5.8 KiB
Executable File
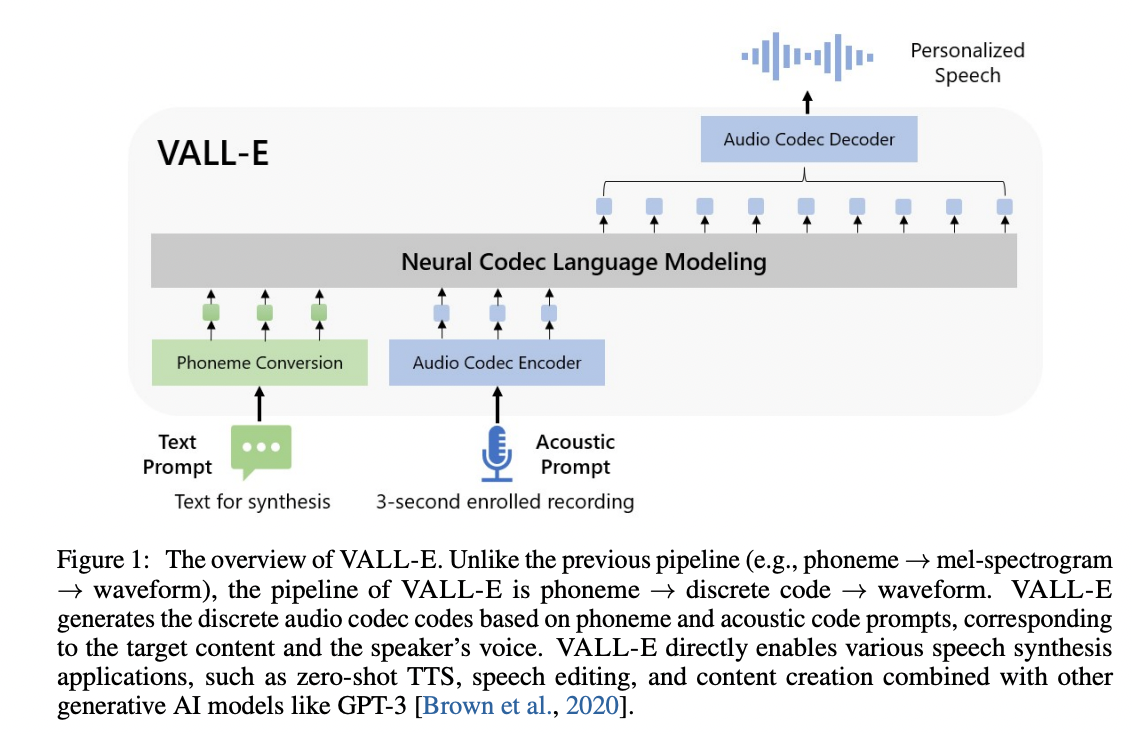
VALL'Ecker
An unofficial PyTorch implementation of VALL-E, based on the EnCodec tokenizer.
Note this is highly experimental. While I've seem to have audited and tighened down as much as I can, I'm still trying to produce a decent model out of it. You're free to train your own model if you happen to have the massive compute for it, but it's quite the beast to properly feed. This README won't get much love until I truly nail out a quasi-decent model.
Note Distributed training seems broken? I'm not really sure how to test it, as my two 6800XTs have been redistributed for now, and the last time I tried using them for this, things weren't good.
Note You can follow along with my pseudo-blog in an issue here. I currently have a dataset clocking in at 3400+ trimmed hours.
Requirements
If your config YAML has the training backend set to deepspeed, you will need to have a GPU that DeepSpeed has developed and tested against, as well as a CUDA or ROCm compiler pre-installed to install this package.
Install
pip install git+https://git.ecker.tech/mrq/vall-e
Or you may clone by:
git clone --recurse-submodules https://git.ecker.tech/mrq/vall-e.git
Note that the code is only tested under Python 3.10.9.
