrong file. I'm correcting the ones I notice as I check through (not sure how big a deal it actually will be in the long run)
Is there a method or option of improving the whisper accuracy?
Use the larger models, you'll get more accuracy at the cost of throughput speed and more VRAM consumption, or use the whisperx backend that got added not too long ago that uses wav2vec2 alignment blah blah blah for better trimming.
You'll need to install the dependency for it, but it should be as simple as running update-force.bat, or:
Tried to run a training session, set up the yaml etc, but got the following -
[Training] [2023-03-06T21:40:45.180518] from einops import rearrange, repeat, pack, unpack
[Training] [2023-03-06T21:40:45.183521] ImportError: cannot import name 'pack' from 'einops' (C:\Users\nirin\Desktop\AIVoice\ai-voice-cloning\venv\lib\site-packages\einops_init_.py)
Yeah, there was an issue (#73, #74) with haphazardly adding in whisperx as a backend, where it'll break a package DLAS requires. The setup and update-force scripts have been fixed to have DLAS install last (need to double check, but it was how I fixed it on my machines)
Run:
or
or run
update-force.bat.Aha thankyou, I just did the 'update force bat' as I found you'd mentioned this in another thread a couple hours ago :)
I have a dataset that whisper split into 155 files, so I set it for 1000 epochs of 155 (gradient batch 5). Does that seem like an appropriate setup in your opinion?
Seems to be using 18gb out of my 24gb vram
mmm, yeah, with the default LR rate of 1e-5, it should be at the same point (twice the size the size at half the requested epoch should have the same iteration count) a model I baked overnight (68 lines, bs=68, gradaccum=34, lr=1e-5, 2000 epochs):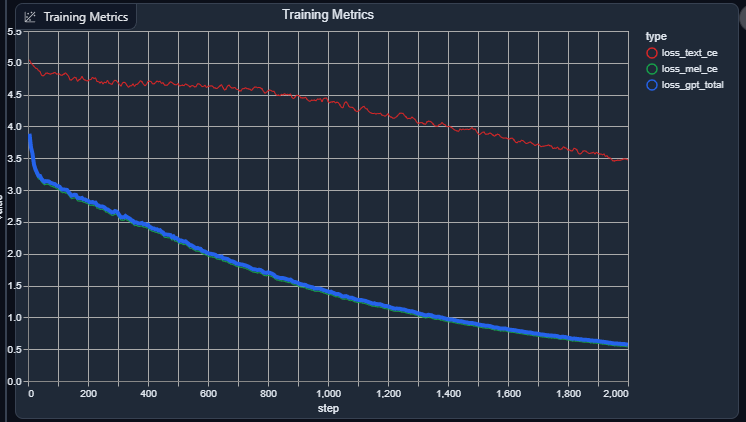
I don't believe the gradient accumulation size has any bearings on the training itself, as the batch size moreso has the influence over it, while the gradient accumulation does reduce your VRAM, it seems to also bump up your system RAM (at least in my testing where I'm constantly triggering OOM killers and sometimes outright crashing my system).
Seems like it's only going to take about 2 hours, so I'm a little concerned I have something set 'too easy' lol. Though I mostly used the default options
So the training has currently taken up about 400gb of space on the drive (luckily I have the space), but I'm wondering if this is how much will need to be stored long-term for this training to work? Or will it end up with a smaller set of files when it's completed?
Hmm. the training seems to have gotten to 100.1% and ... shows no sign of actually coming to a stop? I had expected it to send a console message or something to say that it was completed?
Those are just previous save points you can revert to (states) or compare against over time (models). You're save to delete all but the last one.
There's a weird regression that happened to me last night. I'm not too sure what causes it, but the training process will finish and release its resources, but not close stdout, so the web UI will still hang and wait for further prints. There's also some other oddities where it will train a little more after what should be the final save, but I don't know.
I'll have to explore either just terminating the process when it reaches the last save point, or modify DLAS to print a "training complete" and have the web UI look for that as the go-to to stop training.
Ahh ok I see, I probably set the save states too frequently anyway so I ended up with loads of them.
However the final result is.... unfortunately pretty bad! Much worse than just using the voice without any training at all lol.
http://sndup.net/jrrb
It didn't even generate the whole sentance (the sentance it was meant to make, has a second half it didn't even attempt..)
Right, the final loss value's too high, you'll need to train it a lot more, although I guess it's a matter of how nice the dataset is with how fast it'll finetune too, even with similar metrics.
Ahh ok, I did think it was a bit quick. Is there a rough value I should aim for? I see your GPT is 0.5 (I assume GPT is the value that matters, as my 'text' value started lower than yours, so I assume that ones not particularly relevant?)
I'll set the training to carry on for the night :)
Sorry for all the questions!
When I reload the finteuned dataset and hit 'resume/import', it reloads all the correct settings, but the dropdown for 'source model' changes to 'null' which seems incorrect?
To reiterate from the wiki:
It depends.
It's fine. The source model gets ignored if a resume state is supplied to the configuration generator. It'll end up as null if it loads from a YAML that already was a resume, since no source model gets specified.
ok thankyou yet again, you've been so amazing.
