Question, why does my model produce bad output? #70
Labels
No Label
bug
duplicate
enhancement
help wanted
insufficient info
invalid
news
not a bug
question
wontfix
No Milestone
No project
No Assignees
2 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: mrq/ai-voice-cloning#70
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
I trained a Louise Belcher model using the default settings. But the output files sound like they're underwater. What did I do wrong? Was it the train.txt file?
Here's a wav folder containing the train.txt file.
https://files.catbox.moe/4rakmk.zip
Model link.
https://pixeldrain.com/u/Rf86Wd7n
I'll poke around and check the outputs. desu, finetuned models seems to have an inherent slight loss in the output quality, unless it's trained very, very slowly and properly.
The things I can think of right now would be checking how the loss-graph looks. If you can send the
./training/{name}-finetune/tb_logger/folder, I should be able to load the training metrics and take a look at the curve.Or you can go under
Train>Run Training, select the dataset, clickView Losses, and take a screenshot of the graph.It took some wrestling, but this seems the best I'll get: https://vocaroo.com/1eoBNEHDf4Uy
It's unironically just the default settings with half-precision enabled for generating. I don't remember what I set the voice chunk size to for making the latents.
My first guess was that it was overtrained, but it can't be, as it does worse when trying to generate any lines from the dataset.
I can't make any strong guesses without the loss graph and the training settings (batch size namely). My guess instead would have to be that it's either not trained enough (too high of a loss rate) or trained too "fast" (too high of a loss rate, or one that didn't decay well, or something like constantly resuming, since the LR scheduler is a bit broken when resuming since it needs some time to "catch up").
I might see if I can get a paperspace instance up again and bake a model given the dataset. I had Mitsuru sounding serviceable at best with some lazy settings and some careless mistakes, so I should be able to get something decent overnight.
Here is a tb_logger folder
https://files.catbox.moe/kie3ak.zip
Will take a look when I get a chance.
I had to re-run the finetune on my paperspace instance since I woke up to it halted a small ways through. It looks like this right now so it seems promising: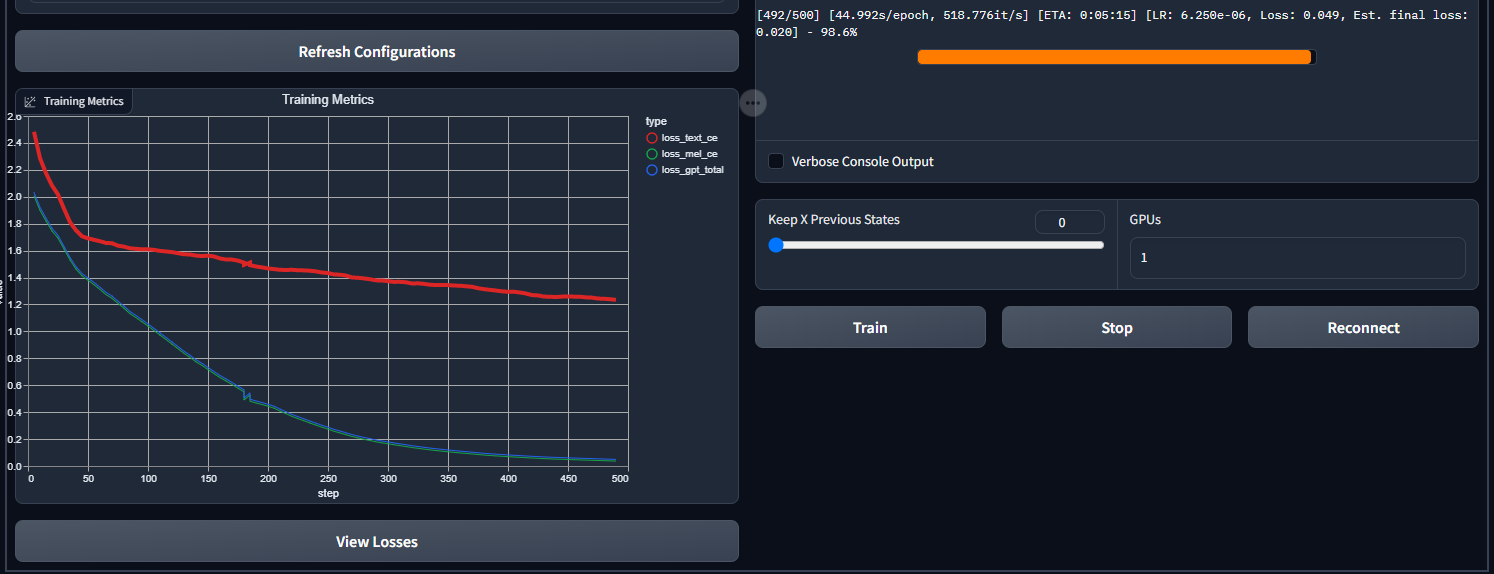
I suppose it has been overtrained and fried; the finetune I just finished still sounds terrible. I'm going to try and generate against older snapshots to see if I can find something sounding decent.
I think the crux is that female finetunes are just inherently less likely to turn out good. I've tried Mary/Maria from Silent Hill 2 and it sounds equally shitty. I'll see about finetuning at an even smaller learning rate, since the quality problem sort of feels indicative of it being a learning rate issue.
Another question, I made a dataset of Judy Hopps, and I get output files of british accents with both the finetune model and the stock autoregressive.pth file. Why is that?
Here is a link for the wav dataset with a train.txt file.
https://files.catbox.moe/u3s35n.zip
The finetune model
https://pixeldrain.com/u/sPKBpRQo
Edit: I created a louise belcher model with 152334H's DL-Art-School fork with the learning rate set to 1e-20. I'm not sure if it's because of the learning rate or if it's the implementation of bigvgan 24khz 100 band but now the output files no longer sound as if they're underwater.
https://pixeldrain.com/u/16WNp6eS
So that's the funny thing. That repo seemed to have implemented some tweaks to better suit TorToiSe's use-case. I added them yesterday in mrq/DL-Art-School commit
84c8196da5, but have not got around to checking if it actually helps.Seeing it worked for you on the other DLAS repo, I'm more inclined to guess it's been that the entire time.