Try Me
To quickly try it out, you can choose between the following modes:
- AR only:
python -m vall_e.models.ar yaml="./data/config.yaml" - NAR only:
python -m vall_e.models.nar yaml="./data/config.yaml" - AR+NAR:
python -m vall_e.models.base yaml="./data/config.yaml"
Each model file has a barebones trainer and inference routine.
Train
Training is very dependent on:
- the quality of your dataset.
- how much data you have.
- the bandwidth you quantized your audio to.
Leverage Your Own
-
Put your data into a folder, e.g.
./data/custom. Audio files should be named with the suffix.wavand text files with.txt. -
Quantize the data:
python -m vall_e.emb.qnt ./data/custom
- Generate phonemes based on the text:
python -m vall_e.emb.g2p ./data/custom
- Customize your configuration and define the dataset by modifying
./data/config.yml. Refer to./vall_e/config.pyfor details. If you want to choose between different model presets, check./vall_e/models/__init__.py.
If you're interested in creating an HDF5 copy of your dataset, simply invoke:
python -m vall_e.data yaml='./data/config.yaml'
- Train the AR and NAR models using the following scripts:
python -m vall_e.train yaml=./data/config.yml
You may quit your training any time by just typing quit in your CLI. The latest checkpoint will be automatically saved.
Dataset Formats
Two dataset formats are supported:
- the standard way:
- data is stored under
${speaker}/${id}.phn.txtand${speaker}/${id}.qnt.pt
- data is stored under
- using an HDF5 dataset:
- you can convert from the standard way with the following command:
python3 -m vall_e.data yaml="./path/to/your/config.yaml" - this will shove everything into a single HDF5 file and store some metadata alongside (for now, the symbol map generated, and text/audio lengths)
- be sure to also define
use_hdf5in your config YAML.
- you can convert from the standard way with the following command:
Training Tip
Training a VALL-E model is very, very meticulous. I've fiddled with a lot of """clever""" tricks, but it seems the best is just to pick the highest LR you can get (this heavily depends on your batch size, but hyperparameters of bs=64 * ga=16 on the quarter sized model has an LR of 1.0e-3 stable, while the full size model with hyperparameters of bs=16 * ga=64 needed smaller). Like typical training, it entirely depends on your tradeoff betweeen stability and time.
Export
Both trained models can be exported, but is only required if loading them on systems without DeepSpeed for inferencing (Windows systems). To export the models, run:
python -m vall_e.export ./models/ yaml=./config/custom.yml
This will export the latest checkpoint.
Synthesis
To synthesize speech, invoke either (if exported the models):
python -m vall_e <text> <ref_path> <out_path> --ar-ckpt ./models/ar.pt --nar-ckpt ./models/nar.pt
or:
python -m vall_e <text> <ref_path> <out_path> yaml=<yaml_path>
Some additional flags you can pass are:
--max-ar-steps: maximum steps for inferencing through the AR model. Each second is 75 steps.--ar-temp: sampling temperature to use for the AR pass.--nar-temp: sampling temperature to use for the NAR pass.--device: device to use (default:cuda, examples:cuda:0,cuda:1,cpu)
Notice
- EnCodec is licensed under CC-BY-NC 4.0. If you use the code to generate audio quantization or perform decoding, it is important to adhere to the terms of their license.
Unless otherwise credited/noted, this repository is licensed under AGPLv3.
Citations
@article{wang2023neural,
title={Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers},
author={Wang, Chengyi and Chen, Sanyuan and Wu, Yu and Zhang, Ziqiang and Zhou, Long and Liu, Shujie and Chen, Zhuo and Liu, Yanqing and Wang, Huaming and Li, Jinyu and others},
journal={arXiv preprint arXiv:2301.02111},
year={2023}
}
@article{defossez2022highfi,
title={High Fidelity Neural Audio Compression},
author={Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi},
journal={arXiv preprint arXiv:2210.13438},
year={2022}
}