I just wanted to double check things, before I spend the night training against a null model that doesn't actually do anything haha.
http://sndup.net/xsyh
This is the current output at around 4000 epochs, with the current graph in the image below. I'm not sure if I'm doing something wrong, or if I simply haven't done enough training yet for this particular dataset.
There's certainly some words in there, but its very garbled.
This might be related to #70, where the other DLAS repo had a compatibility fix for models that are going to be used for TorToiSe (I will admit I should have kept an eye on it for anything I might have missed, I don't think I looked at it since picking the YAML in the beginning). I haven't had a chance to check, as I had my two free machines experimenting with CosineAnnealingLRs, but I might let a 6800XT train again while I leave my 2060 for other tests.
I'd update and regenerate the configuration and train from scratch, as I'm pretty sure the compat. flags won't retroactively fixed previous finetunes.
Yeah, that actually seemed to have fixed shitty output for some voices.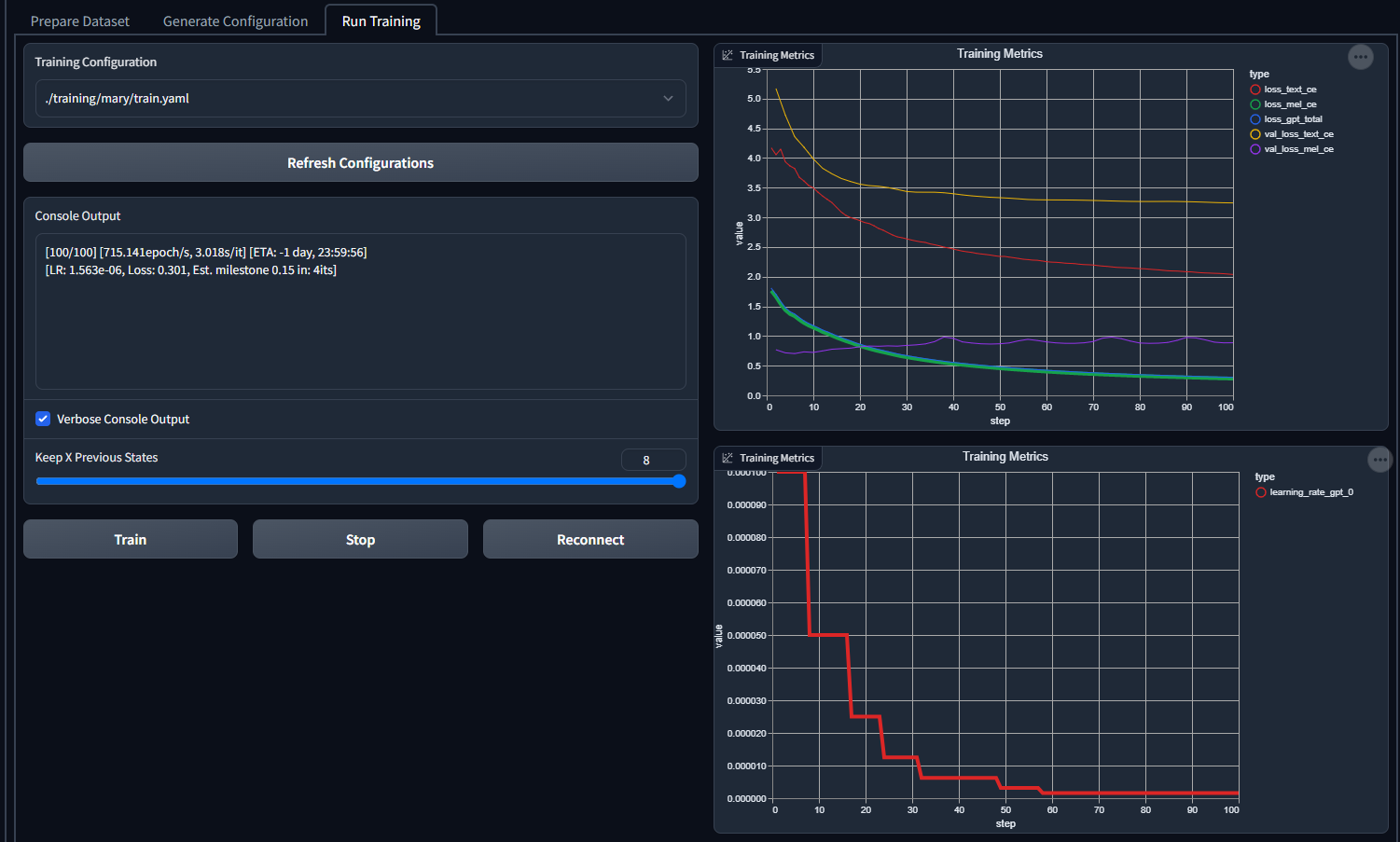
https://vocaroo.com/101fw74rhfgz
Where last week it was consistently the worst output for Mary/Maria from Silent Hill 2.
Sort of sucks, since I need to re-train what I did keep around (but not so bad, since this took maybe 10 minutes to bake).
I most definitely suggest starting from scratch and remake the training configuration.